1 4.3 앙상블 학습 개요
1.0.1 Voting Classifier
위스콘신 유방암 데이터 로드
import pandas as pd
from sklearn.ensemble import VotingClassifier # 보팅 분류기
from sklearn.linear_model import LogisticRegression # 이진 분류기
from sklearn.neighbors import KNeighborsClassifier # KNN 분류기
from sklearn.datasets import load_breast_cancer # 데이터 불러오기
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 워닝 무시
import warnings
warnings.filterwarnings('ignore')
# 유방암 데이터 로드
cancer = load_breast_cancer()
# 데이터 확인
data_df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
print(data_df.shape)
data_df.head()
(569, 30)
1.0.2 VotingClassifier로 로지스틱 회귀와 KNN을 보팅 방식으로 결합하고 단일 모델과 성능을 비교해보자
# 개별 모델은 로지스틱 회귀와 KNN 임.
lr_clf = LogisticRegression()
knn_clf = KNeighborsClassifier(n_neighbors=8)
# 개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현한 분류기
vo_clf = VotingClassifier( estimators=[('LR', lr_clf),('KNN', knn_clf)] , voting='soft')
vo_clf
>>>
VotingClassifier(estimators=[('LR', LogisticRegression()),
('KNN', KNeighborsClassifier(n_neighbors=8))],
voting='soft')
# VotingClassifier 학습/예측/평가.
vo_clf.fit(X_train , y_train)
pred = vo_clf.predict(X_test)
print('Voting 분류기 정확도: {0:.4f}'.format(accuracy_score(y_test , pred)))
>>> Voting 분류기 정확도: 0.9474
# 개별 모델의 학습/예측/평가.
classifiers = [lr_clf, knn_clf]
for classifier in classifiers:
classifier.fit(X_train , y_train)
pred = classifier.predict(X_test)
class_name= classifier.__class__.__name__
print('{0} 정확도: {1:.4f}'.format(class_name, accuracy_score(y_test , pred)))
>>> LogisticRegression 정확도: 0.9386
KNeighborsClassifier 정확도: 0.9386
-> VotingClassifier로 모델들을 합친 앙상블 모델의 정확도가 개별 모델보다 더 높게 나왔다.
2 4.4 Random Forest
결정 트리에서 사용한 사용자 행동 인지 데이터 세트 로딩
2.0.1 수정 버전 01: 날짜 2019.10.27일
원본 데이터에 중복된 Feature 명으로 인하여 신규 버전의 Pandas에서 Duplicate name 에러를 발생.
중복 feature명에 대해서 원본 feature 명에 '_1(또는2)'를 추가로 부여하는 함수인 get_new_feature_name_df() 생성
import pandas as pd
# 중복 feature명에 대해서 원본 feature 명에 '_1(또는2)'를 추가로 부여하는 함수
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data=old_feature_name_df.groupby('column_name').cumcount(), columns=['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(), feature_dup_df, how='outer')
new_feature_name_df['column_name'] = new_feature_name_df[['column_name', 'dup_cnt']].apply(lambda x : x[0]+'_'+str(x[1])
if x[1] >0 else x[0] , axis=1)
new_feature_name_df = new_feature_name_df.drop(['index'], axis=1)
return new_feature_name_df
import pandas as pd
# train, test 데이터 분리해주는 함수
def get_human_dataset( ):
# 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당.
feature_name_df = pd.read_csv("C:/Users/JIN SEONG EUN/OneDrive/바탕 화면/빅데이터 분석가 과정/머신러닝/실강/CH04/UCI HAR Dataset/features.txt",sep='\s+',
header=None,names=['column_index','column_name'])
# 중복된 feature명을 새롭게 수정하는 get_new_feature_name_df()를 이용하여 새로운 feature명 DataFrame생성.
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 컬럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터 셋과 테스트 피처 데이터을 DataFrame으로 로딩. 컬럼명은 feature_name 적용
X_train = pd.read_csv("./UCI HAR Dataset/train/X_train.txt",sep='\s+', names=feature_name )
X_test = pd.read_csv('./UCI HAR Dataset/test/X_test.txt',sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터을 DataFrame으로 로딩하고 컬럼명은 action으로 부여
y_train = pd.read_csv('./UCI HAR Dataset/train/y_train.txt',sep='\s+',header=None,names=['action'])
y_test = pd.read_csv('./UCI HAR Dataset/test/y_test.txt',sep='\s+',header=None,names=['action'])
# 로드된 학습/테스트용 DataFrame을 모두 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset()
2.0.2 학습/테스트 데이터로 분리하고 랜덤 포레스트로 학습/예측/평가
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
# 워닝 무시
import warnings
warnings.filterwarnings('ignore')
# get_human_dataset( )을 이용해 train, test 데이터 분리
X_train, X_test, y_train, y_test = get_human_dataset()
# 랜덤 포레스트 학습 및 별도의 테스트 셋으로 예측 성능 평가
rf_clf = RandomForestClassifier(random_state=0, max_depth=10)
# (default) min_samples_leaf=1, min_samples_split=2
rf_clf.fit(X_train , y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test , pred)
print('랜덤 포레스트 정확도: {0:.4f}'.format(accuracy))
>>> 랜덤 포레스트 정확도: 0.9230
%%time
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [1, 8, 12, 18],
'min_samples_split' : [2, 8, 16, 20]
}
# RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1) # n_jobs=-1 : 컴퓨터의 모든 코어를 다 사용해라
# https://aimb.tistory.com/150
# 그리드서치 수행
# # n_jobs=-1 : 전체 cpu core를 사용해라.
grid_cv = GridSearchCV(rf_clf , param_grid=params , cv=2, n_jobs=-1)
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))
>>>
최적 하이퍼 파라미터:
{'max_depth': 10, 'min_samples_leaf': 8, 'min_samples_split': 2, 'n_estimators': 100}
최고 예측 정확도: 0.9180
CPU times: total: 14 s
Wall time: 1min 23s
<n_jobs값 변화에 따른 수행시간 비교> - rf_clf & grid_cv 같은 n_jobs값
# mac 2.6 GHz 6코어 Intel Core i7
rf_clf grid_cv
n_jobs= 1 & 1 -> 3min 11s
n_jobs= 2 & 2 -> 59s
n_jobs= 3 & 3 -> 37s
n_jobs= 4 & 4 -> 32s
n_jobs= 5 & 5 -> 32s
n_jobs= 6 & 6 -> 28s
∗ n_jobs=-1 : 컴퓨터의 모든 코어를 다 사용한다는 뜻.
2.0.4 튜닝된 하이퍼 파라미터로 랜덤포레스트 재학습/예측/평가
# n_estimators(결정 트리 개수)는 300으로 늘린다.
rf_clf1 = RandomForestClassifier(n_estimators=300, max_depth=10, min_samples_leaf=8, \
min_samples_split=2, random_state=0)
rf_clf1.fit(X_train , y_train)
pred = rf_clf1.predict(X_test)
print('예측 정확도: {0:.4f}'.format(accuracy_score(y_test , pred)))
>>> 예측 정확도: 0.9165-> 랜덤포레스트의 정확도는 0.9165
2.0.5 개별 feature들의 중요도 시각화
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
ftr_importances_values = rf_clf1.feature_importances_
ftr_importances = pd.Series(ftr_importances_values, index=X_train.columns )
# 중요도가 높은 20개의 피처들만 확인
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Feature importances Top 20')
sns.barplot(x=ftr_top20 , y = ftr_top20.index)
plt.show()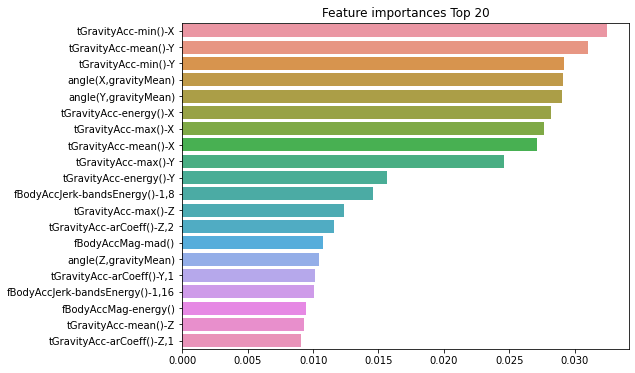
2.1 4.5 GBM(Gradient Boosting Machine)
# 수행시간 약 8분
from sklearn.ensemble import GradientBoostingClassifier
import time
# 워닝 무시
import warnings
warnings.filterwarnings('ignore')
# train, test 데이터 분리
X_train, X_test, y_train, y_test = get_human_dataset()
# GBM 수행 시간 측정을 위함. 시작 시간 설정.
start_time = time.time()
# GBM 클래스 객체 생성
gb_clf = GradientBoostingClassifier(random_state=0) # n_estimators = 100(default)
# 학습
gb_clf.fit(X_train , y_train)
# 예측
gb_pred = gb_clf.predict(X_test)
# 평가
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
print("GBM 수행 시간: {0:.1f} 초 ".format(time.time() - start_time)) # 약 8분
>>> GBM 정확도: 0.9389
GBM 수행 시간: 660.0 초-> GBM의 단점 : 수행시간이 오래 걸려서 하이퍼 파라미터 튜닝이 어렵다.
# 수행시간 - n_jobs defalut :
# n_jobs=-1 : 약
# 그리드서치 수행
from sklearn.model_selection import GridSearchCV
start_time = time.time()
params = {
'n_estimators':[100, 500],
'learning_rate' : [0.05, 0.1]
}
grid_cv = GridSearchCV(gb_clf , param_grid=params , cv=2 ,verbose=1, n_jobs=-1)
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))
print("학습에 걸린 시간: ".format(time.time() - start_time))
# 그리드서치 결과 보기
scores_df = pd.DataFrame(grid_cv.cv_results_)
scores_df[['params', 'mean_test_score', 'rank_test_score',
'split0_test_score', 'split1_test_score']]
# GridSearchCV를 이용하여 최적으로 학습된 estimator로 predict 수행.
gb_pred = grid_cv.best_estimator_.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
>>> GBM 정확도: 0.9406-> GBM의 정확도는 0.9406 로 랜덤포레스트의 0.9165보다 높게 나왔다.
'Machine Learning > 머신러닝 완벽가이드 for Python' 카테고리의 다른 글
| ch.4.6.1 XGBoost(eXtra Gradient Boost)(실습) (0) | 2022.10.11 |
|---|---|
| ch.4.6 XGBoost (0) | 2022.10.11 |
| ch. 4.5 앙상블-부스팅 (0) | 2022.10.11 |
| ch.4.4 앙상블 - 배깅 (1) | 2022.10.06 |
| ch.4.3 앙상블 - 보팅 (1) | 2022.10.06 |



