목표
1. 군집화(Clustering)의 정의
2. 계층적 군집화
3. 군집화 평가
Clustering 정의
Clustering(군집화)
유사한 속성을 갖는 데이터들을 묶어 전체 데이터를 몇 개의 군집으로 나누는 것
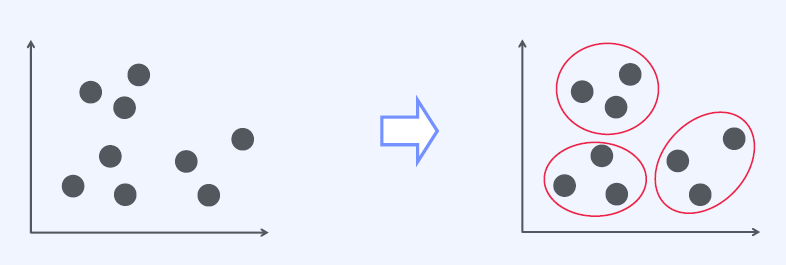
Clustering Classification vs Clustering
Classification
- Supervised Learning
- 소속 집단의 정보를 알고 있는 상태
- Label이 있는 데이터를 나누는 방법
Clustering
- Unsupervised Learning
- 소속 집단의 정보를 모르고 있는 상태
- Label이 없는 데이터를 나누는 방법

Clustering 종류
군집분석의 종류
1. 계층적(Hierarchical) 군집화
2. 비계층적 (Non-Hierarchical) 군집화
Hierarchical Clustering
계층적(Hierarchical) 군집화
- 개체들을 가까운 집단부터 묶어 나가는 방식
- 유사한 개체들이 결합되는 dendrogram 생성
- Cluster들은 sub-cluster를 갖고 있다.

Hierarchical Clustering 거리
개체들을 가까운 집단부터 묶어 나가는 방식
거리의 종류
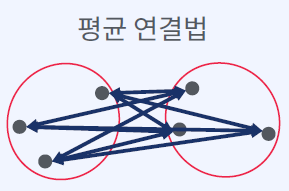
- 유클리드 거리
- 맨해튼 거리
- 표준화 거리
- 민콥스키 거리
Hierarchical Clustering 종류
Hierachical Clustering 종류
묶인 클러스터와 다른 데이터 간의 거리 측정 방법에 따라 달라진다.
1. 최단 연결법
2. 최장 연결법
3. 평균 연결법
4. 중심 연결법
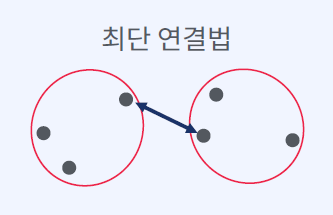
최단 연결법
군집에서 가장 가까운 데이터가 새로운 거리가 된다
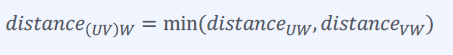
최장 연결법
군집에서 가장 먼 데이터가 군집과 데이터의 거리가 된다.
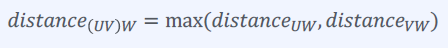

평균 연결법
군집의 데이터들 간의 거리의 평균이 군집과 데이터의 거리가 된다.

중심 연결법
군집의 중심이 새로운 거리가 된다.


최단 연결법 예시

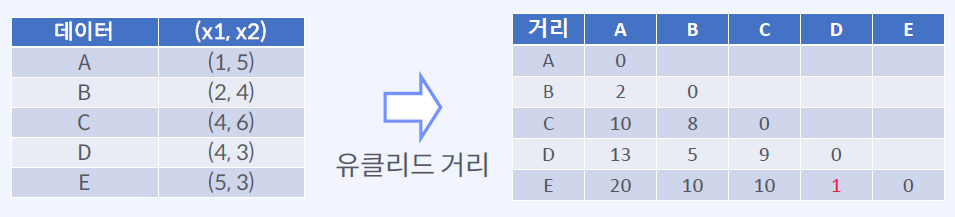

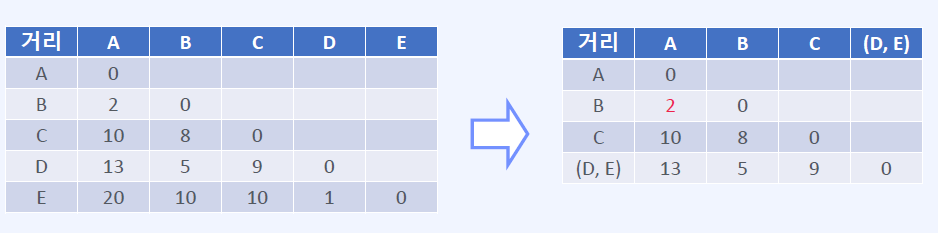

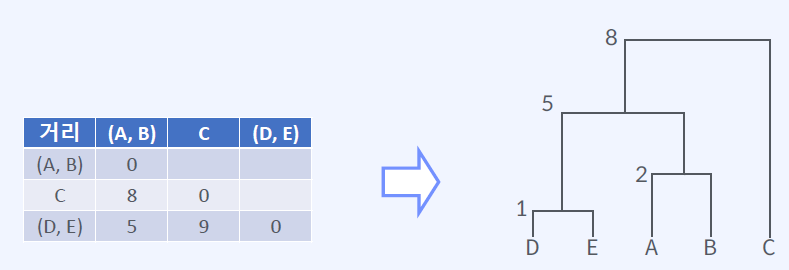
주어진 Cluster 의 개수에 맞게 데이터를 나누는 방법


Clustering 평가
좋은 Clustering이란?
- 군집 내 유사도를 최대화 (거리를 최소화)
- 군집 간 유사도를 최소화 (거리를 최대화)
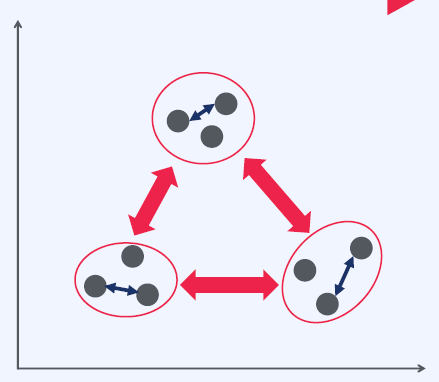
내부 평가
군집된 결과 그 자체를 놓고 평가하는 방식
외부 평가
군집화에 사용되지 않는 데이터로 평가하는 방식
Clustering 내부 평가 방법
내부 평가 방법
1. Dunn Index
2. 실루엣(Silhouette)
Dunn Index
Dunn Index

군집과 군집 사이의 거리가 클수록,
군집 내 데이터 간 거리가 작을 수록 좋은 모델
-> DI가 큰 모델
Silhouette Index
Silhouette Index
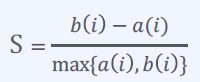
군집 내 응집도(cohesion)
𝑎(𝑖) : 데이터 𝑥𝑖 와 동일한 군집 내의 나머지 데이터들과의 평균 거리
군집 간 분리도(separation)
𝑏(𝑖) : 데이터 𝑥𝑖 와 가장 가까운 군집 내의 모든 데이터들과의 평균 거리
-> 값이 커질수록 좋은 인덱스이다.
'Machine Learning > 머신러닝 온라인 강의' 카테고리의 다른 글
| CH09_01. Dimensionality Reduction (0) | 2022.10.19 |
|---|---|
| CH08_02. Non-Hierarchical Clustering (0) | 2022.10.18 |
| CH07_04. 얼굴 사진 분류(Python) (0) | 2022.10.18 |
| CH07_02. SVM 커널 실습 (Python) (0) | 2022.10.18 |
| CH07_01. SVM (0) | 2022.10.12 |



