XGBoost
LightGBM
GridsearchCV으로 하이퍼 파라미터 튜닝을 통해서 성능을 올리는 것보다는,
차라리 ★피처 엔지니어링 하는 것이 성능 향상에 더 중요할 때가 많다. 이상치 제거, 표준화 등 중요
0.0.1 데이터 전처리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
1 1. 데이터 확인
cust_df = pd.read_csv("./train_santander.csv", encoding='latin-1') # utf-8-sig를 사용하면 한글이 안깨진다.
print('dataset shape:', cust_df.shape)
cust_df.head(5)
>>> dataset shape: (76020, 371)
cust_df.info()
>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 76020 entries, 0 to 76019
Columns: 371 entries, ID to TARGET
dtypes: float64(111), int64(260)
memory usage: 215.2 MB
2 2. 데이터 전처리
# 만족:0, 불만족:1
print(cust_df['TARGET'].value_counts())
>>> 0 73012
1 3008
Name: TARGET, dtype: int64
# 전체 응답 중 불만족 비율
total_cnt = cust_df['TARGET'].count()
unsatisfied_cnt = cust_df[cust_df['TARGET'] == 1]['TARGET'].count()
print('unsatisfied 비율은 {0:.2f}'.format((unsatisfied_cnt / total_cnt)))
>>> unsatisfied 비율은 0.04
cust_df.describe( )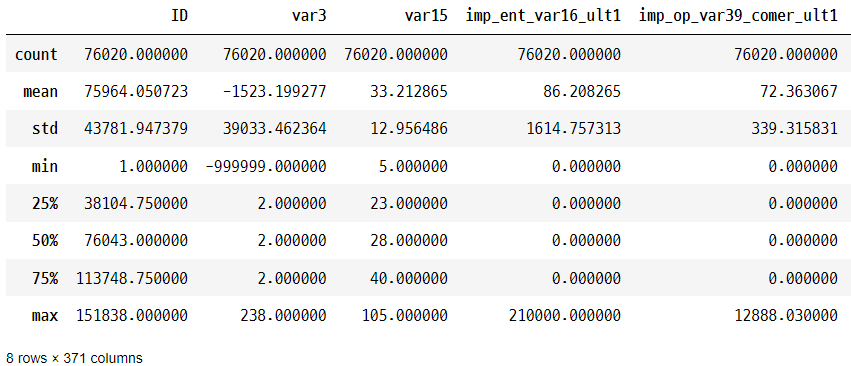
-> var3 값들의 분포는 뭔가 이상하다.
print(cust_df['var3'].value_counts( )[:10])
>>>
2 74165
8 138
-999999 116
9 110
3 108
1 105
13 98
7 97
4 86
12 85
Name: var3, dtype: int64
-> -999999의 값들은 가장 많은 2로 대체한다.
# var3 피처 값 대체
cust_df['var3'].replace(-999999, 2, inplace=True)
# ID는 필요 없으므로 drop
cust_df.drop('ID', axis=1, inplace=True)
# features, target 분리
X_features = cust_df.iloc[:, :-1]
y_labels = cust_df.iloc[:, -1]
print('피처 데이터 shape:{0}'.format(X_features.shape))
>>> 피처 데이터 shape:(76020, 369)
from sklearn.model_selection import train_test_split
# train, test 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X_features, y_labels,
test_size=0.2, random_state=0, stratify=y_labels)
# 잘 분리되었는지 분포 확인
train_cnt = y_train.count()
test_cnt = y_test.count()
print('학습 세트 Shape:{0}, 테스트 세트 Shape:{1}'.format(X_train.shape, X_test.shape), '\n')
print(' 학습 세트 레이블 값 분포 비율')
print(y_train.value_counts()/train_cnt)
print('\n 테스트 세트 레이블 값 분포 비율')
print(y_test.value_counts()/test_cnt)
>>>
학습 세트 Shape:(60816, 369), 테스트 세트 Shape:(15204, 369)
학습 세트 레이블 값 분포 비율
0 0.960438
1 0.039562
Name: TARGET, dtype: float64
테스트 세트 레이블 값 분포 비율
0 0.960405
1 0.039595
Name: TARGET, dtype: float64
-> 어느 정도 train, test 데이터 각각 레이블 값 분포 비율이 비슷하게 쪼개졌다.
3 3. xgboost 학습
from xgboost import XGBClassifier
from sklearn.metrics import roc_auc_score
# XGBClassifier 객체 생성
xgb_clf = XGBClassifier(n_estimators=100, random_state=156)
# 학습 : 성능 평가 지표를 auc로 설정하고 학습 수행.
xgb_clf.fit(X_train, y_train, early_stopping_rounds=30,
# 원래 검증 셋은 test 말고 다른 데이터 셋으로 해야하지만 여기서는 그냥 test 셋으로 진행함
eval_metric="auc", eval_set=[(X_train, y_train), (X_test, y_test)])
[0] validation_0-auc:0.82570 validation_1-auc:0.79283
[1] validation_0-auc:0.84010 validation_1-auc:0.80737
[2] validation_0-auc:0.84361 validation_1-auc:0.81021
[3] validation_0-auc:0.84783 validation_1-auc:0.81287
[4] validation_0-auc:0.85123 validation_1-auc:0.81469
[5] validation_0-auc:0.85518 validation_1-auc:0.81860
[6] validation_0-auc:0.85922 validation_1-auc:0.81977
[7] validation_0-auc:0.86238 validation_1-auc:0.82034
[8] validation_0-auc:0.86570 validation_1-auc:0.82147
[9] validation_0-auc:0.86798 validation_1-auc:0.82301
[10] validation_0-auc:0.87104 validation_1-auc:0.82379
[11] validation_0-auc:0.87448 validation_1-auc:0.82456
[12] validation_0-auc:0.87687 validation_1-auc:0.82401
[13] validation_0-auc:0.87918 validation_1-auc:0.82467
[14] validation_0-auc:0.88081 validation_1-auc:0.82508
[15] validation_0-auc:0.88331 validation_1-auc:0.82379
[16] validation_0-auc:0.88569 validation_1-auc:0.82457
[17] validation_0-auc:0.88674 validation_1-auc:0.82453
[18] validation_0-auc:0.88885 validation_1-auc:0.82354
[19] validation_0-auc:0.89038 validation_1-auc:0.82328
[20] validation_0-auc:0.89090 validation_1-auc:0.82305
[21] validation_0-auc:0.89327 validation_1-auc:0.82305
[22] validation_0-auc:0.89397 validation_1-auc:0.82287
[23] validation_0-auc:0.89712 validation_1-auc:0.82256
[24] validation_0-auc:0.89745 validation_1-auc:0.82237
[25] validation_0-auc:0.89779 validation_1-auc:0.82237
[26] validation_0-auc:0.89844 validation_1-auc:0.82248
[27] validation_0-auc:0.89912 validation_1-auc:0.82199
[28] validation_0-auc:0.89987 validation_1-auc:0.82157
[29] validation_0-auc:0.90071 validation_1-auc:0.82106
[30] validation_0-auc:0.90210 validation_1-auc:0.82075
[31] validation_0-auc:0.90433 validation_1-auc:0.82011
[32] validation_0-auc:0.90495 validation_1-auc:0.82001
[33] validation_0-auc:0.90548 validation_1-auc:0.82032
[34] validation_0-auc:0.90610 validation_1-auc:0.81969
[35] validation_0-auc:0.90661 validation_1-auc:0.81968
[36] validation_0-auc:0.90682 validation_1-auc:0.81939
[37] validation_0-auc:0.90842 validation_1-auc:0.81969
[38] validation_0-auc:0.90869 validation_1-auc:0.81962
[39] validation_0-auc:0.90888 validation_1-auc:0.81957
[40] validation_0-auc:0.91045 validation_1-auc:0.81893
[41] validation_0-auc:0.91171 validation_1-auc:0.81869
[42] validation_0-auc:0.91239 validation_1-auc:0.81802
[43] validation_0-auc:0.91329 validation_1-auc:0.81773
[44] validation_0-auc:0.91353 validation_1-auc:0.81771
XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,
early_stopping_rounds=None, enable_categorical=False,
eval_metric=None, gamma=0, gpu_id=-1, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.300000012, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=6, max_leaves=0, min_child_weight=1,
missing=nan, monotone_constraints='()', n_estimators=100,
n_jobs=0, num_parallel_tree=1, predictor='auto', random_state=156,
reg_alpha=0, reg_lambda=1, ...)
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:,1], average='macro')
print('ROC AUC: {0:.4f}'.format(xgb_roc_score))
>>> ROC AUC: 0.8251
4 4. GridSearchCV 적용 후 xgboost 학습
%%time
from sklearn.model_selection import GridSearchCV
# 하이퍼 파라미터 테스트의 수행 속도를 향상시키기 위해 n_estimators를 100으로 감소
xgb_clf = XGBClassifier(n_estimators=100)
# colsample_bytree : 컬럼이 너무 많으니 일부 비율로 해서 과적합을 조정하겠다.
# min_child_weight : 트리에서 가지를 추가로 치기 위해 필요한 최소 샘플 수.(> 0)
params = {'max_depth':[5, 7] , 'min_child_weight':[1, 3] , 'colsample_bytree':[0.5, 0.75] }
# 하이퍼 파라미터 테스트의 수행속도를 향상 시키기 위해 cv는 2로 부여함
gridcv = GridSearchCV(xgb_clf, param_grid=params, cv=2)
gridcv.fit(X_train, y_train, early_stopping_rounds=30, eval_metric="auc",
eval_set=[(X_train, y_train), (X_test, y_test)])
print('GridSearchCV 최적 파라미터:', gridcv.best_params_)
xgb_roc_score = roc_auc_score(y_test, gridcv.predict_proba(X_test)[:,1], average='macro')
print('ROC AUC: {0:.4f}'.format(xgb_roc_score))
>>>>
GridSearchCV 최적 파라미터: {'colsample_bytree': 0.5, 'max_depth': 5, 'min_child_weight': 3}
ROC AUC: 0.8237
CPU times: total: 3min 24s
Wall time: 1min 40s
-> 교차검증을 해도 안 했을 때와 크게 차이는 없다
4.0.1 하이퍼 파라미터 튜닝을 통해서 성능을 올리는 것보다는,
4.0.2 차라리 ★ 피처 엔지니어링 하는 것이 성능 향상에 더 중요할 때가 많다. 이상치 제거, 표준정규화
5 시도 : n_estimators는 1000으로 증가, learning_rate=0.02로 감소, reg_alpha=0.03으로 추가
%%time
# 수행시간 1분
# 새로운 하이퍼 파라미터 적용된 XGBClassifier 객체 생성
xgb_clf = XGBClassifier(n_estimators=1000, random_state=156, learning_rate=0.02, max_depth=5,
min_child_weight=1, colsample_bytree=0.75, reg_alpha=0.03)
# reg_alpha : 규제 관련
# 인자 소개 참고 : http://okminseok.blogspot.com/2017/09/ml-xgboost.html
# 학습
xgb_clf.fit(X_train, y_train, early_stopping_rounds=200,
eval_metric="auc", eval_set=[(X_train, y_train), (X_test, y_test)])
# 평가(roc auc)
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:,1])
print('ROC AUC: {0:.4f}'.format(xgb_roc_score))ROC AUC: 0.8271
CPU times: total: 3min 47s
Wall time: 1min 15s
# 직전 모델에 max_depth만 7로 변경
xgb_clf = XGBClassifier(n_estimators=1000, random_state=156, learning_rate=0.02, max_depth=7,\
min_child_weight=1, colsample_bytree=0.75, reg_alpha=0.03)
# evaluation metric을 auc로, early stopping은 200 으로 설정하고 학습 수행.
xgb_clf.fit(X_train, y_train, early_stopping_rounds=200,
eval_metric="auc", eval_set=[(X_train, y_train), (X_test, y_test)])
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:,1],average='macro')
print('ROC AUC: {0:.4f}'.format(xgb_roc_score))
>>> ROC AUC: 0.8269
from xgboost import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(1,1,figsize=(10,8))
plot_importance(xgb_clf, ax=ax , max_num_features=20,height=0.4)
F score : 트리를 split하는데 얼마나 자주 사용되는지 나타내는 계수
-> 피처 이름이 나오는 이유는 xgb_clf.fit(x_train) 판다스 데이터프레임이 인자로 들어갔기 때문이다.
6 LightGBM 모델 학습과 하이퍼 파라미터 튜닝
pip install lightgbm
import lightgbm
,
from lightgbm import LGBMClassifier
# LGBMClassifier 객체 생성
lgbm_clf = LGBMClassifier(n_estimators=500)
# 검증 데이터 지정
evals = [(X_test, y_test)]
# 학습
lgbm_clf.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="auc", eval_set=evals,
verbose=True)
# 평가(roc auc)
lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:,1],average='macro')
print('ROC AUC: {0:.4f}'.format(lgbm_roc_score))[1] valid_0's auc: 0.795963 valid_0's binary_logloss: 0.159288
[2] valid_0's auc: 0.801789 valid_0's binary_logloss: 0.155038
[3] valid_0's auc: 0.803367 valid_0's binary_logloss: 0.15185
[4] valid_0's auc: 0.805168 valid_0's binary_logloss: 0.14961
[5] valid_0's auc: 0.809401 valid_0's binary_logloss: 0.147695
[6] valid_0's auc: 0.810671 valid_0's binary_logloss: 0.146234
[7] valid_0's auc: 0.815356 valid_0's binary_logloss: 0.144877
[8] valid_0's auc: 0.816777 valid_0's binary_logloss: 0.143783
[9] valid_0's auc: 0.817821 valid_0's binary_logloss: 0.143084
[10] valid_0's auc: 0.818637 valid_0's binary_logloss: 0.142272
[11] valid_0's auc: 0.81939 valid_0's binary_logloss: 0.141623
[12] valid_0's auc: 0.821106 valid_0's binary_logloss: 0.141043
[13] valid_0's auc: 0.822008 valid_0's binary_logloss: 0.140628
[14] valid_0's auc: 0.822584 valid_0's binary_logloss: 0.140198
[15] valid_0's auc: 0.822291 valid_0's binary_logloss: 0.139909
[16] valid_0's auc: 0.821862 valid_0's binary_logloss: 0.13967
[17] valid_0's auc: 0.822242 valid_0's binary_logloss: 0.139418
[18] valid_0's auc: 0.821997 valid_0's binary_logloss: 0.139196
[19] valid_0's auc: 0.821995 valid_0's binary_logloss: 0.139074
[20] valid_0's auc: 0.821819 valid_0's binary_logloss: 0.138961
[21] valid_0's auc: 0.82203 valid_0's binary_logloss: 0.138881
[22] valid_0's auc: 0.82178 valid_0's binary_logloss: 0.138831
[23] valid_0's auc: 0.82121 valid_0's binary_logloss: 0.138769
[24] valid_0's auc: 0.821765 valid_0's binary_logloss: 0.138673
[25] valid_0's auc: 0.822462 valid_0's binary_logloss: 0.138592
[26] valid_0's auc: 0.822608 valid_0's binary_logloss: 0.138429
[27] valid_0's auc: 0.823151 valid_0's binary_logloss: 0.138356
[28] valid_0's auc: 0.822983 valid_0's binary_logloss: 0.138295
[29] valid_0's auc: 0.822815 valid_0's binary_logloss: 0.138256
[30] valid_0's auc: 0.8224 valid_0's binary_logloss: 0.138291
[31] valid_0's auc: 0.822417 valid_0's binary_logloss: 0.138282
[32] valid_0's auc: 0.822743 valid_0's binary_logloss: 0.138242
[33] valid_0's auc: 0.822874 valid_0's binary_logloss: 0.138243
[34] valid_0's auc: 0.82294 valid_0's binary_logloss: 0.138245
[35] valid_0's auc: 0.822962 valid_0's binary_logloss: 0.138245
[36] valid_0's auc: 0.82295 valid_0's binary_logloss: 0.138258
[37] valid_0's auc: 0.823193 valid_0's binary_logloss: 0.138293
[38] valid_0's auc: 0.82352 valid_0's binary_logloss: 0.138206
[39] valid_0's auc: 0.823274 valid_0's binary_logloss: 0.138248
[40] valid_0's auc: 0.823622 valid_0's binary_logloss: 0.138203
[41] valid_0's auc: 0.823716 valid_0's binary_logloss: 0.1382
[42] valid_0's auc: 0.823582 valid_0's binary_logloss: 0.138227
[43] valid_0's auc: 0.823891 valid_0's binary_logloss: 0.138182
[44] valid_0's auc: 0.823821 valid_0's binary_logloss: 0.138205
[45] valid_0's auc: 0.823827 valid_0's binary_logloss: 0.138218
[46] valid_0's auc: 0.82363 valid_0's binary_logloss: 0.138281
[47] valid_0's auc: 0.823169 valid_0's binary_logloss: 0.138356
[48] valid_0's auc: 0.822579 valid_0's binary_logloss: 0.138486
[49] valid_0's auc: 0.822526 valid_0's binary_logloss: 0.138442
[50] valid_0's auc: 0.822413 valid_0's binary_logloss: 0.138447
[51] valid_0's auc: 0.822634 valid_0's binary_logloss: 0.138443
[52] valid_0's auc: 0.822593 valid_0's binary_logloss: 0.138458
[53] valid_0's auc: 0.822446 valid_0's binary_logloss: 0.138513
[54] valid_0's auc: 0.82236 valid_0's binary_logloss: 0.138534
[55] valid_0's auc: 0.822185 valid_0's binary_logloss: 0.138537
[56] valid_0's auc: 0.821939 valid_0's binary_logloss: 0.138539
[57] valid_0's auc: 0.821903 valid_0's binary_logloss: 0.138537
[58] valid_0's auc: 0.821741 valid_0's binary_logloss: 0.13857
[59] valid_0's auc: 0.821511 valid_0's binary_logloss: 0.138621
[60] valid_0's auc: 0.821386 valid_0's binary_logloss: 0.138661
[61] valid_0's auc: 0.821112 valid_0's binary_logloss: 0.138732
[62] valid_0's auc: 0.820872 valid_0's binary_logloss: 0.13879
[63] valid_0's auc: 0.820854 valid_0's binary_logloss: 0.138797
[64] valid_0's auc: 0.820634 valid_0's binary_logloss: 0.138854
[65] valid_0's auc: 0.820345 valid_0's binary_logloss: 0.138907
[66] valid_0's auc: 0.820225 valid_0's binary_logloss: 0.138951
[67] valid_0's auc: 0.819931 valid_0's binary_logloss: 0.139008
[68] valid_0's auc: 0.819816 valid_0's binary_logloss: 0.139055
[69] valid_0's auc: 0.819712 valid_0's binary_logloss: 0.139084
[70] valid_0's auc: 0.819595 valid_0's binary_logloss: 0.139154
[71] valid_0's auc: 0.819525 valid_0's binary_logloss: 0.139178
[72] valid_0's auc: 0.819243 valid_0's binary_logloss: 0.139267
[73] valid_0's auc: 0.819003 valid_0's binary_logloss: 0.139362
[74] valid_0's auc: 0.818834 valid_0's binary_logloss: 0.139418
[75] valid_0's auc: 0.818683 valid_0's binary_logloss: 0.139461
[76] valid_0's auc: 0.818202 valid_0's binary_logloss: 0.139515
[77] valid_0's auc: 0.817946 valid_0's binary_logloss: 0.139603
[78] valid_0's auc: 0.817773 valid_0's binary_logloss: 0.139637
[79] valid_0's auc: 0.817531 valid_0's binary_logloss: 0.139694
[80] valid_0's auc: 0.81722 valid_0's binary_logloss: 0.139759
[81] valid_0's auc: 0.817155 valid_0's binary_logloss: 0.139801
[82] valid_0's auc: 0.817079 valid_0's binary_logloss: 0.139797
[83] valid_0's auc: 0.816882 valid_0's binary_logloss: 0.13985
[84] valid_0's auc: 0.816712 valid_0's binary_logloss: 0.139922
[85] valid_0's auc: 0.816481 valid_0's binary_logloss: 0.139974
[86] valid_0's auc: 0.816117 valid_0's binary_logloss: 0.140075
[87] valid_0's auc: 0.816099 valid_0's binary_logloss: 0.140059
[88] valid_0's auc: 0.816001 valid_0's binary_logloss: 0.140106
[89] valid_0's auc: 0.815796 valid_0's binary_logloss: 0.140168
[90] valid_0's auc: 0.815783 valid_0's binary_logloss: 0.140193
[91] valid_0's auc: 0.815826 valid_0's binary_logloss: 0.14019
[92] valid_0's auc: 0.815679 valid_0's binary_logloss: 0.140253
[93] valid_0's auc: 0.815516 valid_0's binary_logloss: 0.1403
[94] valid_0's auc: 0.815257 valid_0's binary_logloss: 0.140362
[95] valid_0's auc: 0.815118 valid_0's binary_logloss: 0.140395
[96] valid_0's auc: 0.814988 valid_0's binary_logloss: 0.140461
[97] valid_0's auc: 0.814916 valid_0's binary_logloss: 0.140491
[98] valid_0's auc: 0.814719 valid_0's binary_logloss: 0.140519
[99] valid_0's auc: 0.814513 valid_0's binary_logloss: 0.140596
[100] valid_0's auc: 0.814615 valid_0's binary_logloss: 0.140596
[101] valid_0's auc: 0.81455 valid_0's binary_logloss: 0.140632
[102] valid_0's auc: 0.814524 valid_0's binary_logloss: 0.140652
[103] valid_0's auc: 0.814332 valid_0's binary_logloss: 0.140729
[104] valid_0's auc: 0.814406 valid_0's binary_logloss: 0.140729
[105] valid_0's auc: 0.814494 valid_0's binary_logloss: 0.140736
[106] valid_0's auc: 0.814446 valid_0's binary_logloss: 0.140757
[107] valid_0's auc: 0.814092 valid_0's binary_logloss: 0.140874
[108] valid_0's auc: 0.814111 valid_0's binary_logloss: 0.140904
[109] valid_0's auc: 0.813941 valid_0's binary_logloss: 0.140935
[110] valid_0's auc: 0.813914 valid_0's binary_logloss: 0.140942
[111] valid_0's auc: 0.813801 valid_0's binary_logloss: 0.140986
[112] valid_0's auc: 0.813293 valid_0's binary_logloss: 0.141086
[113] valid_0's auc: 0.813284 valid_0's binary_logloss: 0.141107
[114] valid_0's auc: 0.812815 valid_0's binary_logloss: 0.141209
[115] valid_0's auc: 0.812663 valid_0's binary_logloss: 0.141244
[116] valid_0's auc: 0.812822 valid_0's binary_logloss: 0.14121
[117] valid_0's auc: 0.812623 valid_0's binary_logloss: 0.141262
[118] valid_0's auc: 0.812538 valid_0's binary_logloss: 0.141281
[119] valid_0's auc: 0.812578 valid_0's binary_logloss: 0.141293
[120] valid_0's auc: 0.812801 valid_0's binary_logloss: 0.141211
[121] valid_0's auc: 0.812663 valid_0's binary_logloss: 0.141287
[122] valid_0's auc: 0.812485 valid_0's binary_logloss: 0.141327
[123] valid_0's auc: 0.812555 valid_0's binary_logloss: 0.141351
[124] valid_0's auc: 0.813007 valid_0's binary_logloss: 0.141304
[125] valid_0's auc: 0.81289 valid_0's binary_logloss: 0.141299
[126] valid_0's auc: 0.812579 valid_0's binary_logloss: 0.141388
[127] valid_0's auc: 0.812699 valid_0's binary_logloss: 0.141409
[128] valid_0's auc: 0.81256 valid_0's binary_logloss: 0.141436
[129] valid_0's auc: 0.812456 valid_0's binary_logloss: 0.141466
[130] valid_0's auc: 0.812543 valid_0's binary_logloss: 0.141488
[131] valid_0's auc: 0.812427 valid_0's binary_logloss: 0.141521
[132] valid_0's auc: 0.812236 valid_0's binary_logloss: 0.141618
[133] valid_0's auc: 0.812159 valid_0's binary_logloss: 0.141665
[134] valid_0's auc: 0.811863 valid_0's binary_logloss: 0.141757
[135] valid_0's auc: 0.811658 valid_0's binary_logloss: 0.141818
[136] valid_0's auc: 0.811612 valid_0's binary_logloss: 0.141817
[137] valid_0's auc: 0.811529 valid_0's binary_logloss: 0.14184
[138] valid_0's auc: 0.811442 valid_0's binary_logloss: 0.141896
[139] valid_0's auc: 0.811524 valid_0's binary_logloss: 0.141931
[140] valid_0's auc: 0.811309 valid_0's binary_logloss: 0.142004
[141] valid_0's auc: 0.811321 valid_0's binary_logloss: 0.142035
[142] valid_0's auc: 0.811275 valid_0's binary_logloss: 0.142077
[143] valid_0's auc: 0.811453 valid_0's binary_logloss: 0.142082
ROC AUC: 0.8239
-> XGBoost에 비하면 수행시간이 엄청 빠르다!
6.1 그리드서치CV로 lgbm_clf 수행
%%time
# 그리드서치CV로 lgbm_clf 수행
from sklearn.model_selection import GridSearchCV
# 하이퍼 파라미터 테스트의 수행 속도를 향상시키기 위해 n_estimators를 100으로 감소
LGBM_clf = LGBMClassifier(n_estimators=200)
params = {'num_leaves': [32, 64],
'max_depth':[128, 160],
'min_child_samples':[60, 100],
'subsample':[0.8, 1]}
# 하이퍼 파라미터 테스트의 수행속도를 향상 시키기 위해 cv 를 지정하지 않습니다.
gridcv = GridSearchCV(lgbm_clf, param_grid=params)
gridcv.fit(X_train, y_train, early_stopping_rounds=30, eval_metric="auc",
eval_set=[(X_train, y_train), (X_test, y_test)])
print('GridSearchCV 최적 파라미터:', gridcv.best_params_)
lgbm_roc_score = roc_auc_score(y_test, gridcv.predict_proba(X_test)[:,1], average='macro')
print('ROC AUC: {0:.4f}'.format(lgbm_roc_score))GridSearchCV 최적 파라미터: {'max_depth': 128, 'min_child_samples': 100, 'num_leaves': 32, 'subsample': 0.8}
ROC AUC: 0.8263
CPU times: total: 2min 31s
Wall time: 1min 43s
>>> 그리드서치 결과
lgbm GridSearchCV 최적 파라미터: {'max_depth': 128, 'min_child_samples': 100, 'num_leaves': 32, 'subsample': 0.8}
# 위 하이퍼 파라미터를 적용하고 n_estimators는 1000으로 증가, early_stopping_rounds는 100으로 증가
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=32, sumbsample=0.8, min_child_samples=100,
max_depth=128)
evals = [(X_test, y_test)]
lgbm_clf.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="auc", eval_set=evals,
verbose=True)
lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:,1])
print('ROC AUC: {0:.4f}'.format(lgbm_roc_score))
>>>
ROC AUC: 0.8263-> 그리드서치를 이용해서 하이퍼 파라미터를 튜닝해서 성능을 극대화하기는 힘들다. XGBoost같은 좋은 알고리즘일 때 더욱 그렇다.
특히 트리 계열은 하이퍼 파라미터 종류가 너무 많아서 시간 대비 결과가 만족스럽지 않은 경우가 많다.
피처 엔지니어링의 중요성 : 이상치, 표준정규화 등을 통해 데이터를 잘 가공하는 것이 중요하다!
'Machine Learning > 머신러닝 완벽가이드 for Python' 카테고리의 다른 글
| ch4.09 분류 실습-신용카드_사기검출 (0) | 2022.10.11 |
|---|---|
| ch.4.09 분류 실습 2 : 신용카드 사기 예측 실습 (1) | 2022.10.11 |
| ch 4.07_01 LightGBM(실습) (0) | 2022.10.11 |
| ch. 4.7 LightGBM (0) | 2022.10.11 |
| ch.4.6.1 XGBoost(eXtra Gradient Boost)(실습) (0) | 2022.10.11 |



