SELECT FROM 구문 : 테이블 내용 전체 or 특정 컬럼 내용 조회하기
1. 테이블 내용 전체 조회하기
1) 기본식
특정 테이블 내용 전체를 조회하려면 아래와 같은 소스코드를 입력합니다.
select * from 테이블이름;
'*' 별표 : 전체 컬럼을 의미합니다.
지정한 테이블의 전체 컬럼의 데이터 전체를 조회한다는 의미입니다.
모든 SQL 문장은 ';(세미콜론)'으로 끝납니다.
Ctrl+Enter를 누르면 커서가 놓여 있는 곳의 해당 SQL 문장 1개가 실행됩니다.
2. 테이블의 특정 컬럼만 지정하여 조회하기
테이블이 가지고 있는 데이터와 컬럼이 굉장히 많을 경우, 기존 테이블을 변형하지 않고 분석에 필요한 일부 컬럼만을 불러와 데이터를 조회해야 하는 경우가 많습니다.
1) 기본식
select 컬럼이름1, 컬럼이름2, 컬럼이름3
from 테이블이름;select 다음에 필요한 컬럼이름을 나열해 줍니다.
(* 전체 컬럼을 조회할 때는 컬럼이름 대신 '*'를 썼었습니다)
SELECT DISTINCT 구문 : 중복되지 않는 데이터 조회·종류 조회
1) 기본식
select distinct 컬럼이름
from 테이블이름;
2) hr계정 employees 테이블의 manager_id 컬럼의 중복되지 않는 데이터 조회하기
다음의 구문을 코드편집기에 입력 후 Ctrl+Enter를 눌러 실행합니다.
select distinct manager_id
from employees;
3) hr계정 employees 테이블의 last_name 컬럼의 중복되지 않는 데이터 조회하기
다음의 구문을 코드편집기에 입력 후 Ctrl+Enter를 눌러 실행합니다.

2. 2개 이상 컬럼의 중복되지 않는 데이터 조회하기
2개 이상의 컬럼의 데이터를 중복되지 않도록 조회할 수도 있습니다.
이때는 (컬럼1데이터, 컬럼2데이터,...) 순서쌍이 중복되지 않는 결과로 출력됩니다.
1) 기본식
select distinct 컬럼이름1, 컬럼이름2, ...
from 테이블이름;
2) employees 테이블의 job_id, salary 컬럼의 중복되지 않는 데이터 출력하기
다음의 구문을 코드편집기에 입력 후 Ctrl+Enter를 눌러 실행합니다.

DESCRIBE, DESC 구문 : 테이블의 구조 확인하기
DESCRIBE 명령어는 어떤 테이블이 보유한 변수(variables, 또는 컬럼)가 어떤 것인지,
그리고 해당 변수의 데이터 유형과 NULL 허용 여부를 알게 해 줍니다.
1) 기본식
describe 테이블이름;
desc 테이블이름;describe와 desc 어느 쪽으로 해도 결과는 같습니다.
2) employees 테이블의 구조 확인하기
다음의 SQL 문장을 Ctrl+Enter로 실행합니다. describe, desc 어느 쪽을 실행해도 결과는 같습니다.

예컨대 employee_id 변수(컬럼)의 경우,
- Null을 허용하지 않고
- 데이터 유형은 6자리 숫자임을 알 수 있습니다.
salary 변수의 경우,
- Null을 허용하고
- 소수점 2자리까지의 숫자 데이터이며, 전체 자리수는 8자리입니다.
(범위 : -999999.99~999999.99)
first_name 변수의 경우,
- Null 허용
- 최대 20byte까지의 문자열
Alias, AS : 검색 결과의 컬럼에 별칭/별명/가칭을 붙여 테이블 조회하기

SELECT FROM 구문을 이용해 데이터를 출력했을 때, 데이터에 따라서는 컬럼 이름이 단축되거나 약어로 쓰이기도 하고, 문자와 번호가 혼용되기도 하며, 코드북을 수시로 참조해야 할 만큼 복잡한 경우가 많습니다.
데이터를 만들었거나 다루는 사람은 알더라도, 이 데이터를 그대로 제3자에게 보인다면 변수를 알기가 참 난해한 것입니다.
이 경우에는 SELECT FROM 구문으로 출력될 결과에 ALIAS(AS)를 사용하여, 변수(컬럼)을 알아보기 쉽도록 적당한 별칭을 붙여 줍니다. 물론 테이블 원본 데이터베이스의 내용은 변경되지 않습니다.
1) 기본식
select 컬럼이름1 as 별칭1, 컬럼이름2 as 별칭2, ...
from 테이블이름;
* 별칭 내에는 공백(' ', 스페이스)이 들어가면 안 됩니다.
2) emp 테이블의 empno, ename, job 컬럼에 적당한 별칭을 붙여 조회하기
emp 테이블의 empno는 '직원번호', ename은 '직원성명', job은 '직책'으로 별칭을 붙여 조회하겠습니다.
아래 SQL 구문을 코드편집기 창에 입력한 후 Ctrl+Enter를 눌러 실행합니다.

--, /**/ - 1줄 주석 or 2줄 이상 블록주석 달기
주석은 실행되지 않는 문장으로, 코드 중간에 필요한 코멘트/설명을 남길 때 사용합니다.
주석은 한 줄로도 남길 수 있고, 여러 줄로 남길 수도 있습니다.
-- 한 줄 주석 내용을 입력해 주세요
/*
여러줄 주석 내용을 작성해 주세요.
여러줄 주석 내용을 작성해 주세요.
여러줄 주석 내용을 작성해 주세요.
*/
1. 한 줄 주석 : --
'--' 다음에 입력하는 내용은, 그 줄이 끝날 때까지 주석으로 입력되고, Ctrl+Enter로 실행 시 실행 내용에서 제외됩니다.
2. 여러 줄 주석, 블록 주석 : /* */
'/*'와 '*/' 사이에 입력하는 내용은 줄이 바뀌더라도 주석으로 입력됩니다.
/*
여러줄 주석 내용을 작성해 주세요.
여러줄 주석 내용을 작성해 주세요.
여러줄 주석 내용을 작성해 주세요.
*/
여러줄 주석, 즉 블록주석은 '/*'로 시작되며, 도중에 줄이 바뀌더라도'*/'로 끝날 때까지 주석 상태가 계속됩니다.
Ctrl+Enter로 실행 시 실행 내용에서 제외됩니다.
WHERE 조건절의 사용 및 예시 : 데이터 필터링, 원하는 조건의 데이터만 출력하기
SELECT * FROM 테이블이름 구문,
SELECT 컬럼이름1, 컬럼이름2.. FROM 테이블이름 구문은
전체 또는 지정한 컬럼에 속한 '전체 행(row)'='전체 관측값(observation)'='전체 데이터'를 조회하게 합니다.
WHERE 조건절은 지정된 컬럼들에 대하여 출력될 행(row)들을 조건에 맞추어 필터링해주는 역할을 합니다.
즉, 조건에 맞는 관측값만을 보여주며, 조건에 부합하지 못하면 걸러냅니다.
등호, 부등호, null 여부, between 등을 응용하여 조건을 만들 수 있습니다.
1. 기본적 구조 : WHERE 조건절의 위치
select 컬럼이름1, 컬럼이름2, ...
from 테이블이름
where 조건;where 조건절은 'from 테이블이름' 뒤에 위치합니다.
2. WHERE 조건절을 이용한 예시들
1) scott 연습계정, emp테이블에서 급여(sal)가 3000이상인 데이터의 모든 컬럼을 조회하기
select * from emp
where sal>=3000;'where sal>=3000' 구문이 급여(sal)가 3000이상인 데이터만 조회하는 필터링 역할을 하는 조건절입니다.
Ctrl+Enter를 눌러 위 SQL 문장을 실행합니다.

급여(sal)가 3000이상인 데이터가 조회되었습니다.
조건을 만족하는 관측값이 7902번 직원 1명 뿐이었습니다.
2) scott 연습계정, emp테이블에서 매니저(mgr)가 있는 직원들에 대하여 empno, ename, job, sal 컬럼의 데이터를 조회하기
select empno as 직원번호, ename as 직원성명, job as 직책, sal as 월급여
from emp
where mgr is not null;'where mgr is not null' 절은 매니저가 있는=즉, 매니저(mgr) 컬럼이 null이 아닌 데이터만을 조회하는 필터링 역할을 하는 조건절입니다.
Ctrl+Enter를 눌러 위 SQL 문장을 실행합니다.

해당 조건을 만족하는 데이터만 출력되어, 12개 행이 출력되었습니다.
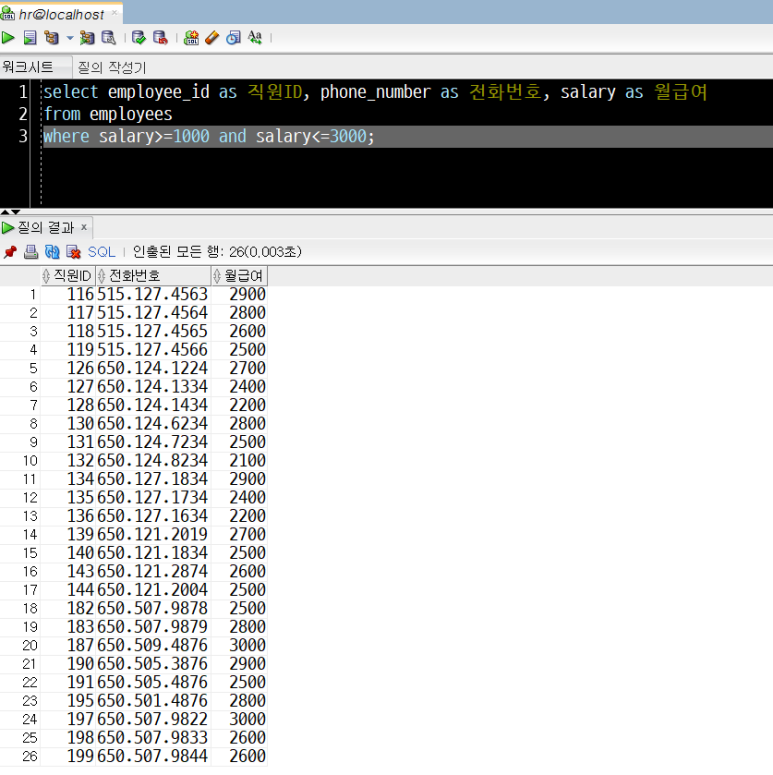
3) hr 연습계정, employees테이블에서 급여(salary)가 1000~3000 범위에 있는 데이터의 employee_id, phone_number, salary를 조회하기
select employee_id as 직원번호, phone_number as 전화번호, salary as 급여
from employees
where salary>=1000 and salary<=3000;
select employee_id as 직원번호, phone_number as 전화번호, salary as 급여
from employees
where salary between 1000 and 3000;
'where salary>=1000 and salary<=3000' 구문이 급여(sal)가 1000이상 3000이하인 데이터만 조회하는 필터링 역할을 하는 조건절입니다. 이것은 'where salary between 1000 and 3000'과 동일한 결과를 갖습니다.
Ctrl+Enter를 눌러 위 SQL 문장을 실행합니다.
* 여러개의 WHERE 조건을 갖는 경우, WHERE절 아래에서 and 또는 or로 연결합니다.
- and : 그리고(교집합)
- or : 또는(합집합)
4) hr 연습계정, employees테이블에서 2000년부터 고용된 직원들에 대하여 employee_id, first_name, last_name, hire_date를 조회하기
select employee_id as 직원ID, first_name as 이름, last_name as 성, hire_date as 고용시작일
from employees
where to_char(hire_date,'YYYY')>=2000;hire_date는 YY/MM/DD 형식으로 저장된 날짜 데이터입니다. 2000년부터 고용된 직원을 찾으려면, 연도(YYYY)가 2000 이상이어야 합니다.
'where to_char(hire_date, 'YYYY')>=2000'은 hire_date 변수에서 연도(YYYY) 만을 뽑아내어, 2000 이상인 관측값만을 조회하게끔 하는 조건절입니다.
위 SQL 문장을 Ctrl+Enter를 눌러 실행합니다.

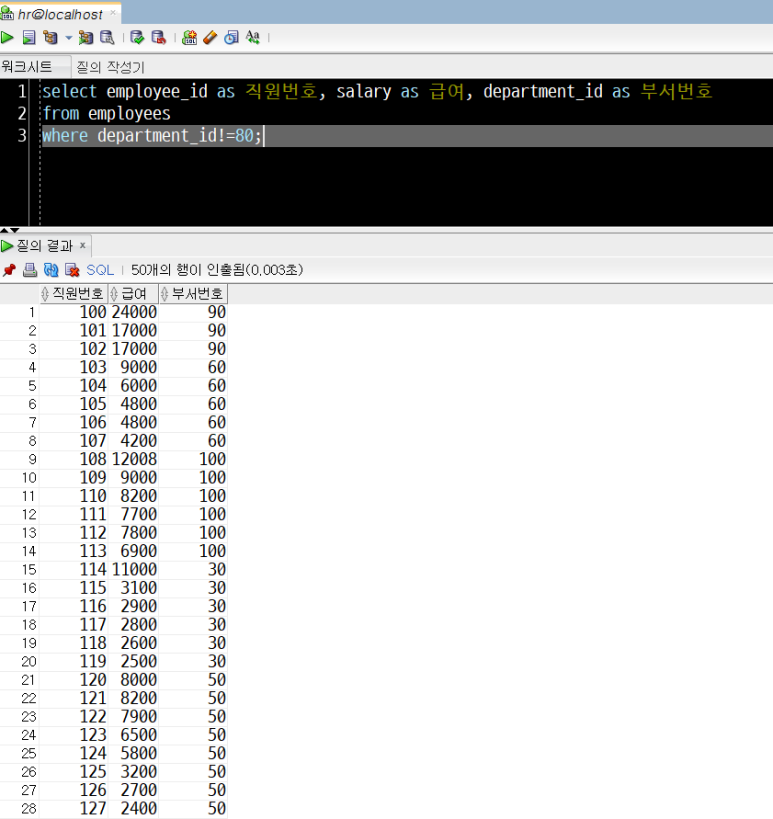
5) hr 연습계정, employees테이블에서 department_id가 80이 아닌 직원들에 대하여 employee_id, salary, department_id를 조회하기
select employee_id as 직원번호, salary as 급여, department_id as 부서번호
from employees
where department_id!=80;
Oracle SQL Developer 에서 등호는 '=', 같지 않음을 뜻하는 기호는 '!='입니다.
'where department_id!=80' 부분은 department_id(부서번호)가 80이 아닌 것만을 출력한다는 의미의 조건절이 됩니다.
위 SQL 문장을 Ctrl+Enter를 눌러 실행합니다.
WHERE 조건절은 이 외에도 굉장히 다양한 방식으로 응용되어 사용되고 있습니다.
'부등호, 같다-같지 않다, null이다-null이 아니다' 등의 WHERE 조건절에서의 표현
Oracle SQL Developer에서 WHERE 조건절, HAVING절에는 다양한 부등호, 같다-같지 않다, null 여부를 묻는 등의 내용이 사용되고 있습니다.
|
종류
|
SQL 문장에서의 표현
|
비고
|
|
크다, 작다
|
>, <
|
경계를 포함하지 않음
|
|
같거나 크다, 같거나 작다
|
>=, <=
|
경계를 포함함
|
|
그리고
|
and
|
교집합
|
|
또는
|
or
|
합집합
|
|
X는 A이상 B이하
|
X between A and B
|
'X>=A and X<=B'와 같은 뜻
'A<=x<=B'와 같은 표기는 불가
|
|
X는 A, B, ...N 중 하나
|
IN(A, B, ... N)
|
괄호 내부에 서브쿼리 가능
|
|
X는 N과 같음
|
X=N
|
|
|
X는 N과 같지 않음
|
X!=N
|
nul은 결과값에서 제외됨
'><, =!' 처럼 순서변경 불가
|
|
X<>N
|
||
|
X는 null임
|
X is null
|
X=null, X=NULL 불가
|
|
X는 null이 아님
|
X is not null
|
X!=null, X!=NULL 불가
|
ORDER BY : SELECT로 검색한 데이터를 정렬하는 방법과 그 예시(오름차순, 내림차순)
SELECT FROM 구문을 활용해 원하는 데이터를 조회하더라도, 조회하는 목적에 따라 다르게 정렬하여 볼 필요가 있습니다. 오라클 SQL 디벨로퍼의 ORDER BY 구문은 특정한 컬럼을 기준으로 오름차순/내림차순 정렬하여 검색된 데이터를 조회할 수 있도록 합니다.
○ 오름차순 / 내림차순 정렬
- asc(ascending order) 오름차순 정렬(기본값으로 설정되어 있습니다)
- desc(descending order) 내림차순 정렬
1) 기본식
ORDER BY는 SELECT 구문의 가장 마지막에 위치시켜야 합니다.
(1) 오름차순 정렬 : 기본값(Default)으로 설정되어 있어, asc를 생략합니다.
ORDER BY 다음에 입력된 컬럼을 기준으로 검색된 데이터를 오름차순 정렬합니다.
select 컬럼이름1, 컬럼이름2, ...
from 테이블이름
order by 컬럼이름n;
(2) 내림차순 정렬 : 정렬 기준이 될 컬럼 다음에 반드시 desc를 붙여 줍니다.
ORDER BY 다음에 입력된 컬럼을 기준으로 검색된 데이터를 오름차순 정렬합니다.
select 컬럼이름1, 컬럼이름2, ...
from 테이블이름
order by 컬럼이름n desc;
(3) WHERE, GROUP BY, HAVING 절이 모두 포함된 SELECT 구문에서 ORDER BY의 위치 :
여러 조건절, 그룹핑이 복합된 SELECT 구문에서도 ORDER BY는 문장의 가장 마지막에 위치시켜 줍니다.
내림차순 여부를 결정하는 DESC 도 마찬가지로 위치가 ORDER BY 의 가장 마지막이 됩니다.
또한, 2개 이상의 컬럼을 기준으로 정렬할 수도 있습니다.
select 컬럼이름1, 컬럼이름2, ...
from 테이블이름
where 조건
group by 컬럼이름z, 컬럼이름y
having 그룹 조건
order by 컬럼이름n, 컬럼이름m;
2) 예시 : ORDER BY 없이 employees 테이블의 직원 성명(first_name, last_name), 고용시작일(hire_date), 급여(salary)를 검색하는 경우
select first_name as 이름, last_name as 성, hire_date as 고용시작일, salary as 급여
from employees;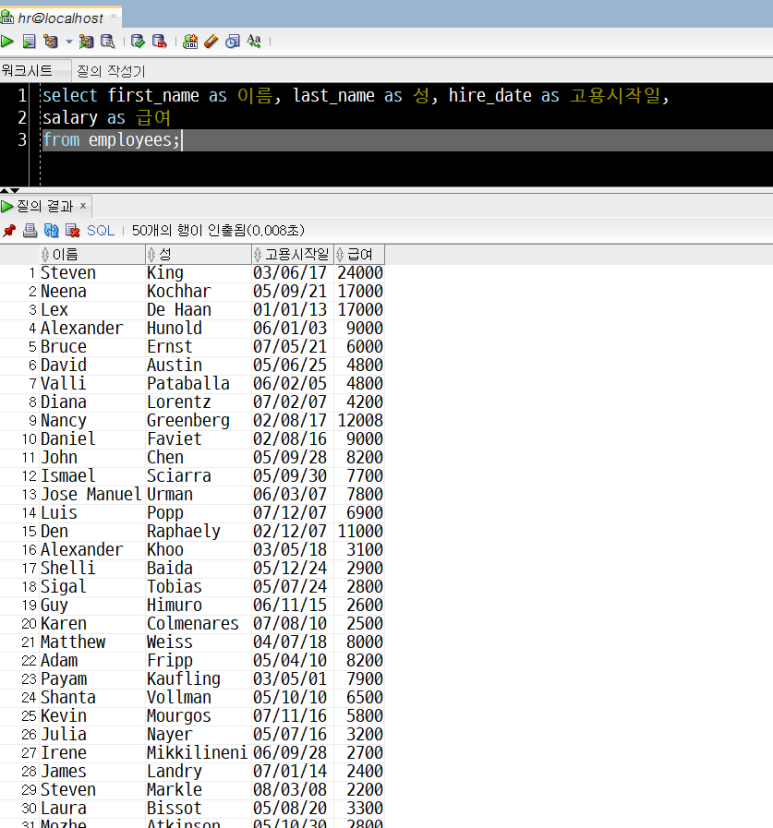
검색된 결과 employees 테이블이 보유한 직원의 성명과 고용시작일(입사일), 급여 정보를 나타내 주고 있지만, 특정한 기준으로 정렬되지 않았습니다.
만약 고용시작일(직원의 입사일) 또는 급여와 같은 변수를 기준으로 순서대로 나열된 정보를 출력하고 싶다면 ORDER BY를 사용합니다.
3) 예시 : employees 테이블에서 employee_id, first_name, last_name, salary 컬럼의 데이터만을 출력하되, employee_id를 기준으로 오름차순 정렬하기
select employee_id, first_name, last_name, salary
from employees
order by employee_id;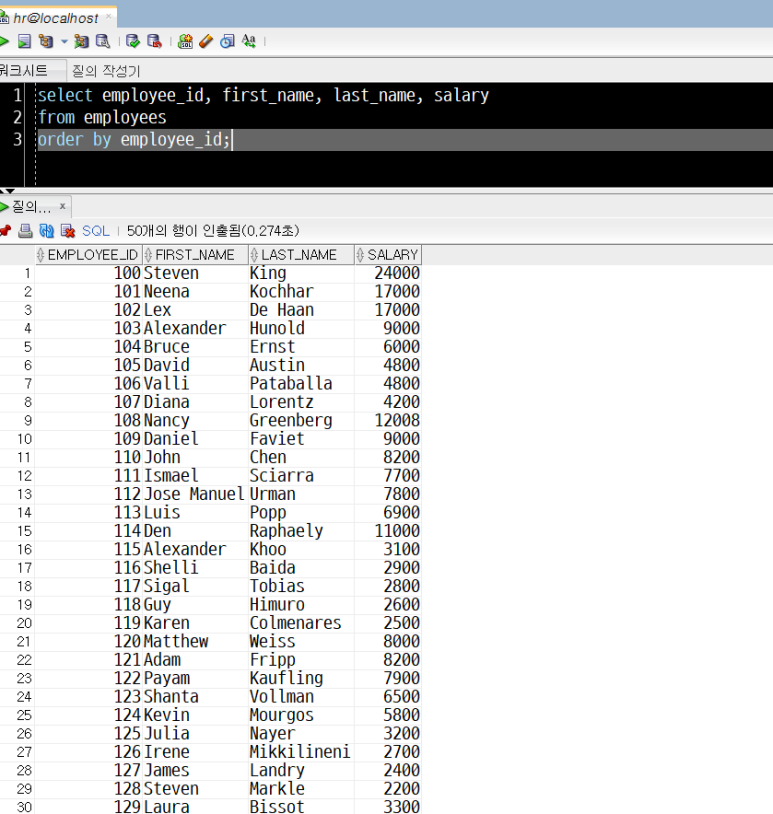
employee_id를 기준으로 오름차순 정렬된 데이터가 출력되었습니다.
4) 예시 : employees 테이블에서 사원번호(employee_id), 직원 성명(first_name, last_name), 급여(salary) 정보를 검색하되, 급여(salary)를 기준으로 오름차순 정렬하여 보기
select employee_id as 사원번호, first_name as 이름, last_name as 성, salary as 급여
from employees
order by salary;
여러 변수(컬럼)들 중 '급여'를 기준으로 검색 결과가 오름차순 정렬되어 출력된 모습입니다. 우리는 132번 TJ Olson 직원이 2100으로 가장 적은 급여를 받고 있고, 2700의 급여를 받는 139번 John Seo 직원의 경우 Irene Mikkilineni와 급여가 같다는 것도 이전보다 더 빠르게 알 수 있게 되었습니다.
반대로, 동일한 데이터를 조회하되 직원들 중 가장 많은 급여를 받는 사람 순서로 조회하고 싶다면 내림차순(desc) 정렬을 사용하면 될 것입니다.
5) 예시 : employees 테이블에서 사원번호(employee_id), 직원 성명(first_name, last_name), 급여(salary) 정보를 검색하되, 급여(salary)를 기준으로 내림차순 정렬하여 보기
select employee_id as 사원번호, first_name as 이름, last_name as 성, salary as 급여
from employees
order by salary desc;

이번에는 반대로 가장 많은 급여(salary)를 받는 순서대로 출력되었습니다.
6) 예시 : 2개 이상의 컬럼을 기준으로 데이터 정렬하기
employees 테이블에서 직원 성명(first_name, last_name), 고용시작일(hire_date), 급여(salary) 정보를 검색하되, 고용시작일(hire_date)과 급여(salary)를 기준으로 오름차순 정렬하여 보기
2개 이상의 컬럼을 기준으로 ORDER BY 정렬할 경우, 먼저 정렬할 기준이 되는 컬럼 순서대로 입력해 줍니다.
다음의 SQL 문장을 입력한 후 Ctrl+Enter를 눌러 실행합니다.
select first_name as 이름, last_name as 성, hire_Date as 고용시작일, salary as 급여
from employees
order by hire_date, salary;

조회된 데이터는
i. 먼저 고용시작일(hire_date) 오름차순으로 정렬된 뒤
ii. 같은 날 입사한 사원들의 경우, 급여의 오름차순으로 정렬되었습니다.
조회된 데이터의 3,4,5,6번행 직원들은 같은 날인 2002년 6월 7일에 입사하여 hire_date가 같습니다.
이들은 급여가 낮은 직원에서 높은 직원의 순서로 정렬되었음을 확인할 수 있습니다.
이와 같은 ORDER BY 정렬은 데이터를 좀 더 일목요연하게 볼 수 있도록 합니다.
* 데이터가 아주 많은 경우에는, ORDER BY 대신 인덱스(index) 기능을 사용하여
DBMS에의 부담을 덜어 주기도 한다고 합니다.
GROUP BY (1) : 기본 및 예제 - 데이터그룹화, 그룹별로 집계된 정보의 검색 (ex. 부서별 급여평균, 국가별 인구총계, 직급별 최대임금, ...)
GROUP BY는 각종 집계함수, 그룹함수와 함께 쓰이며 그룹화된 정보를 제공합니다.
'OO별 정보'처럼 데이터를 그룹으로 나누어, 그룹별로 집계된 정보를 출력하고 비교할 때 GROUP BY가 사용됩니다.
- 부서별 급여 평균을 구하시오
- 국가별 인구 총계를 구하시오
- 성별 최대 임금
- 부서별 수당의 표준편차
...
따라서, GROUP BY 함수는 "그룹별 정보"를 조회하는 용도이므로,
위계가 다른 非집계 정보와 함께 조회하기 어렵습니다.
1. GROUP BY 함수와 함께 쓰이는 몇 가지 집계함수
(* 아래의 예시 외에도 다양한 집계함수가 있습니다.)
|
집계함수
|
용도
|
|
max(컬럼이름)
|
최대값
|
|
min(컬럼이름)
|
최소값
|
|
median(컬럼이름)
|
중앙값
|
|
sum(컬럼이름)
|
합계
|
|
avg(컬럼이름)
|
평균
|
|
variance(컬럼이름)
|
분산
|
|
stddev(컬럼이름)
|
표준편차
|
|
count(컬럼이름)
|
관측값(row) 수
|
2. GROUP BY로 그룹별로 집계된 정보를 조회하기
1) 기본식
GROUP BY는 반드시 집계함수, 그룹함수와 함께 사용해야 합니다.
GROUP BY로는 GROUP BY의 기준이 된 컬럼 외에는 다른 일반 컬럼을 조회하기 어렵습니다.
select 집계함수A(컬럼이름1), 집계함수B(컬럼이름2), ...
from 테이블이름
group by 컬럼이름Z;GROUP BY 다음으로는 그룹으로 묶을 기준 변수(컬럼) 이름을 입력해 줍니다.
2개 이상의 컬럼을 기준으로 그룹화할 수도 있습니다.
ex1. 연도별, 국가별 인구수 총계 비교 : 연도와 국가를 기준으로 그룹화
ex2. 부서별, 성별 임금 비교 : 부서와 성별을 기준으로 그룹화
select 컬럼이름Z, 컬럼이름Y, 집계함수A(컬럼이름1), 집계함수B(컬럼이름2), ...
from 테이블이름
where 조건절
group by 컬럼이름Z, 컬럼이름Y, ...
having 그룹조건절
order by 컬럼이름Z, ... ;조금 더 복잡한 SQL 문장 : WHERE 조건절, HAVING 그룹조건절, ORDER BY 정렬 구문과 함게 사용될 경우 GROUP BY의 위치는 WHERE 다음, HAVING 전의 자리입니다.
- WHERE 조건절 : 대상이 되는 데이터를 한번 조건에 맞추어 필터링합니다.
- GROUP BY : 조건에 맞지 않는 row는 빼버린, 필터링된 대상들을 특정 컬럼을 기준으로 그룹핑합니다.
- HAVING : 그룹에 대한 조건절. 그룹 중 조건에 맞는 그룹만 남깁니다.
- ORDER BY : 마지막으로, 적절한 컬럼 또는 집계함수 결과값을 기준으로 정렬합니다.(보통 GROUP BY 기준이 되는 컬럼을 기준으로 정렬하는 경우가 많습니다)
2) 예제: employees 테이블에서 부서별 최고 급여, 최저 급여, 평균 급여의 검색
부서(department_id)별 최고/최저/평균 급여(salary)를 검색하려면 GROUP BY를 사용해야 합니다.
- 조회하려는 데이터 : max(salary), min(salary), avg(salary)
- 그룹핑 기준: department_id
- 데이터가 속한 테이블 : employees
이를 바탕으로 SQL 문장을 구성하면 아래와 같습니다.
(1) 최소의 구성
select department_id, max(salary), min(salary), avg(salary)
from employees
group by department_id;위 SQL 문장을 입력하고, Ctrl+Enter를 통해 실행하면 아래와 같은 결과물이 나타납니다.

부서번호(department_id)별 max(salary), min(salary), avg(salary)가 출력되었습니다.
하지만 컬럼 이름이 집계함수와 변수 이름 그대로 집계되어 한눈에 보기가 어렵고,
특히 급여평균(avg(salary))의 경우에는 소숫점 아래 수십자리까지 출력되어 있으며,
데이터가 어느 컬럼을 기준으로 하든 정렬이 되어 있지 않습니다.
- Alias를 이용해 컬럼 이름에 별칭을 달아주고,
- ROUND함수를 이용해 avg(salary)를 소수점 1째짜리까지 반올림한 결과로 나타내고
- ORDER BY를 이용해 부서번호 기준으로 데이터를 정렬해줄 필요가 있습니다.
(2) 응용 : 별칭, 결과값의 반올림, 정렬
- Alias를 이용한 컬럼 별칭 부여
- ROUND함수를 이용하여 결과값을 소수점 1째 자리까지 반올림하여 표기
- ORDER BY를 이용해 부서번호 기준으로 데이터를 정렬
select department_id as 부서번호,
max(salary) as 최대급여,
min(salary) as 최소급여,
round(avg(salary), 1) as 평균급여
from employees
group by department_id
order by department_id;위 SQL 문장을 Ctrl+Enter로 실행하면 아래와 같은 결과가 나타납니다.
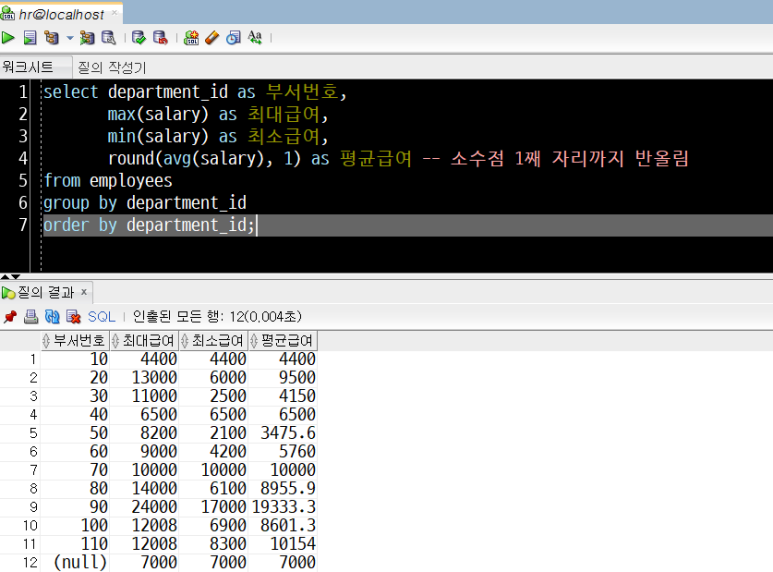
- 각 컬럼이 별칭으로 나타나 있고,
- 평균급여는 소수점 아래 1째 자리까지만 반올림되어 표기되었으며,
- 부서번호를 기준으로 오름차순 정렬되었습니다.
보다 깔끔하게 정리된 모습입니다.
(3) 응용 : 집계함수 결과값 기준의 정렬
집계함수를 기준으로 결과값을 정렬하는 것도 가능합니다.
만약 위 (2)의 예시에서 반올림된 평균급여를 기준으로 정렬한다면 아래와 같이 SQL 문장을 구성할 수 있습니다.
select department_id as 부서번호,
max(salary) as 최대급여,
min(salary) as 최소급여,
round(avg(salary), 1) as 평균급여
from employees
group by department_id
order by round(avg(salary), 1);
좀 복잡해 보입니다. 이것을 좀 더 간단하게, ORDER BY 부분을 별칭으로 간소화할 수 있습니다.
WHERE, GROUP BY, HAVING과 달리,
ORDER BY는 Alias로 정의한 별칭을 입력해도 동일한 정렬 결과를 얻을 수 있습니다.
select department_id as 부서번호,
max(salary) as 최대급여,
min(salary) as 최소급여,
round(avg(salary), 1) as 평균급여
from employees
group by department_id
order by 평균급여;

평균급여를 기준으로 오름차순 정렬된 동일한 결과를 얻었습니다.
※ 주의 : WHERE, HAVING, GROUP BY에는 별칭을 사용할 수 없습니다.
3) 예제: employees 테이블에서 직책별 직원 수, 최대급여, 최소급여, 평균급여를 소수점 아래 첫째 자리까지 구하기
- 조회하려는 데이터 : 직책별 직원수, 최대급여, 최소급여, 평균급여(* 소수점 아래 1째자리까지)
- 그룹화 : job_id
- 테이블 : employees
- 정렬 : job_id을 기준으로 정렬해 봅니다.
select job_id as 직책,
count(*) as 직원수,
max(salary) as 최대급여,
min(salary) as 최소급여,
round(avg(salary), 1) as 평균급여
from employees
group by job_id
order by 직책;
각 직책별 직원 수, 각 직책을 가진 직원들의 최대급여, 최소급여, 평균급여가 조회되었습니다.
같은 데이터를 '최대급여'가 높은 순에서 낮은 순으로(내림차순) 정렬할 수도 있습니다.
select job_id as 직책,
count(*) as 직원수,
max(salary) as 최대급여,
min(salary) as 최소급여,
round(avg(salary), 1) as 평균급여
from employees
group by job_id
order by 최대급여 desc;

결과 데이터에서 '최대급여' 컬럼을 기준으로 내림차순 정렬되었습니다.
'Structured Query Language > Oracle SQL' 카테고리의 다른 글
| Oracle SQL 기본_05 (0) | 2023.04.20 |
|---|---|
| Oracle SQL 기본_04 (0) | 2023.04.20 |
| Oracle SQL 기본_03 (0) | 2023.04.20 |
| Oracle SQL 기본_02 (0) | 2023.04.19 |
| SQL 문제 - null 값 처리하기 (0) | 2023.04.17 |



