NULLIF : 컬럼의 값이 같으면 null을 반환하는 함수
1. NULLIF 함수의 이해와 표현
오라클 SQL 디벨로퍼의 NULLIF는 A와 B의 값이 같으면 null, 다르면 컬럼A의 값을 반환하는 함수입니다.
(1) 기본식 : 임의의 값1, 값2를 비교하는 경우
select nullif (값1, 값2)
from dual;
값1=값2이면 null을, 값1≠값2이면 값1을 반환합니다.
(2) 기본식 : 컬럼X의 값들과 고정된 값1을 비교하는 경우
select nullif (컬럼X, 값1)
from 테이블이름A;
컬럼X의 값=값1 이면 null, 컬럼X의 값≠값1이면 컬럼X의 값이 반환됩니다.
(3) 기본식 : 여러 레코드의 컬럼X의 값들과 컬럼Y의 값들을 비교하는 경우
select nullif (컬럼X, 컬럼Y)
from 테이블이름A;
컬럼X의 값=컬럼Y의 값이면 null, 컬럼X의 값≠컬럼Y의 값이면 컬럼X의 값이 반환됩니다.
2. 예제 : NULLIF 함수의 사용
* 이하의 예제에서는 hr 연습계정의 employees, locations 테이블을 사용합니다.
1) 예제 : 임의의 값 100, 101을 NULLIF로 비교하는 경우
(당연한 결과이지만) NULLIF 함수의 기능을 살펴보기 위해 두 개의 상수를 비교하여, 나타나는 값을 관찰합니다.
select nullif (100, 100) as example01,
nullif (100, 101) as exmaple02
from dual;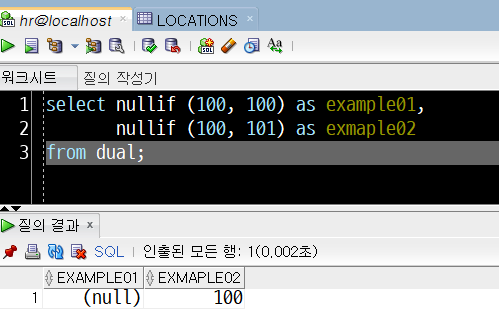
100=100이므로 example01에는 null이, 100≠101이므로 exmaple02에는 100이 반환되었습니다.
2) 예제 : employees 테이블의 salary 값이 17000인 경우에 NULLIF 적용하기
salary 컬럼의 값이 17000인 경우 null로 나타나게끔 임의의 컬럼c1을 반환하는 쿼리는 다음과 같습니다.
select salary, nullif (salary, 17000) as c1
from employees;
salary 값이 17000인 레코드는 null, 그렇지 않은 다른 모든 레코드의 값은 salary와 같게 나타났습니다.
3) 예제 : 두 컬럼 사이의 값 비교
locations 테이블의 city, state_province 컬럼에 NULLIF 함수를 적용하고, 그 결과를 비교하기
아래의 SQL 문장을 실행(Ctrl+Enter)합니다.
select city,
state_province,
nullif (city, state_province) as ex_nullif1,
nullif (state_province, city) as ex_nullif2
from locations;

ex_nullif1과 ex_nullif2의 결과가 서로 다른 이유는, NULLIF 함수에서는 괄호() 안에 투입하는 변수 또는 상수의 순서에 따라 결과가 달라지기 때문입니다.
데이터 임포트 : .csv 파일 가져오기, 테이블에 csv 파일의 레코드 넣기
오라클 SQL 디벨로퍼에서도 .csv 확장자 파일을 불러와 테이블로 만들 수 있습니다.
하지만, .csv 확장자 파일을 가져오기 위해서는, 반드시 "테이블 생성"이 수반되어야 합니다.
i. csv 파일의 변수, 데이터 유형 파악
ii. 임포트 하려는 csv 파일의 변수, 데이터 유형에 맞추어 SQL 테이블 생성(CREATE TABLE)
iii. 데이터 임포트 마법사로 csv 파일 불러오기
즉, .csv 파일을 바탕으로 일종의 자동 INSERT INTO를 해 주는 것이 '데이터 임포트' 기능입니다.
1. CSV 파일 준비하기, 데이터 구조 파악하기
오라클 SQL 디벨로퍼에 불러오려는 CSV 파일을 메모장 또는 스프레드시트 프로그램으로 열어 봅니다. 변수(컬럼)의 이름과 유형, 각 컬럼의 데이터 유형과 용량을 파악해야 합니다.
문자 / 숫자 / null 허용여부 / 데이터의 최대 길이 정도를 대략 파악해 줍니다. 이는 초기에 SQL 에서 테이블을 생성하는 과정에 필요합니다.

2. csv 데이터를 불러올 테이블 만들기
'1'에서 파악할 정보를 바탕으로, csv 파일의 데이터를 임포트할 테이블을 생성해 줍니다.
CREATE TABLE 명령어를 사용합니다.
* 만약 이 과정에서 테이블을 잘못 만들었더라도, 'ALTER TABLE' 등을 사용하여 테이블 설정을 변경할 수 있습니다. 다른 데이터셋에 대한 데이터 임포트 과정에서 여러번의 시행착오를 거칠 수도 있을 것입니다.
create table thorin_and_company (
mname varchar2(50) unique,
race varchar2(10) not null,
hometown varchar2(20),
position varchar2(20) not null,
age number(5),
year_b number(5),
year_d number(5),
fo1_lm number(1)
);
'thorin_and_company' 테이블이 생성되었습니다.

이 테이블은 아직 빈 테이블입니다. 이 비어있는 테이블에 .csv 파일이 가진 데이터를 불러와 레코드로 만들 것입니다.
3. 데이터 임포트
좌측 '접속'탭 >> 새로 만들어진 'thorin_and_company' 테이블 위에서 마우스 오른쪽 클릭 >> '데이터 임포트' 메뉴 선택
* 만약 접속 탭에 새로 만든 테이블이 없다면, 접속 탭 상단의 '새로고침'버튼을 누르거나, Oracle SQL Developer 종료 후 재접속하면 thorin_and_company 테이블이 나타나 있을 것입니다.

4. 데이터 임포트 : 설정
- 파일 : '찾아보기'를 눌러, 원하는 csv 파일을 지정
- 형식 : csv
- 인코딩 : UTF-8
그 외에 구분자, 왼쪽 둘러싸기/오른쪽 둘러싸기를 설정할 수 있습니다.
원하는 파일을 입력하면, 데이터 임포트 마법사 창의 '파일 내용' 박스에 csv 파일의 모습이 나타날 것입니다.

'다음'을 눌러 주세요.
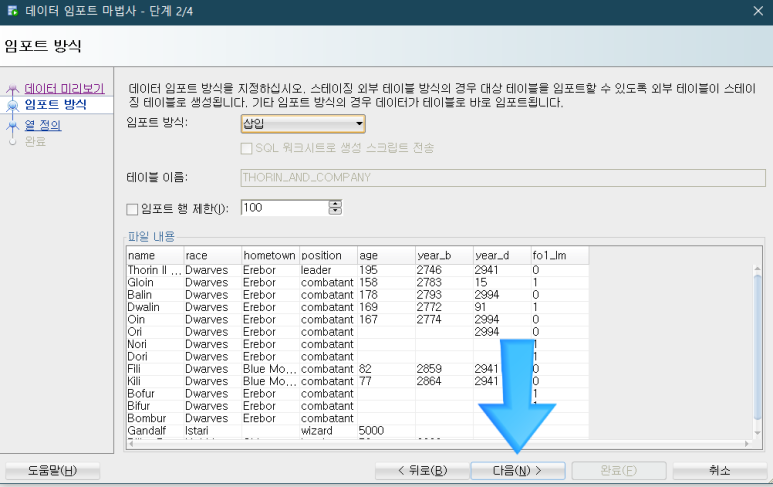
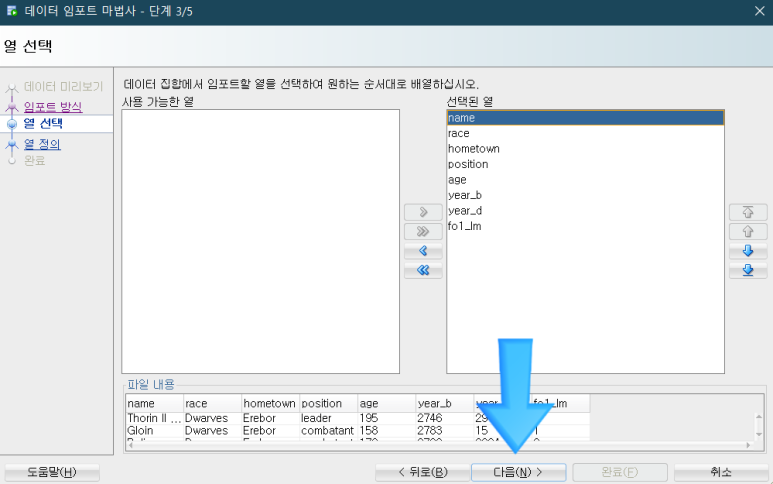
불러올 변수를 '선택된 열'로 끌어올 수 있습니다.
즉, 모든 열을 다 불러오지 않을 수도 있습니다.
5. 데이터 임포트 : 컬럼 매칭하기

각 변수별로, .csv 파일의 컬럼과 SQL에서 만든 thorin_and_company 테이블의 컬럼을 매칭해 줍니다.
이때 null을 포함하는 변수의 경우에는 null을 대체할 기본값을 설정해 줄 수도 있습니다.
* 변수 이름 첫머리에 노란색 삼각형의 '!' 아이콘이 떴다면 : SQL에서 준비한 빈 테이블의 데이터 유형에 문제가 있는 경우입니다. 불러올 csv 파일의 변수와 서로 데이터 유형 또는 설정된 데이터 크기가 맞지 않을 경우일 가능성이 큽니다. 이 경우에는, 데이터 임포트 창을 닫고 ALTER TABLE 메뉴로 데이터 유형을 변경해 주어야 합니다.
6. 데이터 임포트 완료
'다음'을 눌러 주세요.
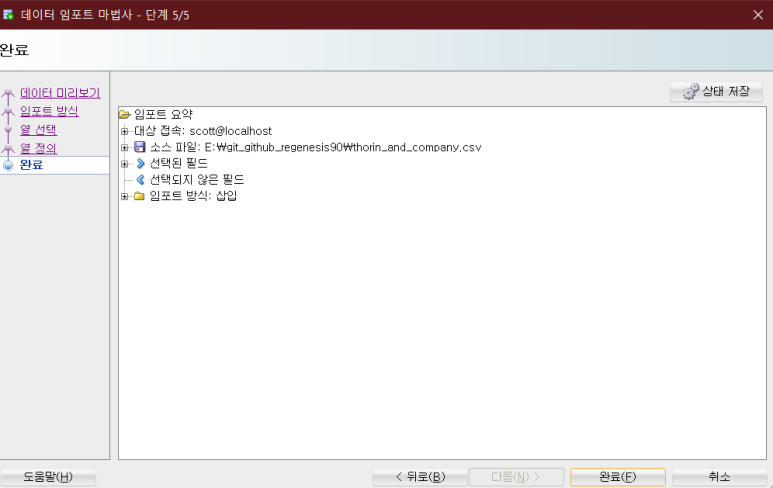

'데이터 임포트, 작업을 성공하고 임포트를 커밋했습니다' 라는 메시지가 나타나면 데이터 임포트가 성공적으로 완료된 것입니다. '확인'을 눌러 주세요.
7. 데이터 임포트 결과 확인 : 테이블 조회
SELECT FROM으로 thorin_and_company 테이블을 조회합니다.
select * from thorin_and_company;
비어있었던 thorin_and_company 테이블에 .csv 파일의 데이터가 성공적으로 임포트되었습니다.
SYSTIMESTAMP : 현재 시스템의 날짜,시각출력 함수 & 출력 형식 설정하기(alter session set nls_timestamp_tz_format)
오라클 SQL 디벨로퍼에서는 SYSDATE 외에도 SYSTIMESTAMP 함수를 사용해 시스템의 현재 날짜와 시각을 바로 출력하거나, 불러와서 변수 또는 날짜, 문자로 사용할 수 있습니다.
SYSDATE는 별도의 설정이 없는 상태에서는 시스템 날짜만을 출력하지만, SYSTIMESTAMP는 날짜와 시각, 시간대 모두를 표기한다는 점이 특징입니다.
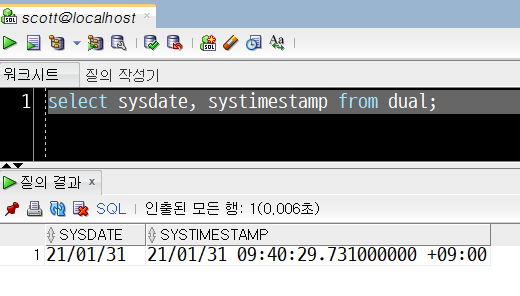
1. SYSTIMESTAMP를 이용해 시스템 현재날짜와 현재시각 출력하기
select systimestamp from dual;위 SQL 문장을 오라클 SQL 디벨로퍼에서 실행하면, 질의 결과에 현재 시스템(데이터베이스 서버)의 날짜와 시각, 시간대(타임존)이 함께 표기되는 것을 볼 수 있습니다.
별도의 설정이 없는 상태에서는 SYSDATE는 시스템 날짜만을 출력하지만, SYSTIMESTAMP는 날짜와 시각 모두를 보여주고 있습니다.
2. SYSTIMESTAMP의 출력 형식 변경하기 : alter session set nls_timestam_tz_format
alter session set NLS_DATE_FORMAT 명령어를 사용하면, 그 외의 다양한 형태로 SYSDATE 출력 형식을 바꿀 수 있습니다.
alter session set nls_timestamp_tz_format='출력형식';
YYYY-MM-DD:HH24:MI:SS.FF TZH:TZM
DD-MON-YYYY HH24:MI:SS.FF2 TZH:TZM
...
예제) SYSTIMESTAMP 출력형식의 변경
- 날짜2자리-달이름-연도4자리 24시간:분:초(소수점 없음) 형태로 SYSTIMESTAMP 양식을 변경하기
DD-MON-YYYY HH24:MI:SS.FF2 TZH:TZM
alter session set nls_timestamp_tz_format='DD-MON-YYYY HH24:MI:SS.FF2 TZH:TZM';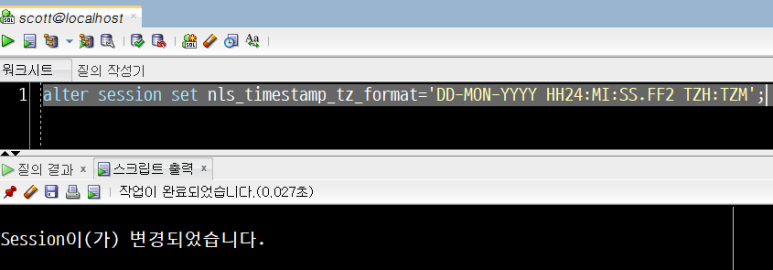
'Session이 변경되었습니다' 메시지가 스크립트 출력창에 나타나면, SYSTIMESTAMP 표시 형식이 변경된 것입니다.
SELECT FROM 쿼리로 변경된 SYSTIMESTAMP 형식을 조회할 수 있습니다.
select systimestamp from dual;
EXTRACT : 날짜 정보 추출 함수, 날짜 데이터에서 연도, 월, 일, 시, 분, 초 추출하기
오라클 SQL 에서 EXTRACT 함수는 날짜 유형의 데이터로부터 날짜 정보를 분리하여 새로운 컬럼의 형태로 추출해 주는 함수입니다.
테이블A의 날짜 변수가 담긴 컬럼X로부터 특정한 날짜요소를 추출하여 새로운 컬럼으로 반환하는 SQL 쿼리 문장의 형태는 다음과 같습니다.
select extract('날짜요소' from 컬럼X) as 별칭
from 테이블A;
'날짜요소'에 투입하는 항목에 따라, 날짜 데이터로부터 얻을 수 있는 값이 달라지게 됩니다.
|
SQL 쿼리에서의 날짜요소 표시
|
날짜 정보
|
|
YEAR
|
연도
|
|
MONTH
|
월
|
|
DAY
|
일
|
|
HOUR
|
시
|
|
MINUTE
|
분
|
|
SECOND
|
초
|
* 이하의 예제에서는 scott 연습계정을 사용합니다.
1) 예제 : 시스템 현재시각(SYSTIMESTAMP)에서 연도, 달, 날짜, 시간, 분, 초 추출하기
select systimestamp,
extract (year from systimestamp) as year,
extract (month from systimestamp) as month,
extract (day from systimestamp) as day,
extract (hour from systimestamp) as hour,
extract (minute from systimestamp) as minute,
extract (second from systimestamp) as second
from dual;
SYSTIMESTAMP(시스템 현재시각)로부터 연도, 달, ... 등의 날짜요소가 추출되었습니다.
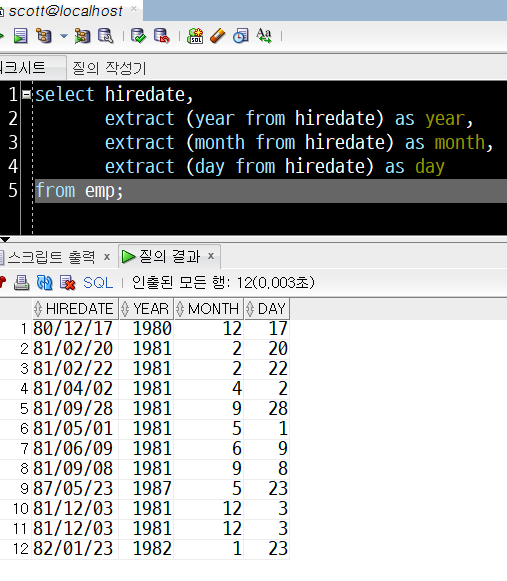
2) 예제 : scott 연습계정의 emp테이블의 hiredate 컬럼에서 연도, 달, 날짜 추출하기
select hiredate,
extract (year from hiredate) as year,
extract (month from hiredate) as month,
extract (day from hiredate) as day
from emp;
CREATE VIEW : 뷰 생성하기, 뷰 갱신하기 (CREATE OR REPLACE VIEW)
1. CREATE VIEW의 이해와 표현
1) CREATE VIEW, 또는 CREATE OR REPLACE VIEW
'뷰'는 SELECT FROM으로 조회한 결과를 데이터베이스에 테이블 형식으로 저장한 객체입니다. 매번 SQL 쿼리로 자주 쓰는 조회 결과를 불러오지 않더라도, 뷰를 한번 저장하면 해당 조회 결과를 마치 테이블처럼 간편하게 축약하여 하거나 편집할 수 있습니다. 뷰를 편집하더라도 원본 데이터에 영향을 미치지 않고, 원본 데이터의 컬럼 이름과 같은 정보를 보호할 수도 있습니다.
CREATE VIEW, 또는 CREATE OR REPLACE VIEW 명령어는 오라클SQL에서 '뷰(view)'를 생성해 주는 명령어입니다. 또는, CREATE OR REPLACE VIEW는 이미 같은 이름의 뷰를 생성할 경우 존재하고 있는 뷰를 갱신(덮어쓰기)하기도 합니다.
2) CREATE VIEW, 또는 CREATE OR REPLACE VIEW
CREATE OR REPLACE VIEW 는 조회할 뷰를 정의하는 SELECT FROM 구문을 서브쿼리에 넣어서 SQL 문장을 구성합니다.
(1) 기본식 : 뷰 만들기, 뷰 갱신하기
뷰를 생성할 경우에는 CREATE VIEW,
뷰를 생성하거나 기존의 뷰에 새로운 뷰를 덮어씌울 경우에는 CREATE OR REPLACE VIEW 명령어를 사용합니다.
create view 뷰이름A as (
SELECT FROM 구문);create or replace view 뷰이름A as (
SELECT FROM 구문);
(2) 기본식 : 읽기 전용 뷰 생성,
읽기 전용 뷰인지 조회하기
WITH READ ONLY는 뷰를 '읽기 전용'으로 생성합니다. 읽기 전용 모드에서는 DML 작업이 불가능합니다.
create or replace view 뷰이름A as (
SELECT FROM 구문)
with read only;뷰A가 읽기 전용인지, 아닌지 여부를 확인하고 싶다면,
다음과 같은 구문을 사용하여 읽기 전용 모드 여부를 조회할 수 있습니다.
이 때, 뷰 이름은 반드시 영문 대문자로 조회해야 합니다.
select read_only
from user_views
where view_name='뷰이름A';
(3) 기본식 : 서브쿼리 조건 검사
서브쿼리인 SELECT FROM 구문에 WHERE 조건절이 있을 경우, 이 WHERE 조건을 만족하지 않는 데이터가 뷰A에 생성되는 것을 방지합니다.
create or replace view 뷰이름A as (
SELECT FROM 구문)
with check point;
(4) 기본식 : 뷰 조회
생성된 뷰는 테이블처럼 SELECT FROM을 통하여 조회할 수 있습니다.
select * from 뷰이름A;
2. 예제 : 뷰(view) 생성하기, 조회하기
* 이하의 예제에서는 hr 연습계정의 여러 테이블을 사용합니다.
scott 연습계정은 GRANT 명령어로 권한을 부여하지 않으면, (초기 설정대로는) 뷰 생성이 되지 않습니다.
1) 예제 : employees, departments, jobs 테이블을 join한 결과를 view로 만들기
아래와 같은 SELECT FROM 결과를 뷰로 만드려고 합니다.
select e1.first_name as name,
j.job_title as job,
e1.salary,
e2.first_name as mgr_name,
d.department_name
from employees e1 left join departments d on e1.department_id=d.department_id
left join employees e2 on e1.manager_id=e2.employee_id
left join jobs j on e1.job_id=j.job_id;
CREATE VIEW 구문의 서브쿼리 영역에 뷰로 저장하고자 하는 위 SQL 문장을 투입해 줍니다.
create view v1 as (
select e1.first_name as name,
j.job_title as job,
e1.salary,
e2.first_name as mgr_name,
d.department_name
from employees e1 left join departments d on e1.department_id=d.department_id
left join employees e2 on e1.manager_id=e2.employee_id
left join jobs j on e1.job_id=j.job_id
)
;위 SQL 문장을 실행(Ctrl+Enter)합니다.
'View V1이 생서되었습니다'라는 메시지가 스크립트 출력창에 나타났다면 해당 뷰가 무사히 생성된 것입니다.

좌측의 접속 탭 중, hr 연습계정의 '뷰' 하위 메뉴에도 V1이 나타나 있습니다.
2) 예제 : 생성된 뷰 조회하기
생성된 뷰는 SELECT FROM을 사용하여 테이블과 마찬가지로 조회할 수 있습니다.
select * from v1;
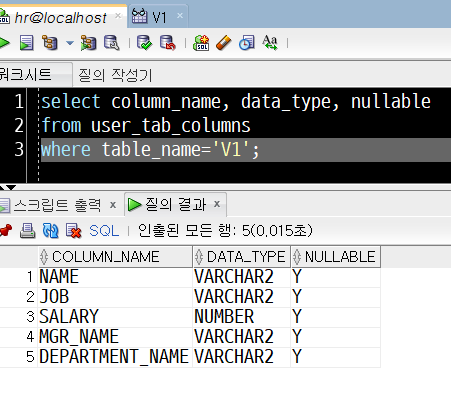
3) 뷰 정보 조회 : 데이터 딕셔너리 사용
레퍼런스를 사용하여, 새로이 생성한 뷰(v1)의 정보를 조회할 수 있습니다. 이때 뷰의 컬럼 이름은 원본 데이터의 컬럼이름이 아닌, 뷰를 생성했을 때 별칭으로 정한 이름이 뷰의 컬럼 이름으로 나타나는 것을 확인할 수 있습니다.
select column_name, data_type, nullable
from user_tab_columns
where table_name='V1';
4) 예제 : 읽기 전용(read only) 뷰 생성하기
읽기 전용 뷰를 생성하려면, 서브쿼리 후 'with read only'를 SQL 문장에 추가해 줍니다.
create view v2 as (
select first_name||' '||last_name as fullname,
email||'@tenebris.com' as mailad,
phone_number as phone
from employees
where job_id='SA_REP')
with read only;select * from v2;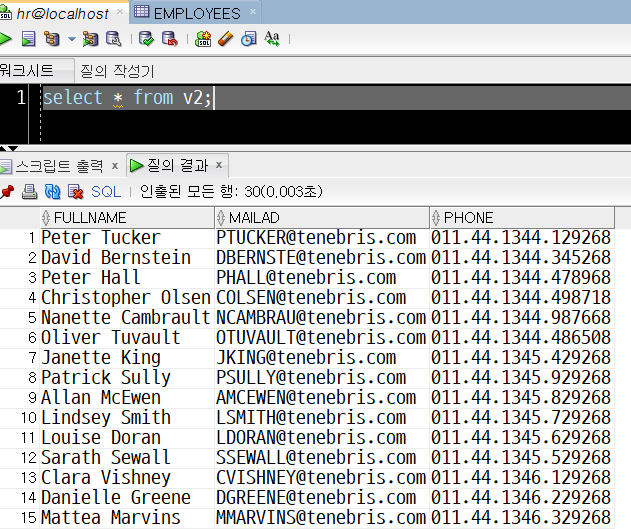
읽기 전용 뷰에서는 각종 DML 작업(DELETE, INSERT, UPDATE, ...) 이 제약됩니다. 아래와 같이 DELETE 명령어를 수행할 경우, 오류가 발생하는 것을 확인할 수 있습니다.
만약 DML 작업을 하고 싶다면, 해당 뷰의 읽기 전용 모드를 해제해야 합니다.
delete from v2;
오류 보고 -
SQL 오류: ORA-42399: 읽기 전용 뷰에서는 DML 작업을 수행할 수 없습니다.
42399.0000 - "cannot perform a DML operation on a read-only view"
5) 뷰 : 읽기 전용 모드 여부 확인하기
v2 뷰의 읽기 전용 모드 여부를 확인합니다. 이 때, 뷰 이름은 대문자로 입력해야 합니다.
select read_only from user_views where view_name='V2';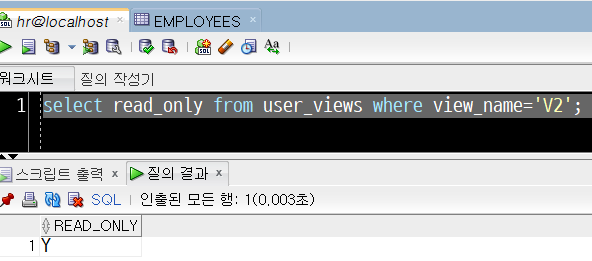
READ_ONLY 컬럼의 값이 'Y'입니다. 즉, 현재 읽기 전용 모드임을 나타냅니다.
6) 뷰 갱신하기
읽기 전용 모드를 해제하거나, 새로운 내용으로 바꾸는 등 뷰 내용을 덮어 씌우려면, CREATE OR REPLACE VIEW를 사용하고 갱신을 원하는 뷰 이름을 입력해 줍니다.
다음은 v2 뷰를 읽기 전용 모드가 아닌 뷰로 갱신하는 SQL 문장입니다.
create or replace view v2 as (
select first_name||' '||last_name as fullname,
email||'@tenebris.com' as mailad,
phone_number as phone
from employees
where job_id='SA_REP');
7) 오류 : ORA-01733
테이블과 달리 가상 열을 사용할 수 없습니다.
INSERT INTO로 임의의 레코드를 투입하려 할 경우 다음과 같이 오류가 발생하는 것을 알 수 있습니다.
insert into v3 values ('Andrea Lloyd', 'al@tenebris.com', '010.9999.9999');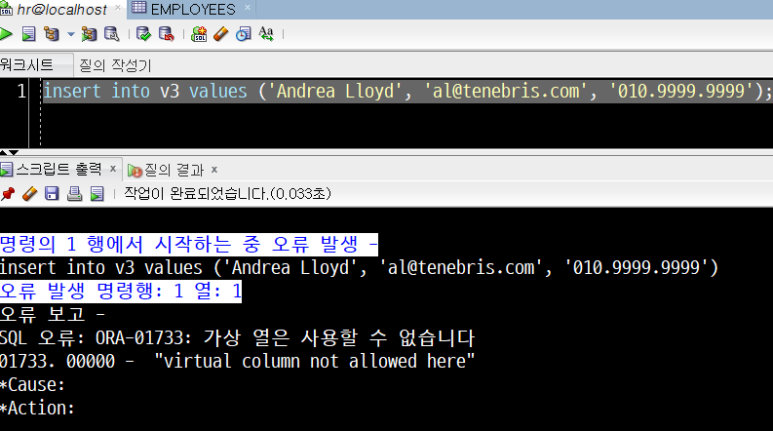
SQL 오류: ORA-01733: 가상 열은 사용할 수 없습니다
01733. 00000 - "virtual column not allowed here"
*Cause:
*Action:
DROP VIEW : 뷰 삭제 방법
DROP VIEW는 SQL에서 생성한 뷰를 제거하는 명령어입니다.
뷰A를 제거하는 SQL 문장은 다음과 같습니다.
drop view 뷰이름A;
* 이하의 예제는 hr 연습계정에서 임의로 생성한 뷰 객체 v3을 사용합니다.
예제) 뷰 v3 제거하기
drop view v3;
'View V3이 삭제되었습니다' 라는 메시지가 나타난다면 해당 뷰가 삭제된 것입니다.
삭제된 뷰는 SELECT FROM 구문을 이용하여 조회하면, '테이블 또는 뷰가 존재하지 않는다'는 오류 메시지가 나타나게 됩니다.(ORA-00942)

ORA-00942: 테이블 또는 뷰가 존재하지 않습니다
00942. 00000 - "table or view does not exist"
*Cause:
*Action:
1행, 15열에서 오류 발생
데이터 익스포트 : SELECT - FROM 조회 결과 테이블을 csv 파일, xlsx 엑셀 파일 등으로 저장하기 (익스포트 마법사)
오라클 SQL 디벨로퍼에서 SELECT - FROM 구문을 사용하여 데이터베이스의 테이블을 다양하게 가공된 형태로, 원본 데이터베이스를 변형하지 않고도 조회할 수 있었습니다. 이 조회 결과를 다른 프로그램에서 사용하기 위해 내보내기(export) 해야 할 수 있습니다.
데이터 임포트 마법사를 통해서 외부의 CSV 또는 XLSX 파일을 불러왔다면, '익스포트' 기능을 통해서 오라클 SQL 디벨로퍼의 질의 결과 창에 나타난 SELECT-FROM 조회 결과 테이블을 .csv, .xlsx, .xls, .txt, .pdf, ... 등의 확장자 파일로 내보내기 할 수도 있습니다.
- csv, xlsx, xls, xlm, html, json, pdf...
1) 예제 : 조회 결과를 CSV 파일로 내보내기
(1) 익스포트 마법사 시작
SELECT - FROM 구문을 실행하여 하단 '질의 결과'창에 조회 결과가 나타난 상태에서,
질의 결과 영역에서 마우스 오른쪽 버튼을 클릭합니다.
나타난 메뉴 창에서 '익스포트' 메뉴를 클릭합니다.
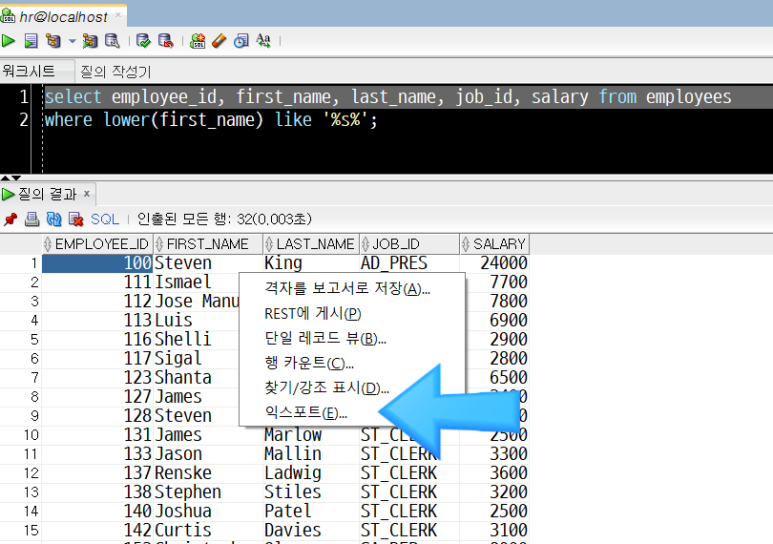
(2) 파일 형식 : csv 선택
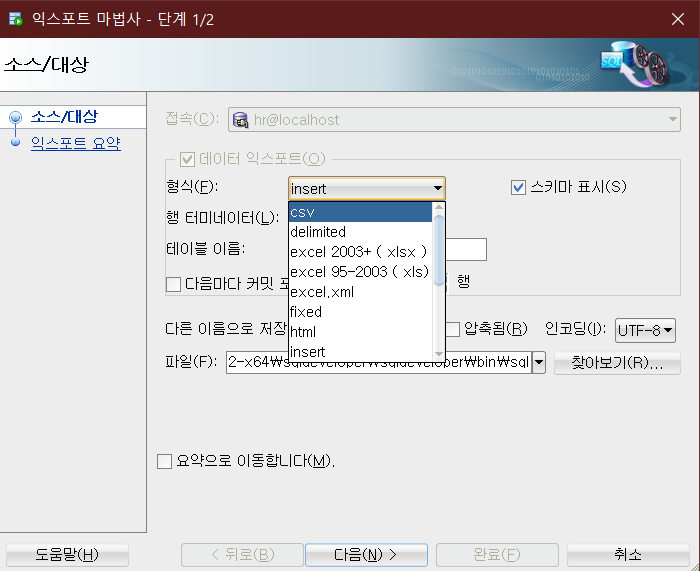
(3) 파일 이름, 경로 지정
파일 이름에는 확장자(.csv)를 포함한 이름을 적어 주세요.

(4) 둘러싸기 문자 지정, 헤더 포함 여부 설정
'헤더'를 체크하면 조회 결과의 컬럼 이름(변수 이름)이 csv 파일의 첫 행에 포함됩니다.
'왼쪽 둘러싸기', '오른쪽 둘러싸기'는 둘러싸기 문자를 선택할 수 있습니다.(큰따옴표, 작은따옴표 등)

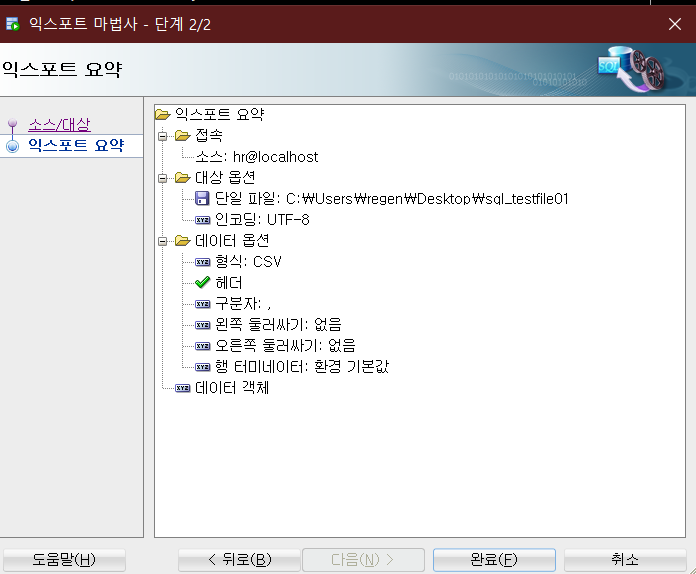
(5) 데이터 익스포트 완료
'완료'버튼을 누르기 전, 익스포트 정보를 요약하여 볼 수 있습니다. '완료' 버튼을 눌러 익스포트 과정을 끝냅니다.
(6) 익스포트 된 csv 파일 확인하기
지정한 경로에 새로운 .csv 파일이 생겨나 있습니다. 메모장 등을 연결하여 내용을 확인해 보면, SQL에서 조회된 결과가 CSV 파일 형식으로 저장되었음을 확인할 수 있습니다.

2) 예제 : 조회 결과를 xlsx, xls 파일로 내보내기
(1) 익스포트 마법사 시작
CSV 파일과 마찬가지로 SELECT - FROM 구문을 실행하여 하단 '질의 결과'창에 조회 결과가 나타난 상태에서,
질의 결과 영역에서 마우스 오른쪽 버튼을 클릭합니다.
나타난 메뉴 창에서 '익스포트' 메뉴를 클릭합니다.

(2) 파일 형식, 헤더, 데이터 워크시트 이름, 파일 경로 및 이름 설정
- 파일 형식 : xlsx 또는 xls 선택
엑셀의 경우 버전에 따라 확장자가 다르므로, 필요한 버전에 맞추어 확장자를 설정해 줍니다.
- 헤더(컬럼 이름) 포함 여부 : 체크
헤더 메뉴를 체크하면, SQL 조회 결과의 컬럼 이름이 가장 첫 행에 포함됩니다.
- 데이터 워크시트 이름 :
내보내기로 생성할 엑셀파일의 시트 이름을 설정합니다.
- 파일 경로 및 이름 :
저장을 원하는 경로와 파일 이름을 설정합니다. 파일 이름 뒤에 확장자(.xlsx 또는 .xls)를 붙여 주세요.

(3) 익스포트 완료
'완료' 버튼을 누르면, 설정한 대로 SQL 조회결과가 엑셀 파일로 저장됩니다.
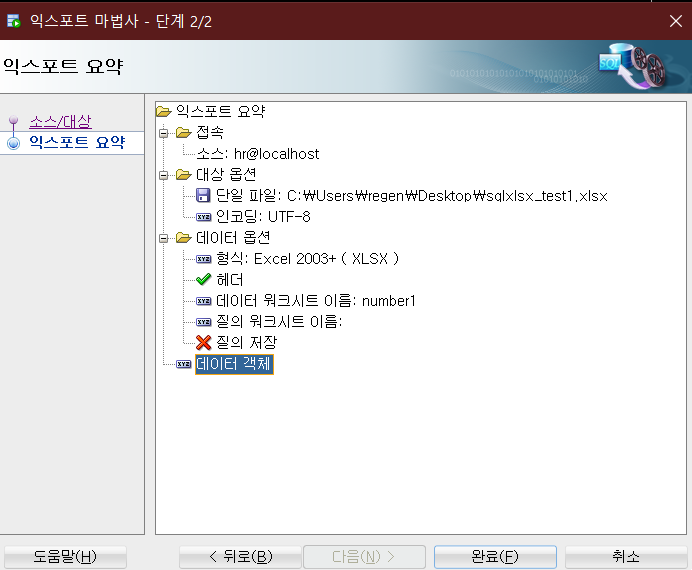
(4) 내보내기 된 엑셀파일 확인하기
엑셀 뷰어, 오피스 프로그램으로 만들어진 엑셀파일을 열어보면, SQL 조회 결과가 엑셀 파일 내에 문제없이 담겨 있는 것을 확인할 수 있습니다.

'데이터 임포트', '익스포트' 기능을 활용하면, SQL에서 다룬 데이터를 R, Python 등 다른 언어의 개발환경을 넘나들며 같은 데이터를 사용할 수 있을 것입니다.
'Structured Query Language > Oracle SQL' 카테고리의 다른 글
| Oracle SQL_DUAL (0) | 2023.09.25 |
|---|---|
| [ Oracle SQL ] 계층형쿼리 (Hierarchy Query) (0) | 2023.07.28 |
| Oracle SQL 기본_13 (0) | 2023.05.02 |
| Oracle SQL 기본_12 (0) | 2023.04.28 |
| Oracle SQL 기본_12 (1) | 2023.04.28 |



