ch2. 추천시스템 준비
Jaccard index (similarity)
두 집합 사이의 유사도를 측정하는 방법
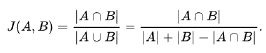
자카드 지수는 0과 1 사이의 값을 가지며,
두 집합이 동일하면 1의 값을 가지고, 공통의 원소가 하나도 없으면 0의 값을 가진다.

Manhattan Distance (L1 distance)


해당 속성 값 내에서 취 할 수있는 경로를 고려하기 때문에,
이산(discrete)형 및 이진(binary)데이터 간 거리를 계산하는데 사용된다.

Euclidean Distance (L2 distance)

• 매우 직관적이고 구현이 간단하고 좋은 결과를 보여주기 때문에 많이 사용된다.
• 저차원의 데이터를 사용하고 벡터의 크기를 측정하는것이 중요한 경우 효과적
- 데이터의 차원이 증가할수록 유클리드의 유용성은 떨어진다.
-> 코사인 유사도로 해결 가능

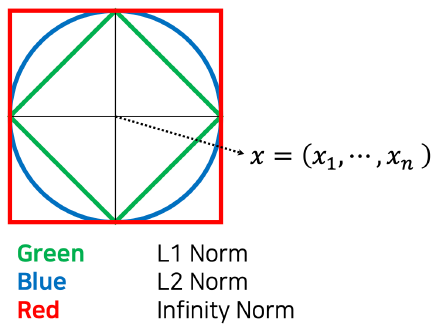
Infinity Norm
차이 절대값들 중 최대값


L1, L2 and Infinity
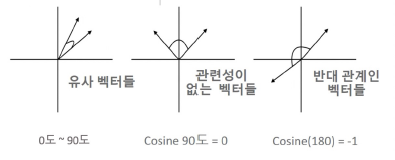
Cosine Similarity
벡터의 방향을 중요시해서, Feature vector의 각 차원의 상대적인 크기를 알려준다.
• 고차원 데이터 처리에 유클리드 거리가 가지는 문제를 해결하는 방법
• 단점 : 벡터의 크기가 고려되지 않고 단지 방향만 고려된다는 것.
즉, 다른 벡터 간의 차이가 완전히 고려되지는 않는다.
그래서 벡터의 크기가 중요하지 않고, 고차원 데이터의 경우에 사용.

'Machine Learning > 머신러닝 완벽가이드 for Python' 카테고리의 다른 글
| CH08.01 텍스트 분석의 이해 (0) | 2022.10.25 |
|---|---|
| Recommation System ch3. 장바구니 분석 (0) | 2022.10.20 |
| Recommation System ch1. 추천시스템이란? (0) | 2022.10.20 |
| ch6.4 SVD(Singular Value Decomposition) (0) | 2022.10.20 |
| ch6.2 PCA (0) | 2022.10.20 |


