TO_CHAR (2) 숫자를 문자로 변환 : 천 단위 구분 쉼표 표시, 소수점 이하 표시, 달러($)·원(\) 표시, 빈 자리를 0으로 채우기 등 (형변환 함수)
데이터베이스에 저장된 각종 숫자 타입의 데이터(예 : 연봉, 월급, 수당, 소득, 지출 등) 중, 그 용도에 맞추어 적절하게 가공된 형태로 데이터를 조회해야 하는 경우가 있습니다.
- 연봉, 월급, 수당, 소득, 지출 등 돈(화폐)에 천의 자리 구분 기호(쉼표) 붙이기
- 숫자 앞에 달러($) 기호 붙이기
- N자리로 길이를 통일하고, 숫자 앞의 남는 자리는 0과 같은 기호로 채우기
- 정수(integer)가 있더라도, 일괄적으로 일정하게 소수점 아래 n째 자리까지 표시하게끔 하기
...
위와 같은 필요가 발생했다면,
TO_CHAR 함수를 사용하여 숫자 타입 데이터를 원하는 형태의 문자로 형변환하여 출력하면 됩니다.
1. TO_CHAR 함수의 개념과 표현
1) TO_CHAR 함수의 개념
TO_CHAR는 숫자 타입이나 날짜 타입의 데이터나 컬럼을 원본 데이터를 바꾸지 않고 문자 타입으로 형변환하여 출력해 주는 함수입니다.

2) TO_CHAR 함수의 표현 : 숫자 → 문자로 변환 시
(1) 기본식
select to_char(숫자타입데이터A, '출력형식Z')
from dual;
select to_char(숫자타입컬럼이름B, '출력형식Z')
from 테이블이름;
(2) 주요 출력형식 요약 (*위 기본식에서의 Z) :
|
기능
|
오라클 SQL에서 표현하는 예
|
출력 예시
|
|
빈 자리는 0으로 표시하여 숫자 길이를 통일
|
TO_CHAR(XXXX, '009999')
|
00XXXX
|
|
숫자에 달러($) 기호 붙이기
|
TO_CHAR(XXXX, '$XXXX')
|
$XXXX
|
|
소수점 이하를 일괄 표시하기
|
TO_CHAR(XXXX.YYYY, '9999.99')
|
XXXX.YY
|
|
천 단위 구분하여 표시하기(,)
|
TO_CHAR(XXXX, '9,999')
|
X,XXX
|
2. 예제 : TO_CHAR 함수를 이용하여 숫자를 문자 형태로 형변환하기
1) 가상테이블 DUAL에 TO_CHAR 함수를 사용하여 사용하여, 임의의 숫자 4565.789에 대해 다음과 같은 형태의 결과를 출력하기
ⓐ '004565'형태로 표시
ⓑ '4,565' 형태가 되도록, 소숫점 아래 두 자리를 표시하지 않고 천의 자리 구분기호 표시
ⓒ '$4,565' 로 표시. 달러 구분 기호와 천의 자리 구분기호 표시
ⓓ 소숫점 아래 둘째 자리까지만 표시
TO_CHAR 함수를 사용하여, 위 ⓐ~ⓓ를 각각 출력하는 SQL 문장을 구성하면 아래와 같습니다.
select 4565.789,
to_char(4565.789, '009999') as OOXXXX,
to_char(4565.789, '9,999') as TCOMMA,
to_char(4565.789, '$9,999') as D_TCOMMA,
to_char(4565.789, '9999.99') as XXXX_XX
from dual;(* Alias 로 컬럼에 붙인 별칭은 임의의 것입니다. 다른 별칭이어도 무방합니다.)
위 SQL 문장을 실행하면, Oracle SQL Developer 는 다음과 같은 결과를 출력합니다.

동일한 숫자를 투입했지만, 각기 TO_CHAR 함수로 지정한 형태에 따라 다양한 형태로 형변환되어 조회되었습니다. 이 함수는 분석의 목적에 맞는 결과값으로 다듬을 때 사용할 수 있을 것입니다.
2) 예제 : emp 테이블에서 ename, sal 컬럼을 출력하고,
- sal 컬럼의 값에 천의 자리 구분기호와 달러 기호($)를 붙인 'TO_CHAR_SAL'이라는 컬럼을 만들어 함께 출력하기
sal 값의 범주를 짐작하여, '$999,999' 로 출력될 값의 포맷(형태)를 설정해 주었습니다.
select ename,
sal,
to_char(sal, '$999,999') as TO_CHAR_SAL
from emp;

sal 컬럼이 보유한 레코드 값들이
- 가장 앞에 달러 기호가 붙고
- 천의 자리 구분기호(쉼표)가 쓰인
형태로 일괄적으로 변경되어 표시되고 있습니다.
* TO_CHAR 외에도 TO_NUMBER, TO_DATE 와 같은 형변환함수가 있습니다.
HAVING : 그룹별 조건 검사로 그룹별 집계결과 필터링하기(ex. 국가별 인구 N명 이상, 부서별 평균임금이 최고인 부서, 평균GDP가 가장 높은 국가 등)
GROUP BY 집계함수를 사용해서 집계된 값들에 대해서도 조건을 검사해야 하는 경우가 있습니다.
- 부서별/직책별 평균 임금, 평균 수당이 1000 이상인 경우만 출력
- 직급별 최대 급여, 최소 급여가 X원 이상/이하인 부서만 출력
- 직급별 사원 수, 직원 수가 N명 이상인 경우만 출력
- 부서별 평균 임금의 최대값/최소값/중앙값이 X원 이상/이하인 경우만 출력
- 국가별 인구 총계(총인구)가 1000만명 이상인 경우만 출력
- 대륙별 인구 수, 대륙별 1인당 GDP 최대/최소/중앙값, 평균이...
...
- 국가별 인구 총계가 최대값인 국가의 레코드(* 이 경우 HAVING을 서브쿼리와 함께 사용할 수 있습니다)
....
이 경우 HAVING 절을 사용하여 그룹을 대상으로 조건 검사를 하여 원하는 결과를 얻습니다.
1. HAVING : 그룹 조건 검사 구문의 필요와 그 표현
1) HAVING 절의 사용
HAVING : GROUP BY 후, 그룹별 조건 검사가 필요한 경우에 사용합니다.
- GROUP BY로 그룹화된 집단에서 집계함수를 통해 집계된 데이터(avg, sum, ...)를 얻었을 때
- HAVING을 이용해 GROUP BY로 얻은 집계데이터에도 조건을 붙여 필터링한다.
* 따라서, 어떤 SQL 문장에서 GROUP BY 없이 HAVING만 을 쓰면 오류가 발생합니다.
2) HAVING 절의 위치와 표현
SQL문장에서의 순서 :
SELECT - FROM - WHERE - GROUP BY - HAVING - ORDER BY
select 컬럼이름, 집계함수, ...
from 테이블이름
where 조건
group by 컬럼이름, ...
having 그룹별 조건
order by 컬럼이름;
- WHERE 로 조건을 충족하는 레코드만 선별(필터링)
- 선별된 레코드만 대상으로 GROUP BY, 집계함수로 그룹별 집계된 값 얻기
- HAVING 그룹조건절로 그룹별로 집계된 값들 중 조건을 충족하는 결과값만 필터링
- 마지막으로 결과를 정렬(ORDER BY)하여 출력하기
* 위의 기본적인 SQL 문장 구성요소를 잘못된 순서로 입력할 경우 오류(ORA-00933)가 발생합니다.
ORA-00933: SQL 명령어가 올바르게 종료되지 않았습니다
00933. 00000 - "SQL command not properly ended"
3) WHERE 조건절과 HAVING 그룹조건절의 차이
- WHERE 조건절 : 관측값(row, 행) 전체에 대해 조건 검사를 하여, 조건에 맞지 않는 관측값들은 필터링하여 제외하는 역할을 수행. 그룹함수(집계함수) 사용 불가. GROUP BY 이전에 시행, GROUP BY 함수 없이 사용 가능
- HAVING 그룹조건절 : WHERE 절로 필터링된 이후(혹은 WHERE 절이 없이) 집계한 값들(avg, sum, count, max 등)을 기준으로 조건 검사를 실시하는 그룹 조건절 역할. GROUP BY 이후 시행, GROUP BY 함수 없이 사용 불가
2. 예제 : GROUP BY와 HAVING 절을 사용한 그룹별 집계 결과의 필터링
* 이하의 예제에서는 hr 연습계정의 employees 테이블을 사용합니다.
1) 예제 : employees 테이블을 사용하여,
ⓐ 부서별 평균급여를 소수점 아래 첫째 자리까지 반올림하여 구하되,
ⓑ 각 부서의 평균급여가 2000 이상인 부서의 평균급여만 부서번호와 함께 출력하기
여기서 ⓐ 부분에는 GROUP BY와 집계함수 AVG,
부서별 정보를 바탕으로 필터링하는 ⓑ 부분에는 HAVING 절이 사용되는 것입니다.
select department_id as 부서번호,
round(avg(salary),1) as 평균급여
from employees
group by department_id
having avg(salary)>=2000
order by department_id;주어진 조건을 충족하도록 SQL 문장을 구성하면 위 소스코드와 같습니다.
Ctrl+Enter를 눌러 문장을 실행하면, 오라클 SQL 디벨로퍼는 아래와 같은 결과를 보여줍니다.

각 부서(department_id)별 평균 급여가 소수점 아래 첫째 자리까지 반올림하여 나타났고, 급여 평균은 모두 2000 이상인 기준을 충족하고 있습니다.
2) 예제: 가능한 오류
집계함수에 대한 조건검사절을 HAVING절이 아닌 WHERE 조건절에 사용할 경우, 오류(ORA-00934)가 발생합니다.
'1)'과 같은 상황에서, 아래 소스코드는 잘못된 SQL 문장입니다. HAVING절에 위치해야 할 그룹 조건절이 WHERE 절에 쓰여 있습니다.
select department_id as 부서번호,
round(avg(salary),1) as 평균급여
from employees
where avg(salary)>=2000
group by department_id
order by department_id;
ORA-00934: 그룹 함수는 허가되지 않습니다
00934. 00000 - "group function is not allowed here"
*Cause:
*Action:
4행, 15열에서 오류 발생
이 경우 WHERE 절의 그룹별 조건을 GROUP BY 다음 순서에서 HAVING 절로 설정하여 주면
ORA-00934 오류는 해결됩니다.
3) 예제 : employees 테이블을 사용하여,
ⓐ 부서번호가 80번이 아니고, null이 아닌 직원들만을 대상으로
ⓑ 각 부서별 직원수, 급여 최대값, 급여 최소값, 급여 중앙값을 구하되
ⓒ 직원수가 5명 이상인 부서에 대해서만 위 값을 출력하기
여기서 ⓐ 부분에는 WHERE,
ⓑ에는 집계함수인 COUNT, MAX, MIN, MEDIAN이 사용되고,
ⓒ 에서 부서별 정보를 바탕으로 필터링하는 HAVING 절이 사용됩니다.
조건에 따라 SQL 문장을 구성하면 아래와 같습니다.
select department_id as 부서번호,
count(employee_id) as 직원수,
min(salary) as 최소급여,
max(salary) as 최대급여,
median(salary) as 급여중앙값
from employees
where department_id!=80 and department_id is not null
group by department_id
having count(employee_id)>=5
order by department_id;
- 조건(부서번호가 80이나 null이 아닌 직원들)을 충족한 직원들만을 기준으로
- 직원수가 5명 이상인 부서들에 대해서만(그룹별 조건으로 그룹 집계정보에 대한 필터링)
- 최소급여, 최대급여, 급여 중앙값이 출력된 모습입니다.
4) 예제 : employees 테이블을 사용하여,
ⓐ 1987년에 입사한 직원들을 제외한 나머지를 대상으로,
ⓑ 입사연도와 부서번호를 기준으로 그룹화
ⓒ 입사연도별, 부서별 사원수를 구하되
ⓓ 각 부서별 직원수가 3명 이상인 부서에 대해서만 값을 출력하기
ⓐ : WHERE
ⓑ : GROUP BY
ⓒ : COUNT, MAX, MIN, MEDIAN이 사용되고,
ⓓ : 그룹별 조건으로 필터링하는 HAVING 절이 사용
조건에 따라 SQL 문장을 구성하면 아래와 같습니다.
select to_char(hire_date, 'YYYY') as 입사연도,
department_id as 부서번호,
count(*) as 사원수
from employees
where to_char(hire_date, 'YYYY')!='1987'
group by to_char(hire_date, 'YYYY'), department_id
having count(*)>=3
order by 입사연도;
입사연도별, 부서별 사원수가 3명 이상인 경우의 값만 출력되었습니다.
서브 쿼리(Sub Query) (1) 기본 및 예제 : 서브쿼리 결과가 1개인 단일 행 서브쿼리
1개의 SQL 문장 내에서, 먼저 A라는 질문의 답을 구하고 → 이 값을 B라는 질문의 조건으로 사용하여 최종적인 값을 도출해야 하는 경우가 있습니다. 이 때 사용하는 것이 서브쿼리(Sub Query) 입니다.
아래와 같은 예시에서 서브쿼리를 사용할 수 있습니다.
ex1. OO보다 급여를 더 많이 받는 / 더 적게 받는 사람
- OO의 급여를 구하고(서브쿼리) → 이 값을 기준으로 더 많이/더 적게 받는 사람을 출력(메인쿼리)
ex2. OO부서 평균보다 더 적은 급여를 받는 사람
- OO 부서 평균 급여를 구하고(서브쿼리) → 이 값보다 더 적은 급여를 받는 사람을 출력(메인쿼리)
ex3.전 세계 평균보다 GDP가 더 높은 / 더 낮은 국가
- 전 세계 평균GDP를 구하고(서브쿼리) → 이 값보다 더 높거나 낮은 국가를 출력(메인쿼리)
1. 서브 쿼리(Sub Query)의 정의와 표현
1) 서브 쿼리의 개념
쿼리(SQL문장) 안에 또 다른 쿼리(SQL문장)가 담겨있는 것. 메인 쿼리(Main Query) 안에 들어 있습니다.
서브쿼리 값을 구하여 → 메인쿼리에서 원하는 값을 구할 수 있도록 조건 값으로 활용
select 컬럼이름A, 컬럼이름B, ...
from 테이블이름;
where 조건연산자 (서브쿼리);위와 같은 개념으로 볼 수 있습니다.
(서브쿼리)에는 SELECT로 시작하는 SQL 문장이 들어갈 수 있습니다.
2) 서브 쿼리의 표현
select 컬럼이름A, 컬럼이름B, ...
from 테이블이름;
where 조건연산자 (select X
from 테이블이름
where 조건);ⓐ 서브쿼리의 위치 : WHERE절 연산자 오른쪽
ⓑ 서브쿼리는 반드시 괄호 안에 서술
ⓒ 일반적으로 서브쿼리절에는 order by 사용 불가
ⓓ 서브쿼리를 포함한 메인쿼리 문장 전체에서 세미콜론(;)은 문장이 끝날 떄 1번만 사용
ⓔ 서브쿼리 내에는 세미콜론(;)은 넣지 않음
ⓕ 서브쿼리 내부에서도 WHERE 뿐만 아니라 GROUP BY, HAVING 사용 가능
2. 예제 : 서브쿼리의 이해와 기본적 활용
1) scott 연습계정 : emp 테이블
전체 직원의 급여 평균보다 더 높은 급여를 받는 직원의 모든 레코드를 검색하기
위 예제를 2개의 SQL 문장으로 개념화하면 아래와 같습니다.
-- 전체 직원의 급여 평균값
select avg(sal) from emp;
-- 전체 직원의 급여 평균보다 더 높은 급여를 받는 직원
-- 모든 레코드 검색
select * from emp
where sal>(전체 직원의 급여 평균값);위 2개의 SQL 문장을 서브쿼리를 사용해 1개의 SQL 문장으로 바꾸어 준 것이 아래와 같은 결과물입니다.
select*from emp
where sal>(select avg(sal) from emp);
emp테이블에서 전체 직원의 평균급여보다 더 큰 높은 급여를 받는 직원들의 레코드만 검색되었습니다.
2) 오류 예시 : '1)'의 문제에서, 서브쿼리를 쓰지 않을 경우
서브쿼리를 쓰지 않고 아래와 같은 SQL 문장을 만들어 실행하면 오류가 발생합니다.
select*from emp
where sal>avg(sal);위 문장을 실행할 경우 발생하는 오류는 ORA-00934 : 그룹함수 불허 에러입니다.

ORA-00934: 그룹 함수는 허가되지 않습니다
00934. 00000 - "group function is not allowed here"
*Cause:
*Action:
AVG은 집계함수이므로 GROUP 함수와 사용해야 하고, 다른 일반적인 컬럼들과 위계가 다르다는 문제가 발생하기 때문입니다.
3) hr 연습계정 : employees 테이블
Julia Nayer 라는 직원보다 더 낮은 월급을 받는 직원들의 직원번호, 이름, 월급 출력하기
서브쿼리에 들어가 메인쿼리의 기준이 되어 줄 조건이 Julia Nayer의 월급입니다.
이 예제를 2개의 SQL 문장으로 개념화하면 아래와 같습니다.
select employee_id as 직원번호,
first_name as 이름,
salary as 급여
from employees
where salary<(Julia Nayer의 salary);
-- Julia Nayer의 salary를 출력하는 SQL 문장
select salary
from employees
where lower(first_name)='julia'
and lower(last_name)='nayer';
위 2개의 문장을 서브쿼리를 사용하여 1개의 SQL 문장으로 합친 결과는 아래와 같습니다.
select employee_id as 직원번호,
first_name as 이름,
salary as 급여
from employees
where salary<(select salary
from employees
where lower(first_name)='julia'
and lower(last_name)='nayer');

Julia Nayer보다 적은 급여를 받는 모든 직원들에 대하여 지정한 컬럼의 데이터가 출력되었습니다.
4) 오류 예시 : '3)'의 예시에서 발생할 수 있는 에러
동명이인이 있어 서브쿼리의 결과값이 2개 이상일 경우
서브쿼리에서 Julia Nayer라는 사람의 급여를 검색할 때, 풀네임 대신 퍼스트네임(Julia)만 검색할 경우, 오류(ORA-01427)가 발생합니다.
select employee_id as 직원번호,
first_name as 이름,
salary as 급여
from employees
where salary<(select salary
from employees
where lower(first_name)='julia');
ORA-01427: 단일 행 하위 질의에 2개 이상의 행이 리턴되었습니다.
01427. 00000 - "single-row subquery returns more than one row"

그 이유는, 이름이 julia인 사람이 2명이기 때문입니다.
동명이인이 있어 서브쿼리(select salary from employees where lower(first_name)='julia')가 반환하는 값이 3200과 3400, 두 개가 되어버렸습니다. 단일 행 하위 질의에 2개 이상의 값이 리턴되는 오류가 발생한 것입니다.
이 문제를 해결하기 위해 1)에서 풀네임으로 정확히 Julia Nayer 임을 명시해 주니 오류가 발생하지 않았습니다.
* 서브쿼리 결과가 2개 이상 출력되는 다중행 서브쿼리의 경우 별도의 포스팅으로 다루고자 합니다.
5) hr 연습계정 : employees 테이블
Alexander Hunold와 직책ID가 같은 직원들의 직원번호, 풀네임, 직책ID 출력
이 예시에서 서브쿼리에 들어가 메인쿼리의 기준이 되어 줄 조건은 Alexander Hunold의 job_id입니다.
이 예제를 2개의 SQL 문장으로 개념화하면 아래와 같습니다.
select employee_id as 직원번호,
first_name||' '|| last_name as 성명,
job_id as 직책ID
from employees
where job_id=(Alexander Hunold의 job_id)
;-- Alexander Hunold의 job_id를 출력하는 SQL 문장
select job_id
from employees
where lower(first_name||' '||last_name)='alexander hunold'
위 두 개의 SQL 문장을 서브쿼리를 사용해 합쳐서 1개의 SQL 문장으로 만든 결과는 아래와 같습니다.
select employee_id as 직원번호,
first_name||' '|| last_name as 성명,
job_id as 직책ID
from employees
where job_id=(select job_id
from employees
where lower(first_name||' '||last_name)='alexander hunold')
Alexander Hunold의 직책ID는 IT_PROG 입니다. Hunold와 직책이 같은(IT_PROG) 다른 직원들의 정보가 검색된 모습을 볼 수 있습니다.
6) hr 연습계정 : employees 테이블
job_id가 IT_PROG인 직원들 중 가장 적은 급여를 받는 직원보다,
더 적은 급여를 받는 직원들의 직원번호, 직책코드, 급여를 출력하기
이 예시에서 서브쿼리에 들어가 메인쿼리의 기준이 되어 줄 조건은 job_id가 IT_PROG인 직원들 중 가장 적은 급여의 값입니다.
이 예제를 2개의 SQL 문장으로 개념화하면 아래와 같습니다.
select employee_id as 직원번호,
job_id as 직책코드,
salary as 급여
from employees
where salary<(job_id가 IT_PROG인 직원들 중 최소 급여);.
-- IT_PROG 직책인 사람들 중 가장 적은 급여를 받는 사람의 급여값
select min(salary)
from employees
where job_id='IT_PROG';
위 2개의 SQL 문장을 서브쿼리를 사용하여 합쳐 하나의 SQL 문장으로 만들면 아래와 같습니다.
select employee_id as 직원번호,
job_id as 직책코드,
salary as 급여
from employees
where salary<(select min(salary)
from employees
where job_id='IT_PROG');
- IT_PROG 직책인 직원들이 받는 급여 중 가장 적은 급여보다
- 더 적은 급여를 받는 직원들의 직원번호, 직책, 급여 정보가 출력되었습니다.
IN 연산자 : WHERE 조건 여러 개가 or로 연결될 때, 반복되는 부분을 간단하게 단축하여 나타내기 (ex. 부서번호 10번 또는 20번 또는 30번)
1. IN 연산자의 개념과 표현
WHERE 조건절에 같은 컬럼(변수)과 연산자가 반복되는 몇 가지 조건이 or로 이어지는 경우,
똑같은 내용이 반복되어 SQL 문장이 길어지는 경우가 있습니다.
이 때, IN 연산자는 조건절의 반복되는 구간을 단축하여 표현할 수 있게 합니다.
|
SQL 문장에서의 표현 예시
|
의미
|
|
|
WHERE A=X or A=Y or A=Z
|
WHERE A IN (X, Y, Z)
|
A는 X, Y, Z 중 적어도 하나
|
|
WHERE (컬럼이름A, 컬럼이름B) IN
(SELECT 컬럼이름A, 집계함수(컬럼이름B) FROM 테이블이름, ...)
|
서브쿼리 내부 조건을 충족시키는 (A, B) 쌍을 추출
|
|
2. 예제 : IN 연산자를 사용한 SQL 문장의 단축 및 서브쿼리에의 사용
1) 예제 : scott 연습계정, emp 테이블에서
- 부서번호가 10번이거나, 20번이거나, 30번인 직원들의
- 부서번호, 성명, 월급 컬럼을 출력하기
WHERE 조건절의 조건 3개를 or로 연결하면 아래와 같습니다.
select deptno as 부서번호,
ename as 성명,
sal as 월급
from emp
where deptno=20 or deptno=30 or deptno=10;
deptno=10
deptno=20
deptno=30
같은 부분이 반복되고 있습니다.
위 SQL 문장 WHERE 조건절의 반복되는 부분을 IN 연산자를 이용해 단축하면 아래와 같습니다.
select deptno as 부서번호,
ename as 성명,
sal as 월급
from emp
where deptno in (10, 20, 30);deptno in (10, 20, 30)은 deptno가 10 또는 20 또는 30이라는 의미입니다.
위 2개의 예시 문장을 각각 Ctrl+Enter로 실행하면, 오라클SQL 디벨로퍼는 아래와 같은 결과를 보여줍니다


두 가지 경우 모두 동일한 결과가 나왔습니다.
2) 예제 : hr연습계정, employees 테이블에서
- 직급(job_id)별로 최고 급여를 받는 직원들의
- 사번(employee_id), 이름(first_name), 직급(job_id), salary(급여) 출력하기
이 문장은 다중 행 서브쿼리에 IN 연산자를 쓰는 경우에 해당합니다.
(1) 직급 최고 급여를 산정하기
직책(job_id)을 기준으로 그룹화하여(GROUP BY) 최고 급여(MAX(salary))를 구해야 합니다.
-- 직책별로 최고 급여 산정
select job_id,
max(salary)
from employees
group by job_id;
(2) 직책별 최고 급여를 받는 직원의 정보를 출력하기
-- (직책, 급여) 순서쌍이 (직책, 직책별 최고급여) 와 같은 직원의 정보 출력
select employee_id as 사번,
first_name as 이름,
job_id as 직책,
salary as 급여
from employees
where (직책, 급여) in (직책, 직책별 최고 급여);
(3) 위 (1), (2)의 문장을 서브쿼리를 사용해 1개의 문장으로 합치기
select employee_id as 사번,
first_name as 이름,
job_id as 직책,
salary as 급여
from employees
where (job_id, salary) in (select job_id, max(salary)
from employees
group by job_id);

각 직책별로 최고 급여를 받는 직원들의 정보(퍼스트네임, 직원번호) 가 출력되었습니다.
서브 쿼리(Sub Query) (2) 응용 예제 : 서브쿼리 결과가 2개 이상인 경우, 다중 행 서브쿼리 (ft. IN 연산자, >ANY, >ALL
1. 다중 행 서브쿼리(Sub Query)의 개념 이해
1) 단일 행 서브쿼리
서브쿼리(Sub Query)를 통하여,
- 전체 SQL 문장에서 조건의 기준이 될 값을 먼저 찾은 뒤
- 찾아낸 값을 바탕으로 최종적으로 얻어낼 값을 인출하는 작업이 가능했습니다.
아래와 같은 사용 예시에서, 밑줄이 쳐진 보라색 글씨 부분이 서브쿼리를 통해 산출하는 부분입니다.
ⓐ OO 직급에서 가장 월급이 높은 사람의 월급보다 월급을 더 많이 받는 / 더 적게 받는 사람
ⓑ OO 부서 평균 급여보다 더 적은 급여를 받는 사람의 정보 출력하기
ⓒ 전 세계 평균GDP보다 GDP가 더 높은 / 더 낮은 국가의 레코드 출력하기
...
그런데 위의 예시에서는 서브쿼리를 통해서 산출되는 값이 단 1개입니다.
따라서 서브쿼리에서 구한 '조건의 기준이 되는 값'도 1개입니다.
이러한 경우를 단일 행 서브쿼리라고 합니다.
2) 다중 행 서브쿼리
하지만, 서브쿼리를 통해서 2개 이상의 값이 도출되는 경우가 있습니다.
이러한 경우를 다중 행 서브쿼리라고 합니다.
다중 행 서브쿼리의 경우 일반적인 비교연산자나 등호(>,<,= 등)를 쓸 수 없고, IN과 같은 특수한 연산자를 써야 합니다.
아래의 연산자들은 다중 행 서브쿼리에서 사용할 수 있는 연산자의 예시입니다.
* 부등호의 방향이 바뀌면 반대의 의미가 되므로 순서와 방향에 유의합니다.
|
다중 행 서브쿼리 연산자 사용시
|
의미
|
|
X IN (서브쿼리Y)
|
서브쿼리 Y의 값이 X와 같음
|
|
X > ANY (서브쿼리Y)
|
X는 Y의 최소값보다 큼
|
|
X < ANY (서브쿼리Y)
|
X는 Y의 최대값보다 작음
|
|
X > ALL (서브쿼리Y)
|
X는 Y의 최대값보다 큼
|
|
X < ALL (서브쿼리Y)
|
X는 Y의 최소값보다 작음
|
|
X EXIST (서브쿼리Y)
|
서브쿼리의 값이 있을 경우 반환
|
표만 봐서는 뭐가 뭔지 바로 알기가 어렵습니다. 이해를 돕기 위해 수평선에 영역을 나타내 보았습니다.

2. 예제 : 다중 행 서브쿼리(Sub Query)를 사용한 문제 해결
* 이하의 예제들에서는 hr 연습계정의 employees 테이블, departments 테이블을 사용합니다.
1) employees 테이블에서 각 직책별 최고 급여를 받는 직원들에 대하여
- 해당 직원들의 사번(employee_id), 이름(first_name), 직책(job_id), 급여(salary) 출력하고, 결과는 직책 오름차순으로 정렬하기
- 먼저 각 직책별 최고 급여를 받는 직원들을 파악(서브쿼리)
- 이후 해당 직원들의 정보를 출력
대상이 전체 직원 중 최고 급여를 받는 직원(1명)이 아니라,
부서별 최고 급여를 받는 직원이므로 서브쿼리 결과값이 여러명일 수 있습니다. 따라서 IN 연산자를 사용하는 다중 행 서브쿼리 유형에 해당합니다.
select employee_id as 사번,
first_name as 이름,
job_id as 직책,
salary as 급여
from employees
where (부서, 급여) in (부서, 부서별 최고급여)
order by 직책;각 직원의 (부서, 급여) 순서쌍이 (부서, 부서별 최고급여) 순서쌍 중 하나와 일치해야만 하는 것이 조건입니다.
부서별 최고급여를 구하는 SQL 문장은 아래와 같습니다.
select job_id,
max(salary)
from employees
group by job_id;위 2개의 SQL 문장을 하나로 합치면 아래와 같이 서술할 수 있습니다.
select employee_id as 사번,
first_name as 이름,
job_id as 직책,
salary as 급여
from employees
where (job_id, salary) in (select job_id, max(salary)
from employees
group by job_id)
order by 직책;서브쿼리와 IN 연산자를 사용한 다중 행 서브쿼리 문장입니다.
Ctrl+Enter로 위 문장을 실행하면, 오라클 SQL 디벨로퍼는 아래와 같은 결과물을 출력합니다.

2) 예제 : employees 테이블;, departments 테이블을 바탕으로
- location_id=1700인 모든 부서에 속한 사원들의
- 직원번호, 풀네임, 부서번호를 출력하기
이번 예제에서는 테이블이 2개이지만, join 없이도 해결할 수 있습니다.
- 먼저 location_id=1700에 해당하는 모든 부서를 조사하고 (서브쿼리)
- WHERE 조건절을 이용해 그 부서들에 속한 직원들만 필터링하여
- 정보를 출력합니다.
departments 테이블의 전체 컬럼을 조회하면 location_id 컬럼이 있습니다.

그런데 location_id = 1700에 해당되는 부서 (department_id)가 여러개입니다.
따라서 다중 행 서브쿼리 문제에 해당합니다.
이 문제를 단순하게 개념화하면 아래와 같습니다.
select employee_id as 직원번호,
first_name||' '||last_name as 성명,
department_id as 부서번호
from employees
where 부서번호 in (location_id가 1700인 부서번호들);그리고 location_id가 1700인 부서들을 구하는 서브쿼리 SQL 문장은 다음과 같습니다.
select department_id
from departments
where location_id=1700;위 2개의 문장을 한 개의 SQL 문장으로 합친 것이 이 예제가 목적하는 것입니다.
select employee_id as 직원번호,
first_name||' '||last_name as 성명,
department_id as 부서번호
from employees
where department_id in (select department_id
from departments
where location_id=1700);
location_id=1700인 10번 , 30번, 90번, 100번, 110번... 부서에 소속된 직원들의 정보가 출력되었습니다.
3) 예제 : employees 테이블에서
- 직책ID(job_id)가 'IT_PROG'인 사람이 받는 최저 월급보다 더 많은 월급을 받는 직원들의
- 직원번호, 성명(풀네임), 직책ID, 월급을 출력하기
이 경우에는 'X > ANY (서브쿼리Y)' 와 같이 > ANY 연산자를 쓸 수도 있고, MIN(salary)와 같은 집계함수를 사용할 수도 있습니다.
select employee_id as 직원번호,
first_name||' '||last_name as 성명,
job_id as 직책ID,
salary as 월급
from employees
where salary > any(select salary
from employees
where job_id='IT_PROG');select employee_id as 직원번호,
first_name||' '||last_name as 성명,
job_id as 직책ID,
salary as 월급
from employees
where salary > (select min(salary)
from employees
where job_id='IT_PROG');위 SQL 문장들을 각각 실행해 봅니다. 적어도 이 예제에서의 결과는 같게 나옵니다.


직책ID가 IT_PROG인 사람이 받는 급여 중 최저치보다 더 높은 임금을 받는 직원들의 리스트가 출력됩니다.
* 두 SQL 문장의 결과로 출력된 레코드들은 같았지만, 정렬 방식에 차이가 있었습니다.
- salary >ANY 연산자를 사용한 경우 : salary 기준으로 내림차순 정렬
- MIN(salary) 사용한 경우 : employee_id 기준으로 오름차순 정렬
GROUP BY ROLLUP, CUBE : 데이터의 변수별 소계, 총계를 구하여 함께 표시하는 함수. 전체 Sum, 부분 Sum을 레코드(행) 사이에 표시하기
1. ROLLUP, CUBE 함수의 용도와 표현
1) ROLLUP, CUBE 함수의 이해
ROLLUP, CUBE 함수는 GROUP BY 다음에 위치하여
- GROUP BY ROLLUP
- GROUP BY CUBE
와 같은 형태로 사용되는 함수입니다.
|
오라클 SQL에서의 표현
|
의미
|
|
GROUP BY ROLLUP(컬럼이름A, 컬럼이름B)
|
대상 데이터에 대하여, 컬럼(변수) A와 B에 따라
a. 컬럼 (A, B)에 따른 소계를 자동 계산하여 결과 테이블에 중간에 출력
b. 전체 총계를 자동 계산하여 결과테이블 가장 아래에 출력
|
|
GROUP BY CUBE(컬럼이름A, 컬럼이름B)
|
대상 데이터에 대하여, 컬럼(변수) A와 B에 따라
a. 컬럼 (A, B)에 따른 소계를 자동 계산하여 결과테이블 중간에 출력
b. 전체 총계를 자동 계산하여 결과 테이블의 가장 윗 행에 출력
c. 컬럼 A별 소계, 컬럼 B별 소계를 자동 계산하여 결과 테이블 가장 윗행에 출력
|
따라서, 동일한 SQL 문장에 대하여 GROUP BY CUBE를 사용했을 때의 결과 레코드(행, row) 가 GROUP BY ROLLUP보다 더 많습니다.
2) ROLLUP, CUBE 함수의 표현
(1) 기본식의 예
1) 예제 : employees 테이블에서
- 부서번호(department_id), 직책ID(job_id) 별 직원 수를 출력하되,
- ROLLUP을 사용하여 부서번호-직책ID 별 직원수 소계와 전체 총계를 함께 표시
(* 단, 직원 수는 employee_id가 null이 아닌 경우로 집계)
예제의 조건에 따라서 SQL 문장을 구성한 결과는 아래와 같습니다.
select department_id as 부서번호,
job_id as 직책ID,
count(employee_id) as 직원수
from employees
group by rollup(department_id, job_id);

- 기본적으로 부서번호-직책ID에 따른 직원수를 보여주고 있습니다.(GROUP BY만 했을 경우 출력되는 데이터)
- 행 중간 중간에 부서번호별 직원수 소계가 집계되었고
- 가장 마지막 행(33번 행)에 employee_id가 null이 아닌 전체 직원수 총계(107)가 나타나 있습니다.
2) 예제 : employees 테이블에서
- 부서번호(department_id), 직책ID(job_id) 별 직원 수를 출력하되,
- CUBE를 사용하여 부서번호-직책ID 별 직원수 소계, 부서번호별 직원수 소계, 직책ID별 소계, 전체 직원수 총계를 함께 표시
(* 단, 직원 수는 employee_id가 null이 아닌 경우로 집계)
select department_id as 부서번호,
job_id as 직책ID,
count(employee_id) as 직원수
from employees
group by cube(department_id, job_id);
- employee_id가 null인 레코드 수(1)
- employee_id가 있는 전체 직원 수(107)
- 직책ID 별 직원 수 소계
- 부서-직책ID별 직원 수
- 부서별 직원 수 소계
가 GROUP BY CUBE의 결과 출력된 것을 볼 수 있습니다.
GROUPING, GROUPING ID 함수 : 소계, 총계 계산에 사용된 레코드를 0과 1로 표시하기(ft. ROLLUP, CUBE)
GROUPING, GROUPING_ID 함수는 GROUP BY ROLLUP 또는 GROUP BY CUBE와 함께 사용되는 그룹핑 함수입니다.
ROLLUP · CUBE 함수는 지정한 컬럼을 기준으로 그룹별 소계와 총계를 계산하여 주는 함수입니다. 이때, ROLLUP 또는 CUBE 결과인 소계나 총계를 나타내는 레코드인지 여부를 알 수 있도록 보조적으로 GROUPING 함수를 함께 사용할 수 있습니다.
GROUPING 함수는 각 레코드(row, 행)이 해당 GROUPING 작업에 사용되었는지 아닌지를 새로운 컬럼에 표현해줍니다.
1. GROUPING 함수
1) GROUPING 함수의 정의와 표현
(1) GROUPING 함수의 의미
각 레코드(row, 행)이 해당 GROUPING 작업에 사용되었는지 아닌지를 새로운 컬럼에 표현해줍니다.
|
SQL 문장에서의 표현
|
출력값
|
의미
|
|
GROUPING(컬럼이름Z)
|
0
|
Z컬럼에 대해 GROUPING 함수로 계산된 소계 또는 총계가 아님
|
|
1
|
Z컬럼에 대해 GROUPING 함수로 계산된 소계 또는 총계임
|
(2) 기본식의 예
분석의 목적에 따라, rollup 자리에는 cube가 들어갈 수도 있습니다.
select 컬럼이름Z,
집계함수A(컬럼이름B),
grouping(컬럼이름Z), ...
from 테이블이름
group by rollup(컬럼이름Z);
grouping(Z)는 출력된 레코드가 컬럼 Z에 따른 소계/총계 게산 결과인지 여부를 1(예), 0(아니오)으로 알려줍니다.
GROUPING 함수는 단일 컬럼에 대해서만 기능합니다.
즉, GROUPING(컬럼이름Z) 형태는 가능하지만,
GROUPING(컬럼이름Z, 컬럼이름Y, ...) 형태로 여러 변수(컬럼)에 대해서는 사용할 수 없습니다.
GROUPING 함수를 2개 이상의 변수에 대해 사용하려면
그만큼 GROUPING 함수를 2번 이상 써 줘야 합니다.
2) 예제 : GROUPING 함수를 사용하여
ⓐ 부서번호와 직책ID 별 직원수를 출력하고
ⓑ 부서-직책ID별 직원수 소계와 총계를 구하고(ROLL UP 사용)
ⓒ 각 레코드가 ⓑ의 직원수 소계 · 총계 계산 결과인지 1과 0으로 나타내는 새 컬럼을 만들기
이 경우 GROUPING 함수를 사용하여,
- department_id별 소계 또는 총계인지 1,0으로 더 쉽게 알아볼 수 있게 합니다.
즉, 결과 범주에 (null)이 섞여 있더라도 이것을 소계 레코드와 혼동하지 않을 수 있습니다.
select department_id as 부서번호,
job_id as 직책ID,
count(employee_id) as 직원수,
grouping(department_id) as GROUPING_D,
grouping(job_id) as GROUPING_J
from employees
group by rollup(department_id, job_id);

각 변수(컬럼)에 따라, 소계 / 총계 계산에 사용된 레코드인지 여부가 0과 1로 표시되는 새로운 컬럼들이 생겨났습니다.
GROUPING_D 컬럼 : 부서별 계산 결과인 소계/총계 레코드 여부
GROUPING_J 컬럼 : 직책ID별 계산 결과인 소계/총계 레코드 여부
GROUPING_D, GROUPING_J 컬럼 모두 1인 마지막 레코드 : 전체 총계를 의미합니다.
2) 예제 : 위 '1)'과 동일한 문제에서, 잘못된 표현을 하는 경우의 오류
GROUPING 함수는 단일 컬럼에 대해서만 기능합니다.
즉, GROUPING(컬럼이름Z) 형태는 가능하지만,
GROUPING(컬럼이름Z, 컬럼이름Y, ...) 형태로 여러 변수(컬럼)에 대해서는 사용할 수 없습니다.
GROUPING 함수를 2개 이상의 변수에 대해 사용하려면
그만큼 GROUPING 함수를 2번 이상 써 줘야 합니다.
아래의 에러는 GROUPING(컬럼이름Z, 컬럼이름Y, ...) 처럼 잘못 서술된 SQL 문장의 한 예입니다.
select department_id as 부서번호,
job_id as 직책ID,
count(employee_id) as 직원수,
grouping(department_id, job_id) as GROUPING
from employees
group by rollup(department_id, job_id);위 SQL 문장을 실행하면 다음과 같은 오류(ORA-00909)가 발생합니다.
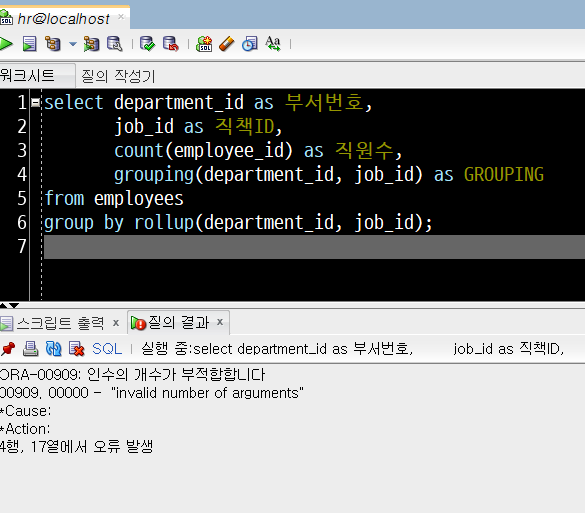
ORA-00909 : 인수의 개수가 부적합합니다
00909.0000 - "invalid number of arguements"
*Cause:
*Action
GROUPING 함수의 인수는 1개여야만 하는데(단일 컬럼에 대해서만 기능) 위 잘못된 예시에서는 2개의 인수를 부여했기 때문입니다.
GROUPING 함수를 써서 2개 이상의 변수에 대해 GROPING을 하려면, GROUPING 함수를 2개 이상 써 주어야 합니다.
만약 한 개의 함수로 여러 개의 변수에 대해 GROUPING 소계 레코드인지 여부를 분류하여 보고 싶다면
GROUPING_ID 함수를 써야 합니다.
2. GROUPING_ID 함수
1) GROUPING_ID의 개념
GROUPING_ID 함수는 GROUPING 함수와 달리 여러 개의 컬럼을 인수로 가질 수 있습니다.
즉, GROUPING_ID(A, B)의 형태로 쓸 수 있습니다.
GROUPING 함수를 여러 번 써야 할 상황에서, GROUPING_ID를 한 번만 사용하는 것으로 코드를 간단하게 만들 수 있기도 합니다.
GROUPING 함수의 결과값은 0 또는 1이었지만,
GROUPING_ID 함수의 결과값은 0,1,2,3이 나오기도 합니다.
따라서 컬럼이름A와 컬럼이름B의 순서가 중요합니다. 출력값(1,2)에 영향을 미치기 때문입니다.
|
SQL 문장에서의 표현
|
출력값
|
의미
|
|
GROUPING_ID
(컬럼이름A, 컬럼이름B)
|
0
|
A컬럼 또는 B컬럼에 에 대해 GROUPING 함수로 계산된 소계 또는 총계가 아님
|
|
1
|
A컬럼에 대해 계산된 소계 또는 총계임
|
|
|
2
|
B컬럼에 대해 계산된 소계 또는 총계임
|
|
|
3
|
A와 B 컬럼 모두에 대해 계산된 소계 또는 총계임
|
따라서 컬럼이름A와 컬럼이름B의 순서가 중요합니다. 출력값(1,2)에 영향을 미치기 때문입니다.
2) 예제 : GROUPING 함수를 사용하여
ⓐ 부서번호와 직책ID 별 직원수를 출력하고
ⓑ 부서-직책ID별 직원수 소계와 총계, 부서별 소계, 직책ID별 소계를 구하고(CUBE 사용)
ⓒ 각 레코드가 ⓑ의 직원수 소계 · 총계 계산 결과인지 나타내는 새 컬럼을 만들기
CUBE, GROUPING_ID를 사용하는 것 외에는 1번의 예제와 유사합니다.
GROUPING_ID 함수를 사용하여 SQL 문장을 구성한 결과는 아래와 같습니다.
select department_id as 부서번호,
job_id as 직책ID,
count(employee_id) as 직원수,
grouping_id(department_id, job_id) as GROUPING_ID
from employees
group by cube(department_id, job_id);
GROUPING_ID 컬럼으로 결과가 나타났습니다.
0 - 이 레코드는 어느 소계/총계 결과도 아님 (보통의 부서별-직책ID별 직원수)
1 - 부서번호별 소계를 표시하는 레코드임
2 - 직책ID별 소계를 표시하는 레코드임
3 - 전체총계를 표시하는 레코드임
이상의 결과 이미지에서,
1번 행 : (null) (null) 1 (GROUPING_ID : 1)
2번 행 : (null) (null) 107 (GROUPING_ID : 3)
이 2개 행의 특성을 GROUPING_ID 함수를 통해서 명시적으로 분별하는 것이 가능하게 되었습니다.
1번 행 : 원본 데이터에서 부서번호도 null, 직책ID도 null인 직원 수(1명)
2번 행 : null이 아닌 전체 직원 수(107명)
GROUP BY GROUPING SETS : 2개 이상의 컬럼·변수에 대해 그룹별 여러 집계함수 결과를 편하게, 한 번에 일괄적으로 조회할 경우
1) GROUP BY GROUPING SETS의 기본 개념
- 학년별 / 학과별 학생 인원합계
- 시도별 / 성별 전체 인구총계
- 부서별 / 직급별 사원 수 소계 및 총계
- 부서별 / 연령별 평균임금, 임금 중간값, 급여총계
- 국가별 / 성별 1인당 GDP 평균값
....
등, 2개 이상의 그룹에 대하여, 각종 집계함수 결과를 일괄적으로 표시해야 하는 경우가 있습니다.
이 때 복잡하게 길어질 수 있는 SQL 소스코드를 편하게 단축시켜 주는 것이 GROUP BY GROUPING SETS 입니다.
select 컬럼이름A, 컬럼이름B, 집계함수Z(컬럼이름a), ...
from 테이블이름
group by grouping sets (컬럼이름A, 컬럼이름B);위와 같은 구성의 SQL 문장을 실행하면,
- 컬럼 A별 집계함수 결과
- 컬럼 B별 집계함수 결과
를 출력하게 됩니다.
* 전체 테이블에 대한 집계함수 결과는 출력하지 않습니다.
2) 예제 : 부서별/직책별 직원수, 평균임금, 급여총계, 급여 중간값 출력하기
GROUP BY GROUPING SETS를 사용하여 위 사항을 출력하는 SQL 쿼리를 구성하면 아래와 같습니다.
select department_id as 부서번호,
job_id as 직책ID,
count(*) as 직원수,
round(avg(salary),1) as 평균임금,
sum(salary) as 급여계,
median(salary) as 급여중간값
from employees
group by grouping sets(department_id, job_id);
- 직책별 직원수, 평균임금, 급여총계, 급여 중간값
- 부서별 직원수, 평균임금, 급여총계, 급여 중간값
전체 테이블을 대상으로 한 값은 GROUP BY GROUPING SETS에서는 출력되지 않았습니다.
3) GROUP BY, GROUP BY GROUPING SETS의 결과 비교
* 전체 테이블을 대상으로 집계함수를 구하려면 :
GROUP BY를 사용하지 않습니다.
* 직책별-부서별 각 순서쌍에 대한 집계함수 결과를 구하려면 :
GROUP BY만 사용합니다.
* 직책별 집계함수 결과 & 부서별 집계함수 결과만 구하려면 :
GROUP BY GROUPING SETS를 사용합니다.
'Structured Query Language > Oracle SQL' 카테고리의 다른 글
| Oracle SQL 기본_09 (1) | 2023.04.25 |
|---|---|
| Oracle SQL 기본_08 (0) | 2023.04.24 |
| Oracle SQL 기본_06 (1) | 2023.04.20 |
| Oracle SQL 기본_05 (0) | 2023.04.20 |
| Oracle SQL 기본_04 (0) | 2023.04.20 |



