LIKE (2) : 응용 - 대소문자 구분 없이 '■로 시작하는', '■로 끝나는', '■를 포함한' ●자 글자 검색하기 (문자 검색)
앞서 LIKE(1)에서 우리는 대소문자 구분 없이 특정한 문자가 포함된 문자열이 있는 레코드를 검색하려면, 두 개의 WHERE LIKE, 또는 두 개의 WHERE NOT LIKE 를 연결하여 검색했었습니다.
예시> hr 연습계정, employees 테이블에서 이름에 알파벳 E(또는 e)가 들어가는 직원을 검색하기
select * from employees
where first_name like '%E%'
or first_name like '%e%';일일히 대문자, 소문자의 경우를 고려하자니 번거롭습니다.
UPPER, LOWER, INITCAP 과 같은 함수 중 하나를 사용하면, 더 복잡한 문자열 조건에도 대소문자 구별에 영향을 받지 않고 대응할 수 있게 됩니다.
1. 대소문자 구분의 영향을 받지 않는 레코드 검색 :
LIKE와 UPPER, LOWER, INITCAP을 함께 활용
1) 기본식
아래 UPPER, LOWER, INTICAP의 경우 3가지 중 어느 것을 선택하더라도 결과는 같습니다.
select 컬럼이름1, 컬럼이름2, ...
from 테이블이름
where upper(컬럼이름Z) like upper('조건');select 컬럼이름1, 컬럼이름2, ...
from 테이블이름
where lower(컬럼이름Z) like lower('조건');select 컬럼이름1, 컬럼이름2, ...
from 테이블이름
where initcap(컬럼이름Z) like initcap('조건');단, WHERE 조건절에서 2번 들어가는 함수는 모두 UPPER-UPPER- LOWER-LOWER, INITCAP-INITCAP 쌍이 서로 동일해야 합니다.
- 검색할 컬럼의 데이터
- 문자열 검색 조건
위 2가지, LIKE 앞뒤에 놓이는 값을 전부 대문자/ 전부 소문자/ 앞글자만 대문자... 등 동일한 규칙으로 바꾸어 준 다음에 검색하는 원리입니다.
따라서 기존 데이터가 대문자나 소문자가 어떻게 섞여 저장되어 있든 대소문자의 구별에 구애받지 않고 원하는 검색 결과를 얻을 수 있습니다.
2) 예제 : emp 테이블에서, 이름에 알파벳 A(a)가 포함되는 직원들의 empno, ename, sal 출력하기
UPPER, LOWER, INITCAP 중 어떤 것을 선택해도 결과는 같습니다.
select empno, ename, sal
from emp
where lower(ename) like lower('%a%');
이름에 A(a)가 포함된 모든 직원들의 empno, ename, sal 컬럼이 출력되었습니다.
'a'로 검색했지만, 대소문자 구별 없이 이름에 A만 포함된 직원들도 검색되었습니다.
4) 예제 : emp 테이블에서, 이름이 N으로 끝나고 총 5자리 알파벳으로 구성된 직원들의 empno, ename, sal 출력하기
UPPER, LOWER, INITCAP 중 어떤 것을 선택해도 결과는 같습니다.
글자수 제한이 없는 % 대신 '_(언더바)'로 글자수 제한이 걸려 있어도 마찬가지로 대소문자 여부에 구애받지 않습니다.
select empno, ename, sal
from emp
where lower(ename) like lower('____N%');이름이 N으로 끝나고, 5글자인 조건을 만족하는 직원(ALLEN)의 정보가 출력되었습니다.
NVL, NVL2 (1) : NULL을 특정한 값으로 치환하는 NULL 변환 함수 (ex. NULL을 0으로 치환하여 조회)
null은 말 그대로 데이터가 없는 상태이기 때문에, null이 포함된 산술연산의 결과도 전부 null이 되어버립니다.
하지만 null을 0이나 '없음' 과 같은 값으로 치환하여 검색결과로 조회해야 하는 경우가 많습니다.
ex.
- 수당이 null 이면 0으로 간주한다.
- 직업이 null 이면 무직으로 간주한다.
- 전화번호가 null인 직원은 회사 대표전화로 일괄 표시한다.
...
NVL 함수, NVL2 함수를 사용하면 원본 데이터를 변형하지 않고도 null을 특정한 값으로 일괄 치환하여 조회 수 있습니다.
1. NVL, NVL2 함수의 정의와 표현
1) NVL, NVL2 함수의 정의
|
종류
|
오라클 SQL에서의 표현
|
비고
|
|
NVL
|
NVL(컬럼이름, null 대체값)
|
null 인 레코드만 대체값으로 변경
|
|
NVL2
|
NVL2(컬럼이름,
null이 아닌 경우 출력할 값,
null일 경우 대체할 값)
|
null 이 아닌 레코드도 특정한 값으로 대체하여 출력할 수 있음
|
NVL2 함수도 NVL 함수처럼 이용할 수 있지만, 좀 더 사용할 수 있는 폭이 넓습니다.
null이 아닌 레코드도 특정한 값으로 대체할 수 있기 때문입니다.
(예컨대 null이 아니면 1, null이면 0으로 치환하여 null 여부를 코드화할 수도 있을 것입니다)
2) 기본식 : 컬럼 내의 null 인 레코드의 특정 값을 대체하는 경우
(1) NVL 함수
select NVL(컬럼이름1, NULL대체값), 컬럼이름2, ...
from 테이블이름;ex. NVL(comm, 0) : comm이 null이면 0, null이 아니면 comm 값이 출력됩니다.
(2) NVL2 함수
select NVL2(컬럼이름1, NULL 아닌 경우 출력값, NULL인 경우 대체값), 컬럼이름2, ...
from 테이블이름;ex. NVL2(comm, 1, 0) : comm이 null이면 0, null이 아니면 1값이 출력됩니다.
ex. NVL2(comm, comm, 0) : comm이 null이면 0, null이 아니면 comm값이 출력됩니다.
2. 예제 : NVL 함수, NVL2 함수를 사용한 NULL의 치환
* 이하의 예제에서는 hr 연습계정의 employees 테이블을 사용합니다.

수당비율(commission_pct) 컬럼에 값이 있는 레코드와 null인 레코드가 혼재되어 있습니다.
1) 예제 : employees 테이블에서 직원번호, 수당비율, null을 0으로 치환한 수당비율을 조회하기
NVL 함수를 사용하여 null을 0으로 치환하는 아래와 같은 SQL문장을 구성할 수 있습니다.
select employee_id as 직원번호,
commission_pct as 수당비,
NVL(commission_pct, 0) as NVL수당비
from employees;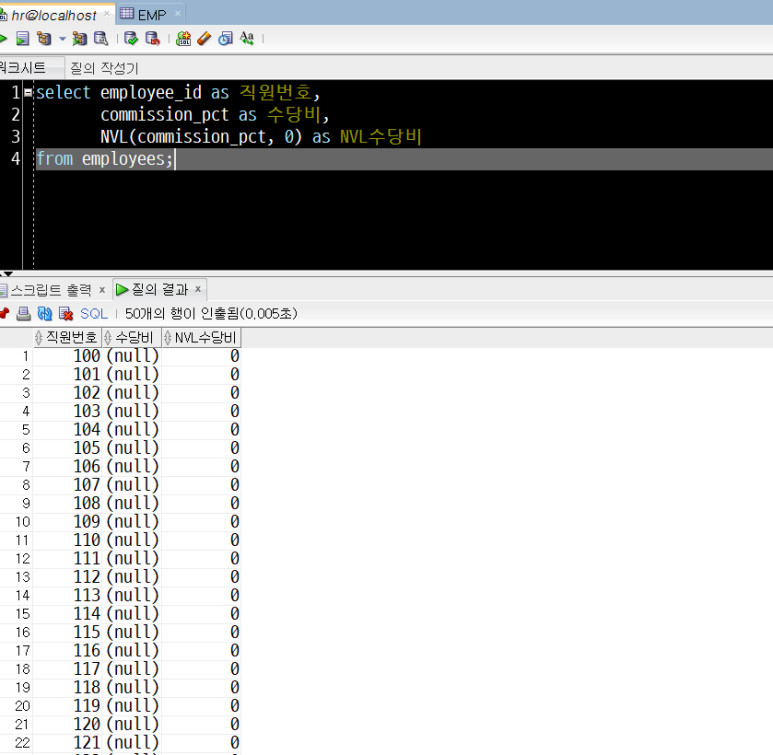
commission_pct 컬럼의 값이 null인 경우, NVL 함수를 사용해 null을 0으로 치환하여 나타내는 컬럼이 NVL 수당비 컬럼입니다.
3) 예제 : employees 테이블에서 직원번호, 수당비율, null을 0으로 치환한 수당비율, 수당 여부에 따라 '수당O/수당X'로 표시하는 컬럼을 조회하기
NVL 함수를 사용하면 null 값을 치환한 결과를 출력할 수 있습니다.
NVL2 함수를 사용하면, null 뿐만 아니라 null이 아닌 경우 또한 특정한 값으로 치환하여 조회할 수 있습니다.
NVL2 함수를 사용하여, commission_pct 컬럼이 null이 아니면 '수당O', null이면 '수당X'로 표현하는 '수당OX' 컬럼을 조회하기로 합니다.
select employee_id as 직원번호,
commission_pct as 수당비,
NVL(commission_pct, 0) as NVL수당비,
NVL2(commission_pct, '수당O', '수당X') as 수당OX
from employees;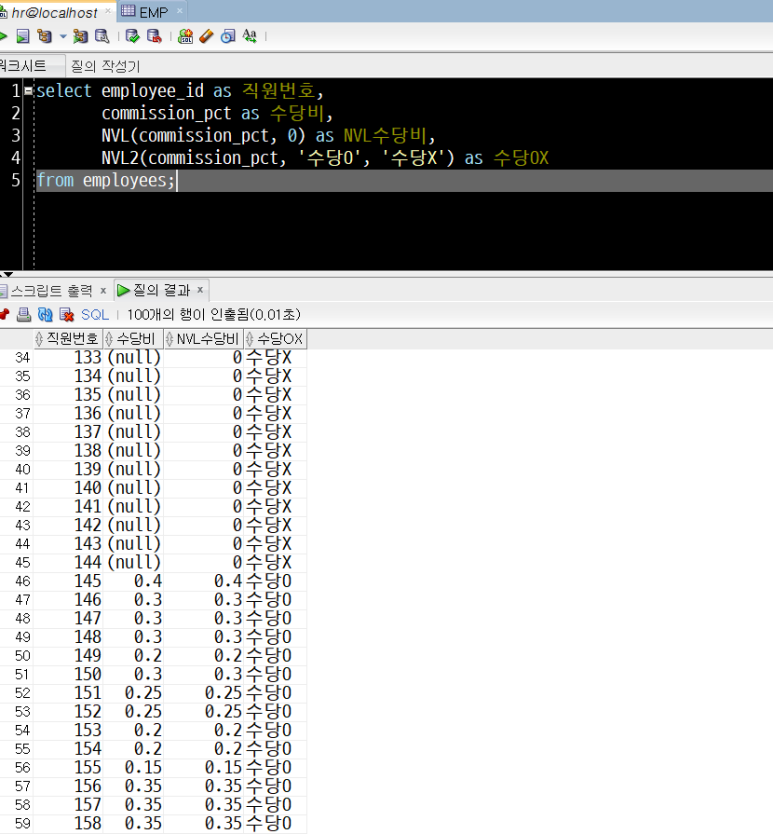
- NVL 함수를 적용한 컬럼(NVL수당비) : null인 레코드는 0으로 대체되었습니다.
- NVL2 함수를 적용한 컬럼(수당OX) : null이면 '수당X', null이 아니면 '수당O'로 표시되고 있습니다.
4) 예제 : scott 연습계정의 emp 테이블에서
ⓐ 12개월치 월급(sal*12)
ⓑ null을 0으로 치환한 수당(comm)
ⓒ 연봉(sal*12+수당)
을 검색하여 출력하기
emp 테이블에서 comm이 null인 레코드가 존재하므로, NVL 함수를 사용하여 null을 0으로 치환해 줍니다.
select sal*12 as 월급X12개월,
nvl(comm, 0) as 수당,
comm,
sal*12+nvl(comm,0) as 연봉
sal*12+comm as 연봉비교용
from emp;(비교를 위해 NVL처리하지 않은 comm의 경우도 조회합니다.) 위 SQL 문장을 Ctrl+Enter로 실행하면 아래와 같은 결과를 얻습니다.

- 수당 컬럼 : comm이 0이면 0으로 대체되었습니다.
- NVL 함수로 comm의 null을 대체한 컬럼은 null 값이 없습니다.
- NVL함수로 null을 대체하지 않고 계산한 '연봉비교용' 컬럼에는 null 데이터가 존재하는 것을 볼 수 있습니다.
CONCAT, || : 문자열 연결 함수, 컬럼 문자열 연결 연산자 - 컬럼의 값을 붙여 조회하기
두 개 이상의 컬럼을 합쳐 하나의 문자열 컬럼으로 표시하거나, 컬럼 몇 가지의 데이터를 이용해 완성된 문장을 출력해야 하는 경우가 있습니다.
- 두 문자열을 연결하고 싶다. 문자열을 병합하고 싶다. 어떤 문자들을 합쳐서 한 개의 컬럼으로 만들고 싶다...
ex.
고객 성명 데이터를 이용해 '어서오세요, OOO님. 환영합니다' 인사말 메시지를 자동으로 만들기
고객의 성과 이름을 합쳐 한 개의 full name 컬럼으로 만들기
...
hr 연습계정에서 가장 쉬운 예로, 성명이 first_name과 last_name 2개 컬럼으로 분리되어 있습니다. 따라서 직원의 풀네임(full name)을 1개의 컬럼으로 만드려면 두 개 컬럼의 정보를 연결하여 출력해야 합니다.
이 때 사용되는 것이 문자열 연결 연산자(||) 또는 CONCAT 함수입니다.

1. 문자열 연결 함수·연결 연산자의 정의와 그 표현
1) 기본 원리
(1) 2개의 문자열을 연결
|
구분
|
결과
|
|
CONCAT('가나', '다라')
|
가나다라
|
|
가나||다라
|
가나다라
|
(2) 2개 컬럼의 문자열을 연결
|
구분
|
|
|
CONCAT(컬럼이름1,컬럼이름2)
|
컬럼1내용컬럼2내용
|
|
컬럼이름1 || 컬럼이름2
|
컬럼1내용컬럼2내용
|
2) 3개 이상의 문자열 또는 컬럼을 연결하는 경우
(1) 기본 구성
|
구분
|
결과
|
|
CONCAT('가나',CONCAT('다라','마바'))
|
가나다라마바
|
|
가나||다라||마바
|
가나다라마바
|
CONCAT 함수는 반드시 2개의 문자열 또는 컬럼만 연결할 수 있게 되어 있으므로, 문자열 또는 컬럼의 수가 3개 이상일 경우 늘어나는 수만큼 CONCAT을 중복해서 써야 하는 번거로움이 있습니다. 따라서, 3개 이상의 문자열을 연결할 경우 연결 연산자 '||'를 사용하는 것이 간편합니다.
(2) 응용 : 문자를 띄어서(공백, 스페이스) 연결하기
|
구분
|
결과
|
|
CONCAT('가나',CONCAT(' ','다라'))
|
가나 다라
|
|
가나||' '||마바
|
가나 다라
|
공백은 ' '(작은따옴표 안에서 스페이스) 로 하여, 문자열처럼 연결 연산자로 연결합니다.
마찬가지로 CONCAT의 경우 2번 이상 써야 하는 번거로움이 있어, 3개 이상의 문자 연결 시 이하의 예제에서는 가급적 '||'를 사용합니다.
2. 예제 : 연결 연산자를 사용한 문자열 연결
* 이하의 예제에서는 hr 연습계정의 employees 테이블을 사용합니다.
1) employees 테이블에서 이름(first_name)과 성(last_name)을 연결하여, full name을 1개의 'name'이라는 컬럼으로 출력하기(성과 이름을 띄어서 구분하도록 합니다)
(1) 연결 연산자 || 를 사용하는 경우
first_name
' '
last_name
위 3개를 연결연산자 '||'로 연결해 줍니다.
select first_name||' '||last_name as name
from employees;

이름(first_name)과 성(last_name)이 합쳐진 풀네임이 1개 컬럼(name)으로 출력되었습니다
(2) CONCAT 함수를 사용하는 경우
위와 동일한 문제를 연결연산자 '||'가 아닌 CONCAT 함수를 사용해 문자열을 연결하는 경우입니다.
first_name
' '
last_name
문자열과 컬럼이 총 3개이므로, CONCAT 함수를 2번 써 주어야 합니다.
※ 주의 : CONCAT(first_name, ' ', last_name) 과 같은 표현은 잘못된 표현입니다.
CONCAT 함수의 인수는 2개여야 합니다.
select concat(first_name, concat(' ', last_name)) as name
from employees;
2) employees 테이블에서 이름(first_name)과 성(last_name)을 연결하여,
'안녕하세요, OOO OOO님, 가입을 환영합니다' 문구가 출력되는 컬럼 만들기
'안녕하세요, '
first_name 컬럼
' '
last_name 컬럼
'님, 가입을 환영합니다'
총 5개의 컬럼과 문자열을 연결연산자 ||로 연결합니다.
select '안녕하세요, '||first_name||' '||last_name||'님, 가입을 환영합니다'
from employees;
안녕하세요, first_name last_name님, 가입을 환영합니다.
3) employees 테이블에서 이름(first_name), 성(last_name), 이메일(email)을 연결하여, 'OOO OOO의 이메일 주소는 XXX@tenebris.com입니다' 문구가 출력되는 컬럼 만들기
- 이메일 주소는 모두 소문자로 표기하기
first_name 컬럼
' '
last_name 컬럼
'의 이메일 주소는 '
email컬럼(*lower 함수를 이용해 소문자로 변환)
'@tenebris.com 입니다'
6개의 문자열과 컬럼을 연결연산자 ||로 연결하여 출력해야 합니다.
select first_name||' '||last_name||'의 이메일 주소는 '
||lower(email)||'@tenebris.com입니다' as 이메일안내문구
from employees;
first_name last_name의 이메일 주소는 xxxx@tenebris.com 입니다.
LENGTH, LENGTHB : 문자열의 길이·문자열 Byte를 알아내거나, 문자열 길이 조건을 제한할 때 사용하는 함수
HELLO'는 5글자입니다. '안녕하세요'도 5글자입니다.
하지만 'HELLO'는 5byte, '안녕하세요'는 10byte입니다. 통상적으로 알파벳 1자는 1byte, 한글 1자는 2btye이기 때문입니다(* 어떤 경우에는 한글 1자당 3byte를 부여하기도 합니다).
Oracle SQL Developer에서 입력된 문자열의 길이(몇 글자인가?) 또는 용량(몇 byte인가?)을 구하려고 할 때, LENGTH 또는 LENGTHB 함수를 사용하게 됩니다.
또한, LPAD, RPAD, TRIM 등 다른 함수와 결합하여 응용할 경우에는 글자 수 N자로 제한하는 등 글자수/글자용량 제한을 걸고자 할 때도 LENGTH, LENGTHB를 사용할 수 있습니다.
|
SQL 문장에서의 표현
|
의미
|
비고
|
|
LENGTH(X)
|
X의 길이=X의 글자 수
|
글자 자리수. 알파벳도 한글도 동일한 1자리
|
|
LENGTHB(X)
|
X의 byte수
|
알파벳 1자당 1byte, 한글 1자당 2byte
(* 한글 1자당 3byte인 경우도 존재함)
|
2) 기본식 : LENGTH, LENGTHB 함수로 특정 문자열, 특정 컬럼의 문자열 글자수/byte수를 출력하려는 경우
(1) 가상테이블 DUAL을 이용해 임의의 문자열의 글자수 또는 byte수를 출력하는 경우의 기본식
select length('문자열1'), lengthb('문자열2'),...
from dual;위 식은 문자열1의 글자수, 문자열2의 byte수를 구하게 됩니다.
(2) 특정한 컬럼의 문자열들에 대한 글자수 또는 byte수를 출력하는 경우의 기본식
select length(컬럼이름1), lengthb(컬럼이름2),...
from 테이블이름;위 식은 컬럼1의 레코드들의 글자수, 컬럼2가 가진 레코드들의 byte수를 컬럼 형태로 출력하게 됩니다.
2. 예제 : LENGTH함수, LENGTHB 함수의 사용
1) 가상테이블 DUAL 을 이용한 문자열의 글자 수, byte 수 출력
(1) 예제 : 문자열 'ABC'와 '하이'의 길이와 byte수를 각각 구하기
select length('ABC'), lengthb('ABC'),
length('하이'), lengthb('하이')
from dual;
ABC - 3글자, 3byte
하이 - 2글자, 4byte
(2) 예제 : 문자열 '하이'와 '안녕하세요'의 길이와 byte수를 각각 구하시오
select length('하이'), lengthb('하이'),
length('안녕하세요'), lengthb('안녕하세요')
from dual;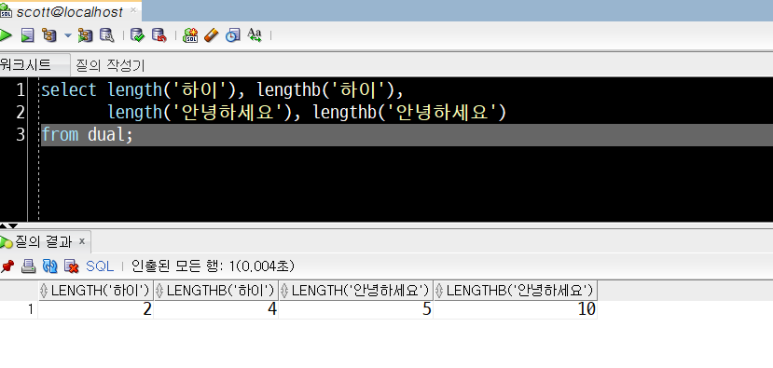
하이 - 2글자, 4byte
안녕하세요 - 5글자, 10byte
한글은 글자당 2byte임을 다시금 확인할 수 있습니다.
2) 예제 : 특정 컬럼의 문자열 길이, byte수 출력
- emp 테이블의 ename, ename컬럼이 가진 레코드의 문자열 길이와 byte수를 출력하기
문자열 레코드를 포함한 컬럼에 대해서도 길이, byte수를 컬럼의 형태로 출력하는 것이 가능합니다.
length, lengthb 함수에 ename 컬럼을 투입한 SQL문장을 만듭니다.
select ename, length(ename), lengthb(ename)
from emp;
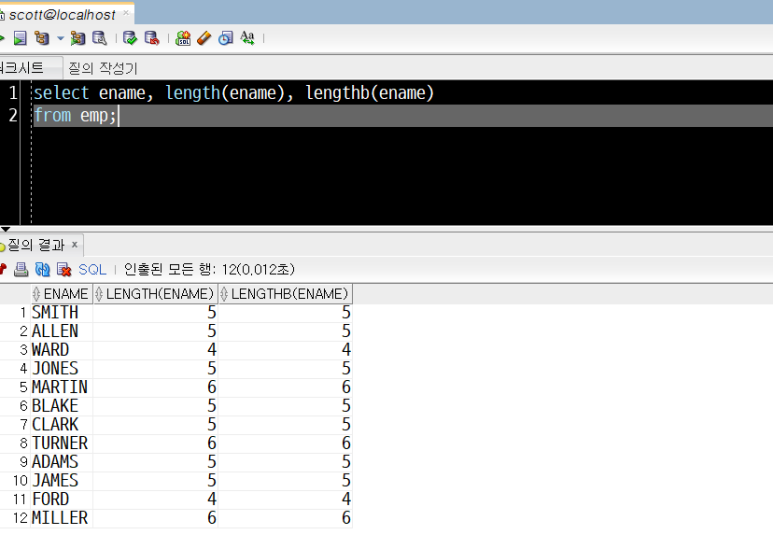
emp 테이블이 가진 직원들의 이름(ename), 이름의 글자 수(length(ename)), 이름의 byte수(lengthb(ename))가 각각 컬럼으로 출력되었습니다.
모두 영어 알파벳으로 되어있어서 길이와 byte수가 같게 나옵니다.(* 알파벳 1자는 1byte)
3) 예제 : 글자수를 제한하여 검색할 시 조건을 달 때 LENGTH 함수를 사용하기
- emp 테이블에서 이름이 6자 이상인 직원의 이름, 이름 길이와 byte수 조회하기
WHERE절에 LENGTH 함수를 이용하여 글자수에 대한 조건을 달아 줍니다.
select ename, length(ename), lengthb(ename)
from emp
where length(ename)>=6;
이름이 6자 이상인 조건을 만족하는 3명(MARTIN, TURNER, MILLER)의 레코드만 출력되었습니다.
SUBSTR : 문자열 잘라내기 함수. (ex. 비밀번호 앞 2자리만 자르기, 주민등록번호 앞 7자리만 자르기, 끝에서부터 N자리만 자르기 등)
문자열 전체가 아니라, 잘라낸 일부만 필요한 경우가 많습니다.
- 주민등록번호 앞자리 여섯자리만 잘라서 보고 싶다.
- 휴대전화번호 뒷자리 4자리만 필요하다.
- 이름 중간의 3글자 정도만 필요하다.
...
이런 경우, SUBSTR 함수를 사용하면 원하는 문자열을 필요한 글자수만큼 잘라내어 사용할 수 있습니다.
SUBSTR에 LENGTH, LPAD, RPAD와 같은 함수를 함께 사용하기도 하여, '01040******', '890723-2******' 같은 결과물을 얻기도 합니다.
1. SUBSTR 함수의 정의와 표현
1) SUBSTR 함수의 정의와 이해
|
SQL 문장에서의 표현
|
의미
|
|
SUBSTR('문자열X', 기준자릿수N, 잘라낼문자수M)
|
문자열X의 N번째 인덱스(자리)에서부터 M개 글자수만큼 왼쪽 → 오른쪽 방향으로 자르기
|
|
SUBSTR(컬럼이름A, 기준자릿수N, 잘라낼문자수M)
|
컬럼A에 속한 레코드들을 각각 N번째 인덱스(자리)에서부터 M개 글자수만큼 왼쪽 → 오른쪽 방향으로 자르기
|
위의 표를 보고 바로 이해하기가 쉽지 않았습니다. 그림으로 이해하는 편이 더 빠를 수 있습니다.
아래의 그림은 임의의 N자리 문자열의 인덱스 나타낸 것입니다.

SUBSTR에서의 인덱스(INDEX)란, 문자열에서 그 문자의 위치(일종의 좌표)를 뜻합니다. 한 글자 당 두 개의 인덱스를 가집니다.
- 양수 인덱스(N) : 앞에서부터 N번째 글자
- 음수 인덱스(-N) : 뒤에서부터 N번째 글자
두 인덱스 중 어느 것을 SUBSTR 함수에 넣어도 결과는 동일합니다.
이 위치를 기준으로 왼쪽→오른쪽 방향으로 지정된 M개 만큼의 문자만 잘라내는 것입니다.
2) 기본식
(1) 가상테이블 DUAL로 임의의 문자열 일부를 잘라내는 경우의 기본식
select substr('문자열X', 기준자릿수N, 잘라낼문자수M), ...
from dual;위 식은 문자열X를 인덱스 N자리로부터 M개 글자만큼 잘라낸 결과를 출력합니다.
(2) 특정한 컬럼에 속한 레코드들의 문자열 일부를 일괄된 규칙으로 잘라내어 출력하는 경우의 기본식
select substr(컬럼이름A, 기준자릿수N, 잘라낼문자수M), ...
from dual;위 식은 컬럼A의 레코드들이 가진 문자열을 일괄적으로 인덱스 N자리로부터 M개 글자만큼 잘라낸 결과를 컬럼의 형태로 출력합니다.
2. 예제 : SUBSTR 함수를 사용하여 문자열 중 필요한 부분만 잘라내기
1) 가상테이블 DUAL을 사용하는 경우
(1) 예제 : 문자열 'HADOOP', 'HADOOP'의 앞에서부터 4번째 자리에서부터 3글자, 'HADOOP'의 뒤에서 5번째 자리로부터 2글자를 출력하기
인덱스(기준자릿수N)는 다음을 참고해 주세요.

문제에서 원하는 부분의 문자만 잘라내는 SQL 문장은 다음과 같습니다.
select 'HADOOP',
substr('HADOOP', 4, 3),
substr('HADOOP', -5, 2)
from dual;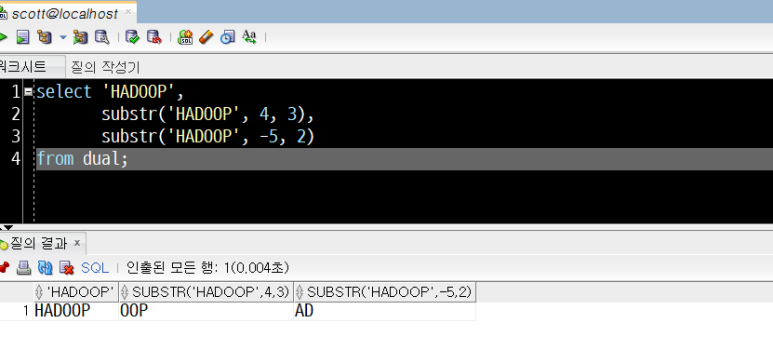
- HADOOP의 앞에서부터 4번째 자리(O)로부터 3글자(OOP)
- HADOOP의 뒤에서 5번째 자리(A)로부터 2글자(AD)
(2) 문자열 '910101-4567999'에서 앞 6자리만 출력하기.
총 14자리의 문자이므로, 첫 글자의 인덱스는 1 또는 -14가 될 것입니다.
select '910101-4567999',
substr('910101-4567999', 1, 6),
substr('910101-4567999', -14, 6)
from dual;인덱스가 1인 경우, -14인 경우 모두 동일한 결과(910101)입니다.
2) 예제 : 특정한 컬럼에 속한 레코드의 문자열을 같은 규칙으로 일괄적으로 잘라내는 경우
- emp 테이블의 ename 컬럼, ename컬럼의 문자열을 첫번째 자리부터 3글자, 뒤에서 3째자리부터 3글자 출력하기
- 첫번째 자리부터 3글자만 자르기 : substr(ename, 1, 3)
- 뒤에서부터 3번째 자리부터 3글자만 자르기 : substr(ename, -3, 3)
따라서 구성된 SQL 문장은 아래와 같습니다.
select ename,
substr(ename, 1, 3),
substr(ename, -3, 3)
from emp;
ename 컬럼의 각 레코드 문자열을
- 앞글자 3자리
- 뒷글자 3자리
만 잘라서 각각 컬럼으로 출력한 모습을 볼 수 있습니다.
TRIM, LTRIM, RTRIM : 문자열 양끝/왼쪽/오른쪽의 공백을 제거하는 함수 (* 불필요한 space, tab, enter 제거)
TRIM, LTRIM, RTRIM 함수는 문자 양끝(시작 부분, 끝 부분)에 있는 공백들을 제거해 주는 함수입니다.
(* 공백 : 스페이스(space), 탭(tab), 엔터(enter) 등)
임의의 문자열은 물론, 특정한 컬럼에 대하여서도 사용할 수 있습니다.
TRIM 기능은 공백의 존재로 인해서 다른 데이터로 간주되는 등의 자잘한 오류를 미연에 방지할 수 있게 합니다.
※ 주의 : TRIM, LTRIM, RTRIM은 문자열 중간에 포함되어 있는 공백은 제거하지 않습니다.
1. TRIM, LTRIM, RTRIM의 정의와 차이
1) 임의의 문자열X를 투입하는 경우
|
SQL문장에서의 표현
|
기능
|
비고
|
|
TRIM('문자열X')
|
문자열X의 양 끝 공백을 모두 제거
|
문자열 중간에 포함되어있는 공백은 제거하지 않음
|
|
LTRIM('문자열X')
|
문자열X의 왼쪽(시작부분) 공백만 제거
|
|
|
RTRIM('문자열X')
|
문자열X의 오른쪽(끝부분) 공백만 제거
|
2) 특정한 컬럼의 레코드가 가진 문자열들에 일괄 적용하는 경우
|
SQL문장에서의 표현
|
기능
|
비고
|
|
TRIM(컬럼이름A)
|
컬럼A가 가진 레코드들에서 양 끝 공백을 모두 제거
|
문자열 중간에 포함되어있는 공백은 제거하지 않음
|
|
LTRIM(컬럼이름A)
|
컬럼A가 가진 레코드들에서 왼쪽(시작부분) 공백만 제거
|
|
|
RTRIM(컬럼이름A)
|
컬럼A가 가진 레코드들에서 오른쪽(끝부분) 공백만 제거
|
아래의 예시들을 통해 이상의 내용을 좀 더 직관적으로 이해할 수 있습니다.
2. 예제 : TRIM, LTRIM, RTRIM 사용 결과의 비교
1) 예제 : TRIM 이전/이후 문자열 중간의 공백 비교
- ' 바가바드 ', ' 바 가 바 드 ' 두 개의 문자열에 대하여 TRIM 적용
select trim(' 바가바드 '),
trim(' 바 가 바 드 ')
from dual;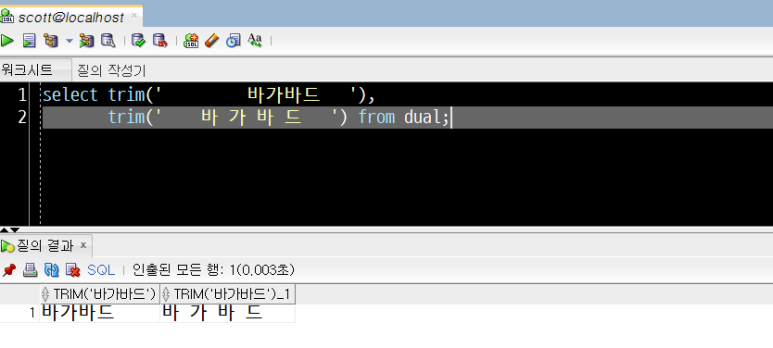
둘 모두 좌우 양쪽의 공백이 모두 제거되었지만, 두 번째 '바 가 바 드'의 경우 문자열 내부의 공백은 제거되지 않았습니다.
바가바드
바 가 바 드
2) 예제 : TRIM, LTRIM, RTRIM의 비교
- ' 바 가 바 드 ' 두 개의 문자열에 대하여 TRIM, LTRIM, RTRIM 적용 결과를 비교하기
select trim(' 바 가 바 드 '),
ltrim(' 바 가 바 드 '),
rtrim(' 바 가 바 드 ')
from dual;

- TRIM : 좌우 양쪽의 공백이 모두 삭제되었습니다.
바 가 바 드
- LTRIM : 왼쪽의 공백만 제거되고, 오른쪽의 공백은 남아있습니다.
바 가 바 드
- RTRIM : 오른쪽 공백만 제거되고, 왼쪽 공백은 남아있습니다.
바 가 바 드
'Structured Query Language > Oracle SQL' 카테고리의 다른 글
| Oracle SQL 기본_06 (1) | 2023.04.20 |
|---|---|
| Oracle SQL 기본_05 (0) | 2023.04.20 |
| Oracle SQL 기본_03 (0) | 2023.04.20 |
| Oracle SQL 기본_02 (0) | 2023.04.19 |
| Oracle SQL 기본_01 (0) | 2023.04.18 |



