LPAD, RPAD (1) 기본 : 문자열의 자릿수를 맞추어 Padding 문자로 공백 채우기 (ex. 코드 자릿수 맞추기, 특수문자로 채우기 등)
일정한 규칙 하에, 특정 컬럼의 데이터들을 각각 N개 글자가 되도록 통일하거나, 일정 기준에 모자라는 나머지 글자를 특정한 문자로 채워넣어 일정한 길이의 문자열로 만들어야 하는 경우가 있습니다.
예를 들어,
- 10, 020, 300, 054... 등으로 표기된 지역코드들을 '000XXX'와 같은 6자리 문자로 자릿수를 맞추어 표기하기
- 문자열 앞 또는 뒤에 지정한 문자를 덧붙여 일정한 길이의 문자열 결과로 만들기
이럴 때, 특정한 문자(Padding 문자)로 지정한 글자수까지 채워주는 기능을 수행하는 함수가 LPAD, RPAD 함수입니다.
* LPAD, RPAD 함수는 SUBSTR와 함께 사용하면 시너지 효과를 발휘합니다.
이는 LPAD, RPAD (2) 응용 편에서 다루겠습니다.
- 주민등록번호 앞자리 7자리만 잘라서 나타내고, 나머지는 별표로 가리기
- 전화번호 뒷자리 4자리만 표시하고, 나머지는 별표로 가리기
- 개인정보 보호/노출 방지를 위해 일부 내용 가리기
위와 같은 내용들은 LPAD, RPAD와 함께 SUBSTR 함수가 사용됩니다.
1. LPAD, RPAD의 정의와 표현
1) LPAD, RPAD의 정의
(1) 임의의 문자열에 대하여 LPAD, RPAD를 적용하는 경우
※ 주의 : LPAD, RPAD에서는 출력될 결과 문자열의 길이(LENGTH)가 아니라 문자 byte수(LENGTHB)를 지정합니다. 따라서, 문자열X나 Padding문자열Y에 한글을 섞어 쓰는 경우 결과가 되는 문자 길이에 차이가 존재할 수 있습니다.
|
오라클 SQL에서의 표현
|
의미
|
결과
|
|
LPAD('문자열X', 결과값의 총byte수N, 'Padding문자열Y')
|
- 문자열X의 왼쪽에,
- 총 N byte가 될 때까지,
- 문자열Y를 반복하여 채워 출력
|
YYY..YX
(전체 N byte)
|
|
RPAD('문자열X', 결과값의 총byte수N, 'Padding문자열Y')
|
- 문자열X의 오른쪽에,
- 총 N byte가 될 때까지,
- 문자열Y를 반복하여 채워 출력
|
XYY...Y
|
* N은 문자길이(length)가 아니라 문자 byte수(lengthb)
이해를 돕기 위해 그림으로 예시를 들어보겠습니다.
ex. 'TARJA' 문자열이 전체 N byte가 될 때까지 오른쪽에 특수문자 '*'를 채워넣고 출력
= RPAD('TARJA', N, '*')가 될 것입니다.

N byte = 전체 결과의 byte 수를 의미함을 유의해 주세요.
알파벳 1글자의 경우 1byte이므로 글자수=byte수 입니다.
하지만 한글의 경우 1글자 당 2byte이기 때문에, 문자열 길이(length)와 문자열 byte수(lengthb)가 달라집니다.
(* 본 포스팅 후반부에 영어 / 한글 PAD 시 LENGTH, LENGTHB 차이 비교 예제가 있습니다.)
(2) 특정한 컬럼의 레코드들에 대하여 일괄적으로 LPAD, RPAD를 적용하는 경우
|
오라클 SQL에서의 표현
|
의미
|
결과
|
|
LPAD(컬럼이름A, 결과값의 총byte수N, 'Padding문자열Y')
|
- 컬럼A의 모든 레코드 왼쪽에,
- 총 N byte가 될 때까지,
- 문자열Y를 반복하여 채워 출력
|
레코드AYY...Y
(전체 N byte)
|
|
RPAD(컬럼이름A, 결과값의 총byte수N, 'Padding문자열Y')
|
- 컬럼A의 모든 레코드 오른쪽에,
- 총 N byte가 될 때까지,
- 문자열Y를 반복하여 채워 출력
|
YY...Y레코드A
(전체 N byte)
|
컬럼을 대상으로 LPAD, RPAD를 적용하면, LPAD 또는 RPAD가 적용된 컬럼 형태의 결과를 얻을 수 있습니다
2) 기본식
(1) 가상테이블 DUAL을 사용해 임의의 문자열에 LPAD, RPAD 적용 시
select LPAD('문자열X', 결과값의 총byte수N, 'Padding문자열Y'),
RPAD('문자열X', 결과값의 총byte수N, 'Padding문자열Y'), ...
from dual;문자열X의 왼쪽 또는 오른쪽에, 결과 문자열이 총 N byte가 될 때까지 문자열Y를 채워서 출력하는 구문입니다.
(2) 특정한 컬럼의 레코드들에 일괄적으로 LPAD, RPAD 적용시
select LPAD(컬럼이름A, 결과값의 총byte수N, 'Padding문자열Y'),
RPAD(컬럼이름A, 결과값의 총byte수N, 'Padding문자열Y'), ...
from 테이블이름;특정한 컬럼A의 레코드들의 왼쪽 또는 오른쪽에, 결과 문자열이 총 N byte가 될 때까지 문자열Y를 채워서 컬럼의 형태로 출력하는 구문입니다.
2. 예제 : LPAD, RPAD 함수의 사용
1) 가상테이블 DUAL을 사용한 임의의 문자에 Padding문자 덧붙이는 경우
(1) 예제 : LPAD와 RPAD의 비교
- 'hello' 문자열이 전체 7byte가 되도록, 문자 *를 오른쪽 또는 왼쪽에 넣어 공백을 채우기
Padding 문자를 왼쪽에 채우면 : LPAD
Padding 문자를 오른쪽에 채우면 : RPAD
select lpad('hello', 7, '*'),
rpad('hello', 7, '*')
from dual;

LPAD('hello', 7, '*') = **hello
RPAD('hello', 7, '*') = hello**
알파벳 1글자당 1byte입니다. 전체 길이는 7byte(알파벳7자)로, hello를 제외한 남는 자리가 모두 '*'로 채워졌습니다.
(2) 예제 : LPAD, RPAD 비교
- 'Mahari' 문자열이 전체 10byte가 되도록, 문자 *를 오른쪽 또는 왼쪽에 넣어 공백을 채우기
select lpad('Mahari', 10, '*'),
rpad('Mahari', 10, '*')
from dual;'Mahari' 문자열에 LPAD 또는 RPAD를 적용하여, 두 결과를 비교해 보도록 합니다.
*을 덧붙인 결과는 각각 10byte가 되어야 합니다.

LPAD('Mahari', 10, '*') = ****Mahari
RPAD('Mahari', 10, '*') = Mahari****
알파벳 1글자당 1byte입니다. 전체 길이는 10byte(알파벳10자)로, Mahari(6byte, 알파벳 6자)를 제외한 남는 4byte가 모두 '*'로 채워졌습니다.
(3) 예제 : 한글과 영어의 LPAD 결과 비교
- 문자열 'hello', 'ANJ', 'MT', '강' 각각이 전체 길이가 7byte가 되도록 문자열 왼쪽에 특수문자 *를 채워 결과 비교하기
'hello', 'ANJ', 'MT'는 영어 알파벳이므로 1자당 1byte입니다.
그러나 '강'은 한글이므로 1자당 2byte입니다.
- 출력될 결과값은 7byte로 모두 동일
- padding 문자도 모두 '*'로 동일
4개 문자열의 LPAD 결과를 비교하기 위해, 아래와 같이 SQL 문장을 구성합니다.
select lpad('hello', 7, '*'),
lpad('ANJ', 7, '*'),
lpad('MT', 7, '*'),
lpad('강', 7, '*')
from dual;

lpad('hello', 7, '*') = **hello
lpad('ANJ', 7, '*') = ****ANJ
lpad('MT', 7, '*') = *****MT
lpad('강', 7, '*') = *****강
'강'의 경우 한글이므로 1자당 2byte입니다. 4개 결과 모두 7byte이지만, 한글이 포함된 '*****강'의 경우 문자 길이는 영어 문자열의 경우보다 짧습니다.
(4) 예제 : 한글과 영어의 LPAD, RPAD 결과 비교
- 패딩문자가 각각 영어 / 한글인 경우
- '마하리' 문자열에 총 10byte 결과가 되도록
ⓐ 문자열 왼쪽에 'B' 채우기
ⓑ 문자열 오른쪽에 'A' 채우기
ⓒ 문자열 왼쪽에 '가' 채우기
ⓓ 문자열 오른쪽에 '가' 채우기
위 ⓐ~ⓓ 경우에 각각 LPAD, RPAD를 적용하여 출력하는 SQL 문장은 아래와 같습니다.
select lpad('마하리', 10, 'B'),
rpad('마하리', 10, 'A'),
lpad('마하리', 10, '가'),
rpad('마하리', 10, '가')
from dual;문자열도 한글, Padding 문자열도 영어 / 한글로 상이하므로, 결과값이 4개 모두 10byte로 동일하더라도 문자열 길이에는 차이가 있을 것을 예상할 수 있습니다.
Ctrl+Enter로 위 문장을 실행하면, 오라클 SQL 디벨로퍼는 아래와 같은 결과물을 출력합니다.

lpad('마하리', 10, 'B') = BBBB마하리
rpad('마하리', 10, 'A') = 마하리AAAA
lpad('마하리', 10, '가') = 가가마하리
rpad('마하리', 10, '가') = 마하리가가
위와 같이 10byte로 모두 같은 4개 결과물의 문자열 길이에 차이가 나는 이유는, 한글 1글자당 2byte이기 때문입니다.
2) 특정 컬럼의 레코드 문자열에 Padding 문자를 덧붙이기
* 이하의 예제에서는 scott 연습계정의 emp, dept 테이블을을 사용합니다.
(1) 예제 : emp 테이블의 sal 컬럼에 총 9byte가 되도록 오른쪽 또는 왼쪽에 'HA' 문자로 채운 결과를 출력하기
컬럼에 LPAD 또는 RPAD를 적용하는 것도 마찬가지 원리가 적용됩니다.
- 컬럼 : sal
- 총 결과 byte : 9 byte
- Padding 문자 : HA
이를 바탕으로 SQL 문장을 구성하면 아래와 같습니다.

총 9byte가 되도록 기존 문자열(sal컬럼의 레코드 값)의 왼쪽 또는 오른쪽에 'HA' 문자열이 채워졌습니다.
- 2,3,4,5...번 행의 경우 : 'HAHAH1760', '1760HAHAH'로 HA 일부가 잘려 있기도 합니다.
9 byte를 채울 때까지 Padding 문자를 순서대로 채워넣기 때문에, Padding 문자가 여러 글자일 경우 총 byte 수 제한에 의해서 잘리기도 합니다.
(2) 예제 : dept 테이블의 deptno 컬럼에서 아래 2가지 값을 출력하기
ⓐ 총 5자리로 표시하되, deptno 왼쪽 남는 자리를 0으로 채우기
ⓑ 총 5자리로 표시하되, deptno 오른쪽 남는 자리를 A로 채우기
각각 Padding 문자가 0 또는 A이고, 결과값이 5자리입니다. 영어와 숫자는 1자리=1byte이므로 아래와 같이 SQL 문장을 구성합니다.
select lpad(deptno, 5, '0'),
rpad(deptno, 5, 'A')
from dept;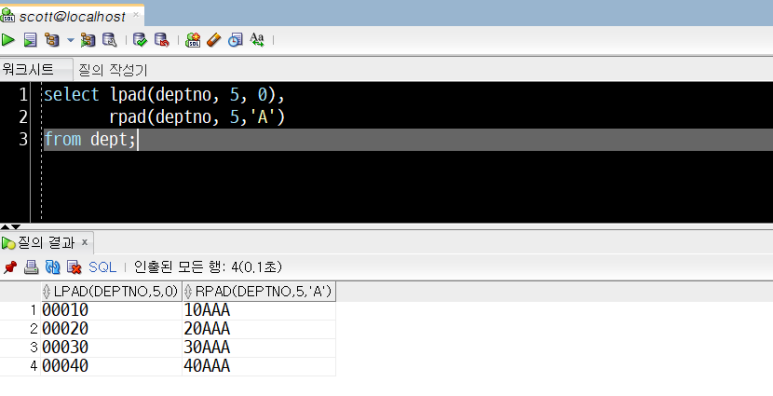
lpad(deptno, 5, '0') = 000■■
rpad(deptno, 5, 'A') = ■■AAA
형식의 결과값이 컬럼의 형태로 출력되었습니다.
LPAD, RPAD (2) 응용 예제 : SUBSTR로 문자열을 잘라서 나머지 채우기, 문자 일부 가리기 (ex. 전화번호 뒷자리만 표시, 성명 일부만 표시)
LPAD, RPAD를 사용하면 일정한 길이로 문자 자릿수(byte수)를 맞추고, 남는 자리는 특정한 문자열로 채워서 출력하는 기능을 수행할 수 있었습니다.
* LPAD,RPAD를 SUBSTR 함수와 함께 사용하면 :
- 문자의 일부만 잘라서
- 나머지는 특정 문자(*)로 채워서
- 일정한 길이의 결과물로 표시
하는 작업이 가능합니다.
ex.
- 당첨자 발표 시 개인정보 보호
- 이름의 앞자리 일부만 표시하기
- 주민등록번호 앞자리 7자리만 잘라서 일괄적으로 나타내고, 나머지는 별표로 가리기
- 전화번호 뒷자리 4자리만 표시하고, 나머지는 별표로 가리기
- 개인정보 보호/노출 방지를 위해 일부 내용 가리기
1) 예제 : 'Andrea Lloyd' 영문 문자열
ⓐ 문자열 원본 출력
ⓑ 'Andrea Lloyd'를 첫 글자부터 4글자만 자르기
ⓒ 'Andrea Lloyd'를 첫 글자부터 4글자만 자르고, 전체 12byte가 될 때까지 나머지 자리는 오른쪽에 *로 채우기
- SUBSTR 함수 : 첫 글자부터 4글자만 문자열 잘라내기
- RPAD 함수 : 전체 12byte가 될 때까지 특정한 문자로 오른쪽에 채우기
이를 바탕으로 ⓐ~ⓒ를 구하는 SQL 문장을 구성하면 아래와 같습니다.
select 'Andrea Lloyd',
substr('Andrea Lloyd', 1, 4),
rpad(substr('Andrea Lloyd', 1, 4), 12,'*')
from dual;위 SQL 문장을 Ctrl+Enter로 실행하면, Oracle SQL Developer는 아래와 같은 결과를 출력합니다.
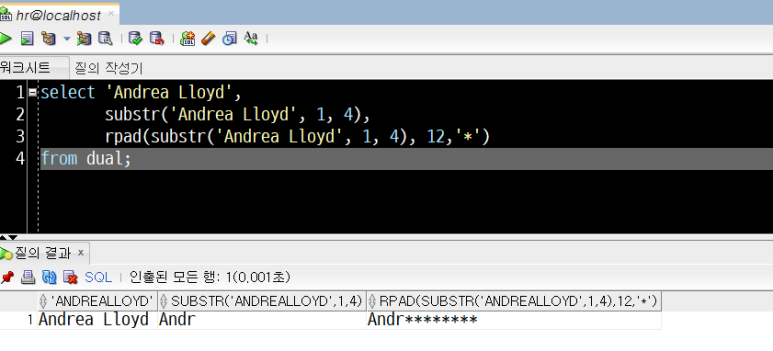
- SUBSTR 결과 : Andr (1째 자리부터 4글자)
- SUBSTR에 RPAD를 적용한 결과 : Andr******** (총 12byte, 영어 알파벳 12자)
문자열(특정인의 성명) 앞자리 4글자만 노출하고, 나머지는 '*(별표)'로 가려진 결과가 나타났습니다.
SUBSTR와 RPAD를 함께 사용하면 성명, 주민등록번호, 이메일 주소, 주소, id 등 개인정보를 보호해야 하는(정보의 일부만 노출하고 나머지는 가려야 하는) 상황에 대응할 수 있게 됩니다.
2) 예제 : 'Marisa Song' 영문 문자열
ⓐ 문자열 원본 출력
ⓑ 'Marisa Song'를 첫 글자부터 3글자만 자르기
ⓒ 'Marisa Song'를 첫 글자부터 3글자만 자르고, 전체 7byte가 될 때까지 나머지 자리는 오른쪽에 *로 채우기
- SUBSTR 함수 : 첫 글자부터 3글자만 문자열 잘라내기
- RPAD 함수 : 전체 7byte가 될 때까지 특정한 문자로 오른쪽에 채우기
이를 바탕으로 ⓐ~ⓒ를 구하는 SQL 문장을 구성하면 아래와 같습니다.
select 'Marisa Song',
substr('Marisa Song', 1, 3),
rpad(substr('Marisa Song', 1, 3), 7,'*')
from dual;

오라클 SQL 디벨로퍼가 출력한 결과입니다.
- SUBSTR 결과 : Mar (1째 자리부터 3글자)
- SUBSTR에 RPAD를 적용한 결과 : Mar**** (총 7byte, 영어 알파벳 7자)
이전 예제에서의 Andrea Lloyd와 마찬가지 결과가 나왔습니다
3) 예제 : '안드레아 로이드' 한글 문자열
ⓐ 문자열 원본 출력
ⓑ '안드레아 로이드'를 첫 글자부터 4글자만 자르기
ⓒ '안드레아 로이드'를 첫 글자부터 4글자만 자르고, 전체 12byte가 될 때까지 나머지 자리는 오른쪽에 *로 채우기
예제1)과 SUBSTR, RPAD 사용 조건은 같지만 이번에는 함수에 투입할 문자열이 한글(1자당 2byte)입니다.
입력하는 SQL 문장의 식은 동일하지만, 결과의 문자 길이에 차이가 있을 것입니다.
- SUBSTR 함수 : 첫 글자부터 4글자만 문자열 잘라내기
- RPAD 함수 : 전체 12byte가 될 때까지 특정한 문자로 오른쪽에 채우기
이를 바탕으로 ⓐ~ⓒ를 구하는 SQL 문장을 구성하면 아래와 같습니다.
select '안드레아 로이드',
substr('안드레아 로이드', 1, 4),
rpad(substr('안드레아 로이드', 1, 4), 12,'*')
from dual;
- SUBSTR 결과 : 안드레아 (1째 자리부터 4글자)
- SUBSTR에 RPAD를 적용한 결과 : 안드레아**** (총 12byte, 한글 4자+특수문자 4자)
따라서, 한글 문자열에 LPAD 또는 RPAD를 적용하면 문자 길이가 예상과 다를 수 있습니다.
Padding문자가 '*'이 아니라 한글이라면 이 역시 결과 문자열 길이에 영향을 미칩니다.
* 이하의 예시에서는 scott 연습계정의 emp 테이블을 사용합니다.
4) 예제 : emp 테이블의 ename 컬럼에 SUBSTR, RPAD 사용하기
ⓐ 컬럼 원본 출력
ⓑ 컬럼이 보유한 각 레코드 문자열의 첫번째 자리에서 3글자만 자르기
ⓒ 컬럼 문자열의 1째 자리에서 3글자만 자르고, 전체 5byte가 될 때까지 나머지 자리는 오른쪽에 *로 채우기
컬럼 원본(ⓐ), SUBSTR(ⓑ), SUBSTR와 RPAD(ⓒ) 사용결과를 비교하는 것입니다.
select ename,
substr(ename, 1, 3) as SUBSTR,
rpad(substr(ename, 1, 3), 5, '*') as RPAD
from emp;
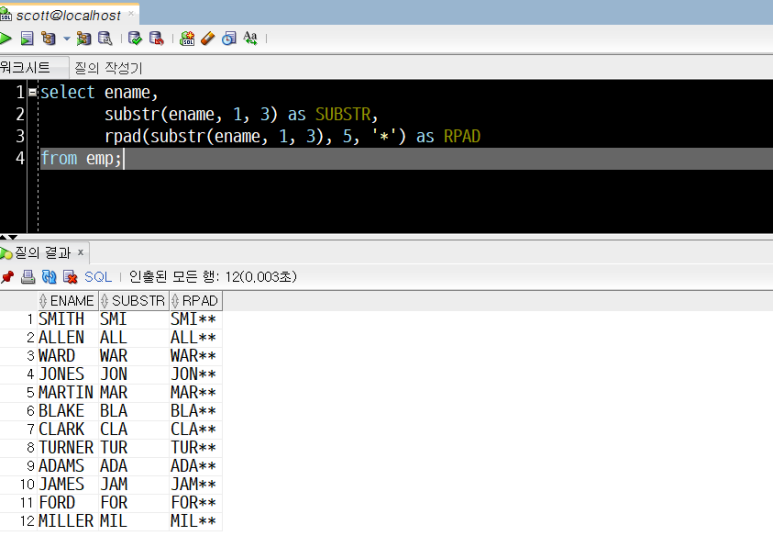
- SUBSTR 결과 : 각 컬럼의 값을 1째 자리부터 3자만 잘라낸 문자열(영어 3자)
- SUBSTR에 RPAD를 적용한 결과 : 각 컬럼 값에 5byte가 될 때까지 * 붙이기
(총 5byte, 영어3자 + 특수문자 2자)
LPAD, RPAD (3) 응용 예제 : SUBSTR, LENGTHB 함수와 함께 사용하는 경우 (ex. 결과 문자열의 길이가 달라지는 가변 길이, 문자 치환)
LPAD와 RPAD에 SUBSTR, LENGTHB를 함께 쓰면,
투입하는 문자열의 길이에 따라서 결과로 출력되는 Padding이 적용된 문자열의 byte수(길이)도 달라지도록 만들 수 있습니다.
LPAD, RPAD (2) 응용 예제를 통하여서는,
- 주어진 문자열을 일정한 글자수만큼 자르고
- 일정한 byte수로 통일된 결과를 내놓되
- 공백(빈 자리)은 padding 문자로 채워진
결과를 얻을 수 있었습니다.

결과값인 RPAD 컬럼의 레코드를 살펴보면
- 총 5byte(5글자) 범주 내에서
- ENAME의 앞자리 3자리(SUBSTR)를 쓰고
- 그 오른쪽의 빈 자리에 '*'를 채워 넣은 것을 알 수 있습니다.
출력된 결과값들은 모두 5byte(영문 5글자)로 일정했습니다.
Q. 그렇다면, 출력되는 문자열의 길이가 투입한 문자열의 길이에 따라 달라지도록 할 수는 없을까요? 즉, 일부 글자만 남기고 나머지는 '*' 같은 문자로 규칙적으로 일괄 치환할 수 있을까요?
→ 가능합니다.
LPAD와 RPAD에 SUBSTR, LENGTHB를 함께 쓰면 위와 같이, 투입하는 문자열의 길이에 따라서 결과로 출력되는 Padding이 적용된 문자열의 byte수(길이)도 달라지도록 만들 수 있습니다.
예를 들어 동일한 예제에서 문자열 앞 3글자는 노출하고, 나머지 글자는 *로 치환할 수도 있습니다.

위 이미지에서 RPAD에 출력된 문자열의 byte수(영문자 길이)는 ENAME의 byte 수(영문자 길이)와 같습니다. ENAME에서 글자수가 다르면, RPAD에서의 글자수도 달라지는 것입니다.
아래에서 몇 가지 예시를 통해 LPAD 또는 RPAD, SUBSTR, LENGTHB를 함께 사용할 경우의 결과를 비교하겠습니다.
1) 예제 : 'Andrea Lloyd' 문자열에 대하여 다음을 각각 출력하기
ⓐ 문자열 첫글자부터 2글자만 잘라낸 값
ⓑ 주어진 문자열의 byte 수
ⓒ 주어진 문자열의 앞 2자리만 남기고, 나머지는 모두 별표(*)로 치환하기
즉, ⓒ를 통하여 아래와 같이 기존 문자열과 byte수가 같은 결과값을 원하는 것입니다.
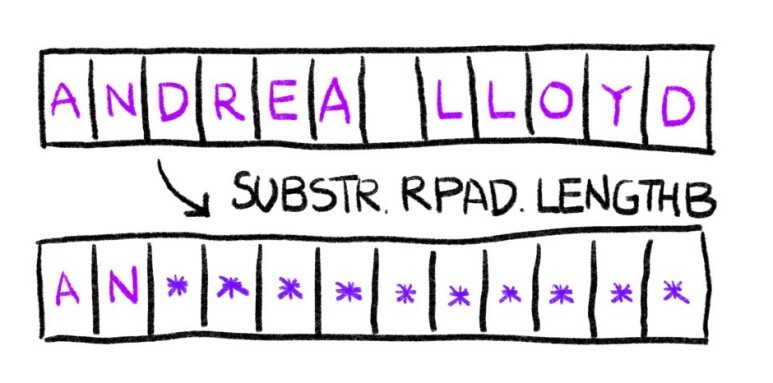
- SUBSTR : 'Andrea Lloyd' 앞 2글자 자르기
- LENGTHB : 'Andrea Lloyd' byte 수
- RPAD : SUBSTR, LENGTHB, RPAD함수를 사용하여 'Andrea Lloyd'앞 2글자만 남기고 나머지 영문 12글자는 '*'로 치환하기
select substr('Andrea Lloyd', 1, 2) as SUBSTR,
lengthb('Andrea Lloyd') as LENGTHB,
rpad(substr('Andrea Lloyd', 1, 2), lengthb('Andrea Lloyd'), '*') as RPAD
from dual;
- 투입 문자열 : Andrea Lloyd
- SUBSTR 결과 : An
- 투입 문자열 byte수 : 12
- SUBSTR, LENGTHB, RPAD 사용결과 : An********** (12 byte)
적어도 영문, 특수문자, 공백에 대해서는 1글자=1byte이므로,
출력된 결과물은 투입된 문자열과 byte 수 뿐만 아니라 글자 수도 같습니다.
2) 예제 : '안드레아 로이드' 한글 문자열에 대하여 다음을 각각 출력하기
ⓐ 문자열 첫글자부터 2글자만 잘라내기
ⓑ 주어진 문자열의 byte 수
ⓒ 주어진 문자열의 앞 2자리만 남기고, 나머지는 모두 별표(*)로 치환하되, 최종 결과값의 길이는 주어진 문자열 byte수 만큼으로 제한
그렇다면 한글 문자열을 투입했을 경우(1자당 2byte) 어떤 결과가 나오는가에 대해서 비교하여 살펴보겠습니다.
- SUBSTR : '안드레아 로이드' 앞 2글자 자르기
- LENGTHB : '안드레아 로이드' byte 수
- RPAD : SUBSTR, LENGTHB, RPAD함수를 사용하여 '안드레아 로이드'앞 2글자만 남기고, '안드레아 로이드'의 byte 수 범위 내에서 나머지는 '*'로 치환하기
select substr('안드레아 로이드', 1, 2) as SUBSTR,
lengthb('안드레아 로이드') as LENGTHB,
rpad(substr('안드레아 로이드', 1, 2), lengthb('안드레아 로이드'), '*') as RPAD
from dual;
- 투입 문자열 : 안드레아 로이드
- SUBSTR 결과 : 안드
- 투입 문자열 byte수 : 15
- SUBSTR, LENGTHB, RPAD 사용결과 : 안드*********** (15 byte, 한글 2자+특수문자 11자=13자)
투입 문자열 또는 Padding문자에 한글이 섞여 있으면, 결과 문자열의 길이가 byte 수와 다를 수 있음을 반드시 유의해야 합니다.
* 이하의 예제에서는 scott 연습계정의 emp 테이블을 사용합니다.
3) 예제 : emp테이블 ename 컬럼에 대하여 다음을 출력하기
ⓐ 컬럼의 각 레코드 첫글자부터 2글자만 잘라낸 값
ⓑ 컬럼의 각 레코드 문자열의 byte 수
ⓒ 컬럼에 속한 각 문자열의 3자리만 남기고, 나머지는 모두 별표(*)로 치환하되, 최종 결과값의 길이는 주어진 문자열 byte수 만큼으로 제한
select ename,
substr(ename, 1, 3) as SUBSTR,
lengthb(ename) as LENGTHB,
rpad(substr(ename, 1, 3), lengthb(ename), '*') as RPAD
from emp;
ENAME 컬럼의 문자열 byte수(길이)에 따라,
SUBSTR-LENGTH-RPAD가 적용되어 'RPAD' 컬럼에 출력된 결과값이 달라졌습니다.
- ENAME 앞 3자리만 노출하는 것은 동일하지만,
- ENAME의 원래 byte수(영문자 길이)에 따라서 채워지는 Padding문자의 개수가 달라지는 것입니다.
DECODE 기본 및 예제 : 조건에 따라 각각 다른 값을 입력/출력하는 분기함수 (* 타 프로그래밍 언어에서의 IF ~ THEN, IFELSE 명령어)
다른 프로그래밍 언어에서 IF ~ THEN, IFELSE()로 사용되는 함수들이 있습니다.
- 특정한 조건을 만족하면 X, 조건을 만족하지 않으면 Y 출력
Oracle SQL Developer에서 이러한 분기함수의 기능을 수행하는 함수는 DECODE와 CASE입니다.
* DECODE 함수와 CASE 함수의 간략한 차이점 :
DECODE : A=B이면 X, A≠B이면 Y를 출력 (A와 B가 같은지에 대한 조건)
CASE : DECODE와 달리, A와 B 사이에 부등호 관계(크거나 작은 조건)를 처리할 때 주로 사용
1. 분기함수 DECODE의 정의 및 표현
1) DECODE 함수의 정의
|
오라클 SQL에서의 표현
|
의미
|
|
DECODE(A, B, X, Y)
|
A = B 이면 X를 출력,
A ≠ B 이면 Y를 출력
|
|
DECODE(A, B, X, C, Y, Z)
|
A = B이면 X 출력,
A = C이면 Y 출력,
A ≠ B 이고 A ≠ C이면 Z 출력
|
|
DECODE(A1, B, DECODE(A2, C, X, Y), Z)
|
A1=B이면서 A2=C이면 X 출력,
A1=B이면서 A2≠C이면 Y를 출력,
A1≠B이면 Z 출력
(DECODE 내부의 DECODE 중첩)
|
* 이때 비교하는 값인 B, C와 출력하는 값인 X,Y,Z 자리에 null도 사용할 수 있습니다.
즉,
- 컬럼A의 값이 null인지 여부를 비교(B, C)
- 특정 조건을 만족할 시 null 출력(X, Y, Z)
하는 것이 DECODE 함수에서 가능합니다.
2) 기본식과 도해
(1) A=B이면 X, A≠B이면 Y를 출력
select decode(컬럼이름A, 비교대상값B, 출력값X, 출력값Y), ...
from 테이블이름;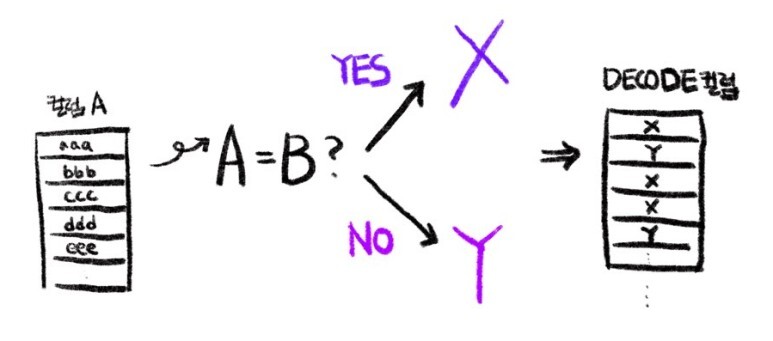
(2) A=B이면 X, A=C이면 Y, A≠B, A≠C이면 Z 출력하는 경우
select decode(컬럼이름A, 비교대상값B, 출력값X,
비교대상값C, 출력값Y, 출력값Z), ...
from 테이블이름;
(3) DECODE 함수의 중복 :
A1=B이면서 A2=C이면 X 출력,
A1=B이면서 A2≠C이면 Y출력,
A1≠B이면 Z 출력하는 경우
select decode(컬럼이름A1, 비교대상값B,
decode(컬럼이름A2, 비교대상값C, 출력값X, 출력값Y),
출력값Z), ...
from 테이블이름;
2. 예제 : 분기함수 DECODE의 사용
1) emp 테이블에서 직원성명(ename), 부서번호(deptno) 컬럼을 출력하고,
부서번호가 10번이면 '부서번호10번', 아니면 '10번아님'이라고 표기하는 'DECODE'라는 컬럼을 만들어 함께 출력하기
'A=B이면 X, 아니면 Y를 출력하기'의 경우에 해당합니다.
select ename as 직원성명,
deptno as 부서번호,
decode(deptno, 10, '부서번호10번', '10번아님') as DECODE
from emp;
2) emp 테이블에서 직원성명(ename), 직책(job), 입사일(hiredate) 컬럼을 출력하고,
직책이 'SALESMAN'이면 '세일즈맨', 아니면 'X'라고 표기하는 '세일즈맨여부'라는 컬럼을 만들어 함께 출력하기
이 역시 'A=B이면 X, 아니면 Y를 출력하기'의 경우에 해당합니다.
select ename as 직원성명,
job as 직책,
hiredate as 입사일,
decode(job, 'SALESMAN', '세일즈맨', 'X') as 세일즈맨여부
from emp;

직책(job)이 SALESMAN이면 세일즈맨, 아니면 X라고 표기하는 새로운 컬럼(세일즈맨여부)이 만들어졌습니다.
3) '2)'예제와 동일 : emp 테이블에서 직원성명(ename), 직책(job), 입사일(hiredate) 컬럼을 출력하고,
- 직책이 'SALESMAN'이면 '세일즈맨'이라고 표기하되, SALESMAN이 아닌 경우 출력할 값을 누락하고 안 쓴 '세일즈맨여부'라는 컬럼을 만들어 함께 출력하기
select decode(컬럼이름A, 비교대상값B, 출력값X, 출력값Y), ...
from 테이블이름;위 기본식에서 '출력값Y' 없이 DECODE(컬럼이름A, 비교대상값B, 출력값X)만 썼을 경우입니다.
이 경우, 직책이 SALESMAN이 아니면 출력할 값이 지정되지 않았으므로(공란이므로), 결과값이 null로 나타납니다.
select ename as 직원성명,
job as 직책,
hiredate as 입사일,
decode(job, 'SALESMAN', '세일즈맨') as 세일즈맨여부
from emp;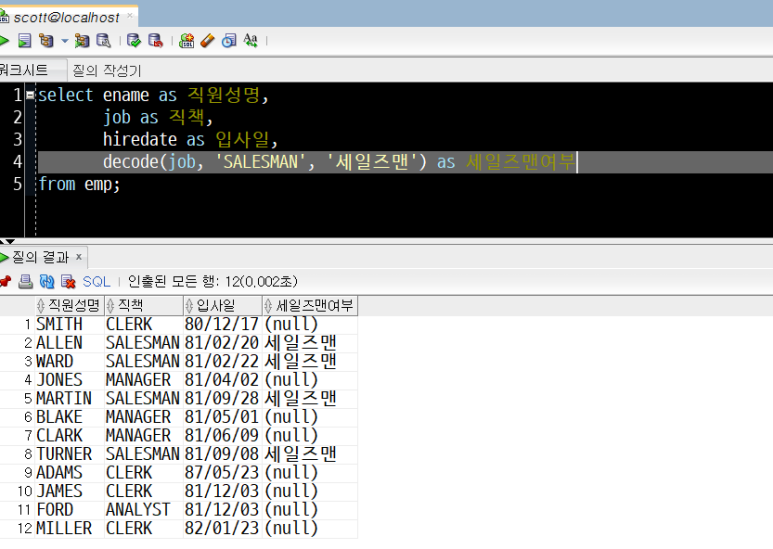
직책(job)이 SALESMAN이면 '세일즈맨'으로 지정한 값이 출력되었습니다.
하지만 SALESMAN이 아닐 경우에는 출력할 값을 입력하지 않았기 때문에, null(공란)이 된 결과가 나타났습니다.
4) emp 테이블에서 직원성명(ename), 직책(job), 입사일(hiredate) 컬럼을 출력하고,
- 직책이 'SALESMAN'이면 null, 아니면 '세일즈맨 아님'라고 표기하는 '세일즈맨여부'라는 컬럼을 만들어 함께 출력하기
이번에는 SALESMAN 이면 null이 되도록 DECODE 함수에 출력값을 입력합니다.
출력되는 결과값이 null이 되도록 하려면, 작은따옴표나 is 없이 그냥 null만 입력합니다.
select ename as 직원성명,
job as 직책,
hiredate as 입사일,
decode(job, 'SALESMAN', null, '세일즈맨 아님') as 세일즈맨여부
from emp;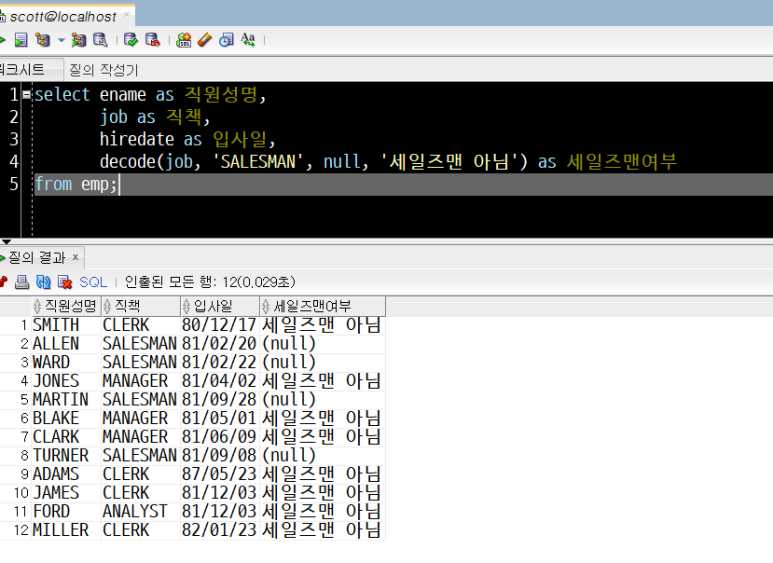
DECODE 함수는 조건에 맞는 / 조건에 맞지 않는 출력값이 null 이 되도록 출력값 X, Y, Z를 설정할 수도 있습니다.
5) emp 테이블에서 직원성명(ename), 직책(job), 입사일(hiredate), 수당(comm) 컬럼을 출력하고,
- 수당(comm)이 null이면 'X', null이 아니면 'O'라고 표기하는 '수당존재여부'라는 컬럼도 만들어 함께 출력하기
comm is null 이면 X를 출력하고, comm is not null이면 O를 출력하는 것입니다.
DECODE(comm, null, 'X', 'O') 라고 정의할 수 있습니다
select ename as 직원성명,
job as 직책,
hiredate as 입사일,
comm as 수당,
decode(comm, null, 'X', 'O') as 수당존재여부
from emp;
수당(comm)이 존재하면(not null) O, 존재하지 않으면(null) X가 출력되는 '수당존재여부'컬럼이 새로 만들어졌습니다.
6) emp 테이블에서 직원성명(ename), 부서번호(deptno)를 출력하고,
- 만약 부서번호가 입력되어있지 않다면 '부서누락', 입력되어 있으면 '누락없음'이라고 표시하는 '부서명누락여부' 컬럼을 만들어 함께 출력하기.
deptno가 null이면 '부서누락', not null이면 '누락없음'을 출력하는 DECODE 함수를 포함한 SQL 문장은 아래와 같습니다.
select ename,
deptno,
decode(deptno, null , '부서누락', '누락없음') as 부서명누락여부
from emp;

DEPTNO(부서번호)가 null인 레코드는 '부서누락', null이 아니면 '누락없음'으로 표기된 컬럼이 새로 만들어졌습니다.
7) emp 테이블에서 직원성명(ename), 부서번호(deptno)를 출력하고,
- 부서번호가 10번이면 'ACCOUNTING', 20번이면 'RESEARCH', 그 외에는 'ETC'라고 출력하는 '부서명칭' 컬럼을 만들어 함께 출력하기
이는 'A=B이면 X, A=C이면 Y, A≠C이면 Z를 출력'하는 경우에 해당합니다.
DECODE(A, B, X, C, Y, Z)에 따라 SQL 문장을 구성하면 아래와 같습니다.
select ename,
deptno,
decode(deptno, 10, 'ACCOUNTING', 20, 'RESEARCH', 'ETC') as 부서명칭
from emp
order by deptno;
DEPTNO 컬럼의 값이 10이면 ACCOUNTING, 20이면 RESEARCH, 10도 20도 아니면 ETC를 일괄 출력하는 새로운 컬럼(부서명칭)이 만들어졌습니다.
8) emp 테이블에서 직원성명(ename), 부서번호(deptno)를 출력하고,
- 부서번호가 20이고, 직원 이름이 'SMITH'이면 '금주당직',
- 부서번호가 20이고 SMITH가 아닌 나머지는 '다음주 당직',
- 그 외에는 null로 표시하는 '비고' 컬럼을 만들어 함께 출력하기
이 경우 DECODE 함수를 중복하여 사용해야 합니다.
DECODE(A, B, DECODE(A, C, X, Y), Z)
- 부서번호(A1)가 20번인가(B)?
- 직원 이름(A2)이 'SMITH'(C) 인가?
- A1=B이면서 A2=C이면 : '금주당직' 출력(X)
- A1=B 이면서 A2≠C이면 : '다음주 당직' 출력(Y)
- A1≠B 이면 : null로 표시(Z)
select ename,
deptno,
decode(deptno, 20, decode(ename, 'SMITH', '금주당직', '다음주 당직'), null) as 비고
from emp
order by deptno;
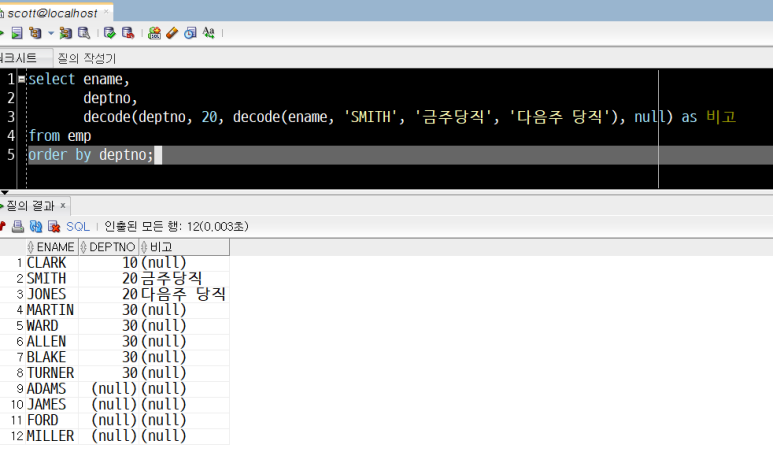
- 부서번호 20번인 직원들 중 SMITH는 금주당직, 나머지는 다음주 당직
- 20번 부서가 아닌 직원들은 비고 컬럼란이 모두 null로 출력되었습니다.
'Structured Query Language > Oracle SQL' 카테고리의 다른 글
| Oracle SQL 기본_07 (0) | 2023.04.21 |
|---|---|
| Oracle SQL 기본_06 (1) | 2023.04.20 |
| Oracle SQL 기본_04 (0) | 2023.04.20 |
| Oracle SQL 기본_03 (0) | 2023.04.20 |
| Oracle SQL 기본_02 (0) | 2023.04.19 |



