ch.4.1 분류의 종류
분류 알고리즘
분류 (Classification) 는 학습 데이터로 주어진 데이터의 피처와 레이블값(결정 값, 클래스 값)을 머신러닝 알고리즘으로 학습해 모델을 생성하고, 이렇게 생성된 모델에 새로운 데이터 값이 주어 졌을 때 미지의 레이블 값을 예측하는 것입니다.
대표적인 분류 알고리즘들
- 베이즈 (Bayes) 틍계와 생성 모델에 기반한 나이브 베이즈(Naiive Bayes)
- 독립 변수와 종속변수의 선형 관계성에 기반한 로지스틱 회귀 (Logistic Regression)
- 데이터 균일도에 따른규직 기반의 결정 트리 (DecisionTree)
- 개별 클래스 간의 죄대 분류 마진을 효과적으로 잦아주는 서포트 벡터 머신 (SupportVector Machine)
- 근접 거리를 기준으로 하는 최소 근접 (Nearest Neighbor) 알고리즘
- 심층 연결 기반의 신경망 (Neural Network)
- 서로 다른(또는 같은) 머신러닝 알고리즘을 결합한 앙상블(Ensemble)
ch.4.2 결정 트리
결정 트리와 앙상블
- 결정 트리는 매우 쉽고 유연하게 적용될 수 있는 알고리즘입니다. 또한 데이터의 스게일링이나 정규화 등의 사전 가공의 영향이 매우 적습니다. 하지만 예즉 성능을 향상시키기 위해 복잡한 규칙 구조를 가져야 하며, 이로 인한 과적합(overfitting) 이 발생해 반대로 예측 성능이 저하될 수도 있다는 단점이 있습니다.
- 하지만 이러한 단점이 앙상블 기법에서는 오히려 장점으로 작용합니다. 앙상블은 매우 많은 여러개의 약한 학습기(즉, 예즉 성능이 상대적으로 떨어지는 학습 알고리즘)를 결합해 확률적 보완과 오류가 발생한 부분에 대한 가중지를 계속 업데이트하면서 예즉 성능을 향상시키는데, 결정 트리가 좋은 약한 학습기가 되기 때문입니다. (GBM, XGBoost, LightGBM 등)
결정 트리
- 결정 트리 알고리즘은 데이터에 있는 규직을 학습을 통해 자동으로 젖아내 드리 (Tree) 기반의 분류 규칙을 만듭니다 (If-Else 기반 규직)
- 따라서 데이터의 어떤 기준을 배당으로 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 고리즘의 성능을 크게 좌우합니다.

트리 분할을 위한 데이터의 균일도

균일도 기반 규칙 조건

노랑색 블록의 경우 모두 동그라미로 구성되고, 빨강과 파랑 블록의 경우는 동기라미 , 네모, 세모가 골고루 섞여 있다고 한다면 각 레고 블록을 분류하고자 할 때 가장 첫 번째로 만들어져야 하는 규칙 조건은?
==>> IF 색깔 == '노란색'
정보 균일도 측정 방법
정보 이득(Information Gain)
정보 이득은 엔트로피라는 개념을 기반으로합니다. 엔트로피는 주어진 데이터 집합의 혼잡도를 의미하는데, 서로 다른 값이 섞여 있으면 엔트로피가 높고, 같은 값이 섞여 있으면 엔트로피가 낮습니다. 정보 이득 지수는 1 에서 엔트로피 지수를뺀 값입니다. 즉 1-엔트로피 지수입니다. 결정 트리는 이 정보 이득 지수로 분할 기준을 정합니다. 즉, 정보 이득이 높은 숙성을 기준으로 분할합니다.
지니계수
지니 계수는 원래 경제학에서 1 불평등 지수를 나타낼 때 사용하는 계수입니다. 경제학자인 코라도지니 (Corrado Gini)의
이름에서 딴 계수로서 0이 가장 평등하고 1로 갈수록 불평등합니다. 머신러닝에 적용될 때는 지니 계수가 낮을수록 데이터
균일도가 높은 것 으로 해석되어 계수가 낮은 속성을 기준으로 분할합니다.


결정트리의 규칙 노드 생성 프로세스

결정트리의 특징
과적합 단점을 해결하기 위해서 Max-depth의 값으로 제한한다.
결정 트리의 주요 하이퍼파라미터
하이퍼 파라미터- 사람이 스스로 입력하는 파라미터

결정트리의 시각화
Graphviz 를 이용한 결정트리 모델의 시각화-설치
- Graphviz 실행 파일을 설지
- Graphviz 파이썬 래퍼 모듈을 설지
- OS 환경변수 구성
Graphviz 의 시각화 노드
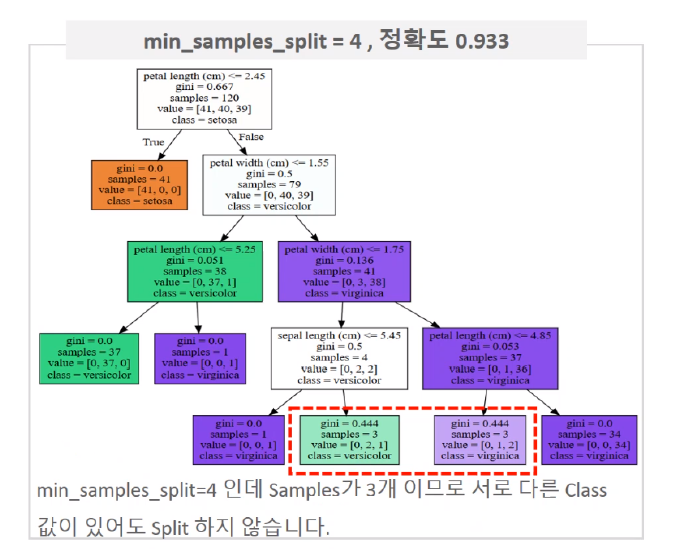
- petal length(cm) <= 2.45와 같이 피처의 조건이 있는 것은 자식 노드를 만들기 위한 규칙 조건입니다. 이 조건이 없으면 리프 노드입니다.
- Gini 는 다음의 value = []로 주어진 데이터 분포에서의 지니 계수입니다.
- samples는 현 규직에 해당하는 데이터 건수입니다.
- value = [ ]는 클래스 값 기반의 데이터 건수입니다. 붓꽃 데이터세트는 클래스 값으로 0, 1, 2 를 가지고 있으며, 0 :
Setosa, 1: Versicolor, 2: Virginica 품종을 가리킵니다.
만일 Value = [41, 40, 39] 라면 클래스 값의 순서로 Setosa 41 개 , Vesicolor 40 개, Virginica 39 개로 데이터가 구성돼 있다는 의미입니다. - class는 value 리스트 내에 가장 많은 건수를 가진 결정값입니다.

Graphviz를 이용한 결정 트리 모델의 시각화

max_depth 에 따른 결정 트 구조

min_samples_split 에 따른 결정 트리 구조
min_samples_leaf 에 따른 결정 트리 구조

결정 트리의 Feature 선택중요도
사이킷런의 DecisionCIassifier 객제는 feature_importances_ 을 통해 학습/예측을 위해서 중요한 Feature들을 선택 할 수 있게 정보를 제공합니다.

결정트리의 과적합
2 개의 Feature로 된 3 개의 결정 클래스를 가지도록 make_classification( ) 함수를 이용하여 임의 데이터를 생성한 후
트리 생성 제약이 없는 경우와 min_samples_leaf=6으로 제약을 주었을 때 분류 기준선의 변화

'Machine Learning > 머신러닝 완벽가이드 for Python' 카테고리의 다른 글
| ch.4.3 앙상블 - 보팅 (1) | 2022.10.06 |
|---|---|
| ch4.2 결정 트리(실습) (1) | 2022.10.06 |
| ch03 요약 (0) | 2022.10.06 |
| ch.3.6 실습 파마 인디언 당뇨병 예측(실습) (0) | 2022.10.06 |
| ch 3.1~3-5_정확도 _ ROC_AUC 예제 (실습) (0) | 2022.10.06 |


