RANK : 특정 컬럼을 기준으로 한 순위 출력 함수 (ex. 성적 순위, 과목 석차, 월급 순위, 순위표 조회 등의 목적)
1. RANK 함수의 개념과 표현
1) RANK 함수의 개념
RANK함수는 특정한 컬럼에 대하여 오름차순 또는 내림차순으로 순위를 매겨 컬럼의 형태로 표현하는 함수입니다.
- 학급에서의 성적 순위
- 회사에서의 급여 또는 실적 순위
- 고객의 포인트 또는 구매금액 순위
...
그 외에도 순위를 매겨야 하는 다양한 상황에서 RANK 함수를 사용할 수 있습니다.
2) RANK 함수의 표현
(1) 기본식 : 컬럼X를 기준으로 오름차순으로 순번을 매길 시
select 컬럼이름A,
컬럼이름B, ...,
rank() over(order by 컬럼이름X)
from 테이블이름;
(2) 기본식 : 컬럼X를 기준으로 내림차순으로 순번을 매길 시
select 컬럼이름A,
컬럼이름B, ...,
rank() over(order by 컬럼이름X desc)
from 테이블이름;
(order by 컬럼이름X) 에서 컬럼이름 다음에 'desc'를 붙이면 내림차순 정렬이 됩니다.
(3) 기본식 : 집계함수를 기준으로 순번을 매길 시
select 컬럼이름A,
집계함수K(컬럼이름X),
집계함수L(컬럼이름Y) ...,
rank() over(order by 집계함수K(컬럼이름X))
from 테이블이름
group by 컬럼이름X;
GROUP BY를 사용하여 그룹화한 뒤 그룹별 집계함수 값을 조회할 때도 각 그룹별로 출력되는 값들에 RANK 함수를 적용할 수 있습니다.
* 아래의 예제에서는 hr연습계정의 employees 테이블을 사용합니다.
2. 예제 : RANK 함수의 사용
1) 예제 : employees 테이블에서
ⓐ 직원번호(employee_id), 직원의 성명(first_name, last_name), 급여(salary)를 출력하고,
ⓑ 이와 함께 급여 순위를 내림차순으로 출력하기
rank() over를 사용하여 급여(salary)에 대한 순위를 함께 출력해 주어야 합니다.
위 조건대로 RANK 함수를 사용하여 SQL 문장을 구성하면 아래와 같습니다.
select employee_id as 직원번호,
first_name||' '||last_name as 직원성명,
salary as 급여,
rank() over(order by salary desc) as 급여순위
from employees;위 문장을 실행(Ctrl+Enter)하면 오라클 SQL 디벨로퍼는 다음과 같은 결과를 출력합니다.

급여(salary)와 급여순위(rank() over(order by salary desc))가 급여 내림차순으로 정렬 상태로 나타납니다. 동점의 경우 같은 순위로 처리되고, 그 직후의 순위는 동점자 수만큼 낮아진 순위로 산정된 모습입니다.
2) 예제 : employees 테이블에서
ⓐ 직책ID(job_id)별 평균급여, 최고급여, 최저급여, 직원수를 출력하고
ⓑ 직책ID별 평균급여 순위를 내림차순으로 매겨 함께 출력하기
RANK함수에는 집계함수도 적용할 수 있습니다.
select job_id as 직책ID,
avg(salary) as 평균급여,
rank() over(order by avg(salary) desc) as 평균급여순위,
max(salary) as 최고급여,
min(salary) as 최저급여,
count(employee_id) as 직원수
from employees
group by job_id
order by 평균급여순위;
위 문장을 실행(Ctrl+Enter) 하면 아래와 같은 결과를 얻을 수 있습니다.

직책ID(job_id)별 평균급여가 가장 높은 직책부터 내림차순으로 순위가 매겨져 '평균급여순위' 컬럼으로 출력되었습니다.
REPLACE : 컬럼의 특정한 문자열을 다른 문자열로 일괄적으로 바꾸어 주는 문자열 치환 함수
1. REPLACE 함수의 개념과 표현
1) REPLACE 함수의 개념
REPLACE 함수는 지정한 컬럼에서 특정 문자열을 다른 문자열로 바꾸어 주는 문자열 치환 함수입니다.
일괄적으로 데이터를 바꾸어야 할 경우에 REPLACE 함수를 이용할 수 있습니다.
ex.
- 행정구역 이름을 일괄적으로 바꾸어야 할 경우
- 알파벳을 다른 문자로 치환해야 하는 경우
- 특정 문자를 다른 기호로 나타내야 하는 경우
...
2) REPLACE 함수의 표현
select replace(컬럼이름A, '문자X', '문자Y')
from 테이블이름;
- 지정한 테이블의 컬럼A에 대하여
- 문자X를 문자Y로 바꾼 뒤
- 컬럼의 형태로 조회한다
(* SELECT 구문에서는 REPLACE 함수를 적용하여도 원본 테이블이 변경되지 않습니다.)
* 이하의 예제에서는 hr 연습계정의 employees 테이블을 사용합니다.
2. 예제 : REPLACE 함수의 사용
1) 예제 : employees 테이블에서
ⓐ first_name 컬럼을 출력하고
ⓑ first_name 컬럼에서 'e'를 '*'로 변경한 컬럼(REPLACE)도 함께 조회하기
문자열을 치환하는 경우 REPLACE 함수를 사용해야 합니다.
위 조건에 따라서 SQL 문장을 구성하면 아래와 같습니다.
select first_name as 성명,
replace(first_name, 'e', '*') as REPLACE
from employees;
위 문장을 실행(Ctrl+Enter)하면 다음과 같은 결과를 얻게 됩니다.

first_name 컬럼의 모든 알파벳 e가 별표(*)로 변경된 컬럼이 함께 출력되었습니다.
INSTR, INSTRB : 문자열에서 지정한 문자의 자릿수, byte자릿수를 출력하는 함수 (문자의 자릿수 찾기, 몇 번째에 위치한 문자인지 찾기)
1. INSTR, INSTRB 함수의 개념과 표현
1) INSTR, INSTRB 함수의 개념
INSTR 함수는 문자열에서 특정 문자의 위치(자릿수)를 출력하는 함수입니다.
INSTRB는 문자열에서 특정 문자의 위치(자릿수)를 byte 자릿수로 출력하는 함수입니다.
따라서 영문, 특수문자만 포함된(1자리가 1byte인) 문자열의 경우에는 다른 모든 조건이 같을 때 INSTR 함수 출력값과 INSTRB 함수의 출력값은 같습니다.
* 하지만, 글자 1자당 2byte 이상인 한글과 같은 경우에는 INSTR 함수의 값과 INSTRB 함수의 값에 차이가 있을 수 있습니다.

2) INSTR, INSTRB 함수의 표현
(1) 기본식 : 가상 테이블 DUAL에서 임의의 문자열A에 대하여
- m째 자리(인덱스m)부터 n번째 문자열B의 자릿수, byte 자릿수를 구하는 경우
select instr('문자열A', '찾는문자열B', 시작인덱스m, 숫자n),
instrb('문자열A', '찾는문자열B', 시작인덱스m, 숫자n)
from dual;* 인덱스가 양수이면 왼쪽에서 오른쪽으로 n번째,
인덱스가 음수이면 오른쪽에서 왼쪽으로 n번째 문자열B의 자릿수를 출력하게 됩니다.
(2) 기본식 : 테이블에 속한 컬럼A에 대하여
- m째 자리부터 n번째 문자열B의 자릿수, byte 자릿수를 구하는 경우
select 컬럼A,
instr(컬럼A, '찾는문자열B', 시작자릿수m, 숫자n),
instrb(컬럼A, '찾는문자열B', 시작자릿수m, 숫자n)
from 테이블이름;
* 이하의 예제에서는 hr 연습계정의 employees 테이블을 사용합니다.
2. 예제 : INSTR, INSTRB 함수의 사용
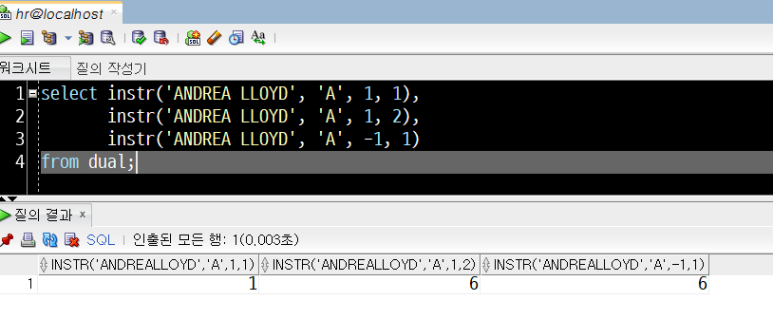
1) 예제 : 가상테이블 DUAL에서 임의의 문자열 'ANDREA LLOYD'에 대하여
ⓐ 첫째 자리부터 첫번째 나오는 'A'의 자릿수
ⓑ 첫째 자리부터 두 번째 나오는 'A'의 자릿수
ⓒ 뒤에서 첫번째 자리부터 세어 첫 번재로 나오는 'A'의 자릿수를 출력하기
주어진 조건에 따라 INSTR 함수를 사용하여 SQL 문장을 구성하면 아래와 같습니다.
select instr('ANDREA LLOYD', 'A', 1, 1),
instr('ANDREA LLOYD', 'A', 1, 2),
instr('ANDREA LLOYD', 'A', -1, 1)
from dual;
2) 예제 : employees 테이블에서
ⓐ first_name 컬럼 출력하기
ⓑ first_name 컬럼의 첫째 자리부터 시작하여 첫번째 'e(E)'의 자릿수(INSTR), byte 자릿수(INSTRB)도 함께 출력하기(* 대소문자 구분 없이 검색)
특정 컬럼에서 문자열이 위치한 자릿수를 구하려면 INSTR, byte 자릿수를 구하려면 INSTRB 함수를 사용해야 합니다.
- 컬럼 : first_name
- 자릿수를 찾으려는 문자열 : e
- 첫 번째 자리부터 시작(m=1)하여 첫번째 오는 e (n=1)
- 대소문자를 구별하지 않으므로 : lower(first_name) 응용
select first_name as 이름,
instr(lower(first_name), 'e', 1, 1) as INSTR,
instrb(lower(first_name), 'e', 1, 1) as INSTRB
from employees;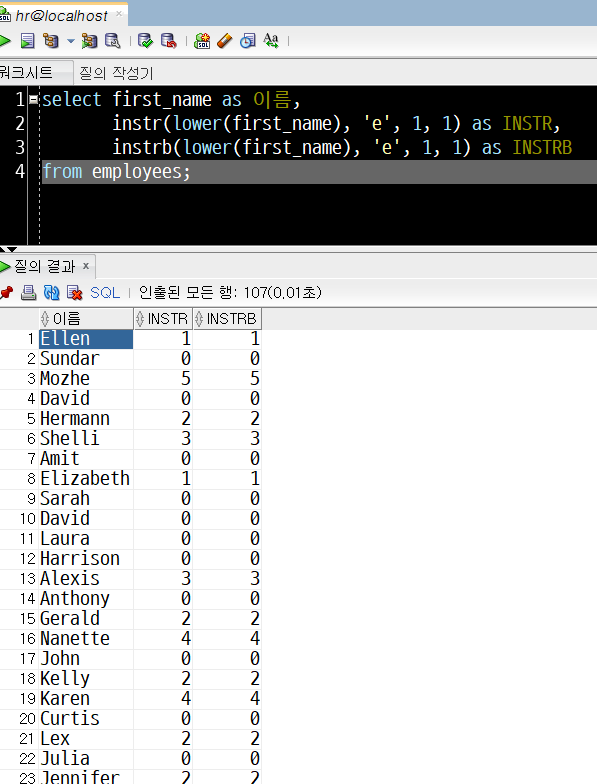
영문자의 경우 1글자가 1byte에 해당합니다. 따라서, 영문자와 숫자만으로 이어진 문자열의 경우에는 다른 모든 조건이 동일할 때 INSTR와 INSTRB 함수의 값이 같게 나타나게 됩니다.
3) 예제 : '1)' 예제의 변형으로, employees 테이블에서
ⓐ first_name 컬럼 출력하기
ⓑ first_name 컬럼 각 문자열의 둘째 자리부터 시작하여 두번째 'l(L)'의 자릿수(INSTR), byte 자릿수(INSTRB)도 함께 출력하기(* 대소문자 구분 없이 검색)
m=2, n=2가 된 경우의 INSTR, INSTRB입니다.
select first_name as 이름,
instr(lower(first_name), 'l', 2, 2) as INSTR,
instrb(lower(first_name), 'l', 2, 2) as INSTRB
from employees;

조건을 만족하는 문자가 없을 경우에는 문자의 자릿수로 '0'이 출력됩니다.
4) 예제 : 한글 문장에의 INSTR, INSTRB 함수 결과값 비교
ⓐ '감사합니다. 안녕히 가시기 바랍니다'라는 예시 문장과 함께,
ⓑ 위 문장의 첫 글자로부터 첫번째 나오는 '다'의 자릿수 출력
ⓒ 위 문장의 첫 글자로부터 첫 번째 나오는 '다'의 Byte 자릿수 출력
INSTR, INSTRB 함수 결과값을 비교하면, 1글자당 2byte인 한글 문장은 두 결과값에 차이가 있습니다.
select '감사합니다. 안녕히 가시기 바랍니다.' as 예시한글,
instr('감사합니다. 안녕히 가시기 바랍니다', '다', 1, 1) as INSTR,
instrb('감사합니다. 안녕히 가시기 바랍니다', '다', 1, 1) as INSTRB
from dual;
왼쪽에서 오른쪽으로 읽었을 때 첫 번째 나타나는 '다'는 다섯번째 글자입니다. 따라서 INSTR=5입니다.
하지만 한글은 1글자당 2byte이므로, 4번째 글자까지 차지하는 용량은 8byte 입니다. 따라서, 그 다음 자리인 다섯 번째 글자 자리에 놓인 '다'의 byte 자릿수는 9가 됩니다.
4) 예제 : 한글 문장에의 INSTR, INSTRB 함수 결과값 비교
ⓐ '감사합니다. 안녕히 가시기 바랍니다'라는 예시 문장과 함께,
ⓑ 위 문장의 세 번째 글자로부터 두번째 나오는 '다'의 자릿수 출력
ⓒ 위 문장의 세 번째 글자로부터 두번째 나오는 '다'의 Byte 자릿수 출력
m=3, n=2로 변경된 경우 한글 문장에 대한 INSTR, INSTRB 결과값 비교입니다. 1자당 2byte임을 유념하면, INSTRB의 결과도 어렵지 않게 예상할 수 있습니다.
select '감사합니다. 안녕히 가시기 바랍니다.' as 예시한글,
instr('감사합니다. 안녕히 가시기 바랍니다', '다', 3, 2) as INSTR,
instrb('감사합니다. 안녕히 가시기 바랍니다', '다', 3, 2) as INSTRB
from dual;
왼쪽에서부터 세 번째 글자('합')으로부터 오른쪽으로 읽었을 때, 두 번째로 나타나는 '다'는 마지막 글자입니다.
공백을 포함하여 19번째 자리에 위치해 있고(INSTR), '.'과 공백은 1byte로 계산하면
'감사합니다. 안녕히 가시기 바랍니'까지 차지하는 byte수는 32byte입니다.
따라서, 마지막 '다'의 byte 자릿수는 그 다음인 33이 됩니다(INSTRB)
제약조건(Constraints)의 종류와 특성 요약 정리 : PRIMARY KEY, NOT NULL, UNIQUE, FOREIGN KEY, CHECK
1. 제약조건(Constraints)의 개념
제약조건이란, SQL 테이블에 문제되는/결함있는 데이터가 입력되지 않도록 컬럼별로 미리 지정해 둔 조건입니다. DESC 명령어를 통해서 변수별로 null이 가능한지 조회가 가능하고, GUI를 이용해 테이블의 제약조건을 모아서 볼 수도 있습니다.


제약조건은 변수별로 설정되어 있습니다.
- Null이면 안 된다.
- 중복되지 않는 고유의 값이어야 한다.
- 다른 테이블로부터 참조해야 한다 / 참조할 데이터가 없으면 입력할 수 없다
- 미리 설정한 조건을 만족해야 한다
...
이렇게 컬럼에 설정된 조건을 제약조건(Constraints)이라고 합니다. 제약조건은 테이블을 생성할 때 함께 설정할 수 있고, 추후에 ALTER 등의 명령어를 사용하여 바꿀 수도 있습니다.
* 이미 데이터가 포함되어 있는 상황에서 제약조건을 함부로 바꾸기 어려우므로 사전에 테이블 설계를 잘 해 두는 편이 좋습니다.
2. 제약조건(Constraints)의 유형과 그 특성
Oracle SQL Developer에서 주로 쓰이는 제약조건의 종류와 그 특성을 요약하면 다음과 같습니다.
|
Constraints
|
NULL 허용 여부
|
데이터 중복 허용여부
|
특징
|
|
NOT NULL
|
NULL 불가
|
중복 가능
|
|
|
UNIQUE
|
NULL 가능
|
중복 불가
(* NULL끼리는 중복으로 간주하지 않음)
|
|
|
PRIMARY KEY(고유키)
|
NULL 불가
|
중복 불가
|
지정한 열은 유일한 값을 반드시 가져야 함
테이블 당 1개만 지정가능
|
|
FOREIGN KEY(외래키)
|
다른 테이블 열을 참조하여
해당 테이블에 존재하는 값만 입력 가능
다른 테이블의 고유키(PRIMARY KEY)를 참조
|
||
|
CHECK
|
설정한 조건식을 만족하는 데이터만 입력가능
조건식을 만족하지 않는 데이터는 입력이 거부됨
|
||
CREATE TABLE : 테이블 생성, 테이블 정의하기, 데이터 유형과 제약조건 설정하기
1. CREATE TABLE의 개념과 표현
1) CREATE TABLE의 개념
우리가 emp, dept 등 오라클 SQL 디벨로퍼에서 통상적으로 사용되는 모습의 테이블을 만드려면
- CREATE TABLE 명령어로 빈 테이블을 만들어 주고
- INSERT 관련 명령어로 테이블에 데이터를 입력해야 합니다.
CREATE TABLE은 오라클 SQL 디벨로퍼에서 컬럼의 이름, 데이터 유형, 제약조건 등을 설정하여 빈 테이블을 생성하는 명령어입니다.
* CREATE TABLE은 DDL(Data Definition Language)로, 데이터를 입력하고 편집하는 것이 아니라 데이터의 성격을 정의하는 명령어임을 꼭 유의해 주세요!
2) 테이블 이름의 조건
ⓐ 테이블 이름은 반드시 문자로 시작해야 합니다. 숫자를 포함할 수는 있지만, 숫자로 시작할 수 없습니다.
ⓑ 테이블 이름, 컬럼이름은 최대 30byte까지 가능 : 영문+숫자 조합 시 최대 30자, 한글 최대 15자
ⓒ 사용자(계정)가 같을 경우, 테이블 이름과 같은 인덱스 이름을 쓸 수 없습니다.
- 사용자가 다르면, 다른 계정의 테이블 이름과 같은 테이블을 생성할 수 있습니다.
* 기 존재하는 테이블과 같은 이름의 테이블을 생성하려 시도하는 경우 : 오류 발생
오류 보고 -
ORA-00955: 기존의 객체가 이름을 사용하고 있습니다.
00955. 00000 - "name is already used by an existing object"
*Cause:
*Action:
ⓓ 테이블 이름에는 오라클 명령어(select, from 등)를 사용하거나 특수문자를 포함하는 것은 권장하지 않습니다. 사용 시 불편하고, 예상하지 못한 결과를 초래할 수 있습니다.
3) CREATE TABLE의 표현
컬럼 간에 ',(쉼표)'로 구분하며, 같은 컬럼 내에서는 공백(' ', 스페이스)으로 입력 항목을 구분합니다.
(1) 기본식 : 테이블이름, 컬럼이름, 각 컬럼의 데이터 유형만 설정하는 경우
create table 테이블이름 (
컬럼이름1 데이터유형,
컬럼이름2 데이터유형,
... ,
);
(2) 기본식 : 테이블이름, 컬럼이름, 각 컬럼의 데이터 유형, 제약조건 유형을 설정
create table 테이블이름 (
컬럼이름1 데이터유형 제약조건유형,
컬럼이름2 데이터유형 제약조건유형,
... ,
);
(3) 기본식 : 테이블이름, 컬럼이름, 각 컬럼의 데이터 유형, 제약조건 이름과 유형을 모두 설정하는 경우
create table 테이블이름 (
컬럼이름1 데이터유형 constraint 제약조건이름 제약조건유형,
컬럼이름2 데이터유형 constraint 제약조건이름 제약조건유형,
... ,
);
(4) 기본식 : 제약조건을 일괄적으로 후반에 설정하는 경우
create table 테이블이름 (
컬럼이름1,
컬럼이름2,
... ,
constraint 제약조건이름 제약조건유형 (컬럼이름1),
constraint 제약조건이름 제약조건유형 (컬럼이름2),
...
);
* 이하의 예제에서는 scott 이나 hr 어느 연습계정을 사용하여도 무방합니다.
2. 예제 : CREATE TABLE의 사용
1) 예제 : 주민 테이블(resid) 만들기
- 컬럼 : 번호(3자리 숫자), 이름, 이사 온 날짜, 우편번호, 방세
위 조건에 따라서, 테이블이 포함해야 할 컬럼의 특성을 만들어 봅니다.
|
속성
|
컬럼이름
|
데이터 유형
|
필요 제약조건
|
|
번호
|
rno
|
숫자(3자리)
|
중복 불가, null 불가
|
|
이름
|
rname
|
문자
|
null 불가
|
|
이사 온 날짜
|
movingdate
|
날짜
|
|
|
우편번호
|
zipcode
|
문자
|
|
|
방세
|
rent
|
숫자(10자리)
|
양수
|
create table resid (
rno number(3,0) constraint pk_rno primary key,
rname varchar2(30) constraint nn_rname not null,
movingdate date,
zipcode varchar2(5),
rent number(10,0) constraint ck_rent check (rent>=0)
);
위 SQL 문장을 실행(Ctrl+Enter)하면 하단의 스크립트 출력 창에 'Table RESID이(가) 생성되었습니다'라는 문구가 나타납니다.

* 같은 문장을 또 실행하는 경우 : 기존의 존재하는 테이블(RESID)과 같은 이름의 또다른 테이블을 생성하려 한다고 간주되어 오류(ORA-00955)가 발생합니다. CREATE TABLE 문장의 실행은 같은 이름의 테이블이 없는 상황에서 가능합니다.

좌측 접속 탭을 새로고침하여 보면, RESID 라는 테이블이 새로 만들어져 목록에 추가된 것을 볼 수 있습니다.
(* 만약 접속 탭에 추가되어 있지 않다면, Oracle SQL Developer를 종료 후 다시 실행하는 경우에는 정상 반영되어 있습니다.)


설정한 대로의 데이터 유형과 제약조건 유형이 반영되어 있습니다.

SELECT FROM 구문을 통해 갓 만들어진 RESID 테이블의 레코드를 조회하여 보면 아무것도 나타나지 않습니다.
CREATE TABLE은 데이터가 입력되기 전, 데이터 입력 조건을 갖춘 빈 테이블을 정의하여 만드는 과정이기 때문입니다. (* DDL)
이제 만들어진 테이블에 데이터를 입력하기 위해 INSERT 명령어가 포함된 다양한 구문을 사용할 수 있습니다.
INSERT INTO : 테이블에 단일 행 데이터(레코드) 입력하기, 단일 행 데이터 추가하기
1. INSERT INTO의 개념과 표현
1) INSERT INTO의 개념
DML(Data Maniuplation Language)은 데이터 레코드를 저장, 수정, 삭제하는 명령어를 의미합니다. INSERT는 DML에 속하는 명령어로, 만들어진 테이블에 데이터(레코드)를 입력하기 위해 사용합니다.
INSERT를 사용하는 구문으로는 INSERT INTO, INSERT SELECT, INSERT ALL 등 몇 가지가 존재합니다. 이들은 모두 (조금씩 다른 방법으로) 테이블에 레코드를 입력/추가하기 위해 사용된다는 공통점이 있습니다.
|
구문
|
특징
|
|
INSERT INTO
|
1개의 테이블에 1개의 행을 입력하기
|
|
INSERT SELECT
|
테이블2에서 검색한 컬럼의 데이터들을 테이블1의 컬럼에 삽입
|
|
INSERT ALL INTO
|
여러 테이블에 여러 행 입력, 다른 테이블에 동시에 같은 행 입력하기
|
2) INSERT INTO 구문의 표현
(1) 기본식 : 테이블이 가진 모든 컬럼에 값을 입력하는 경우
컬럼 이름을 생략하고 각 컬럼에 해당하는 값을 입력할 수 있습니다.
이 때, 값의 순서는 반드시 컬럼의 순서를 따라야 하고, 사전에 설정된 제약조건에 위배되지 않아야 합니다.
insert into 테이블이름
values(값1, 값2, 값3,...);
(2) 기본식 : 지정한 컬럼에만 값을 입력하려는 경우 :
값을 입력할 컬럼의 이름과 값을 함께 입력해 줍니다.
값의 순서가 컬럼의 순서와 같아야 하고, 설정된 테이블 제약조건에 위배되지 않아야 합니다.
insert into 테이블이름
(컬럼1, 컬럼2, 컬럼3... )
values(값1, 값2, 값3,...);
* 이하의 예제에서는 scott, hr 어느 연습계정을 사용하여도 무방합니다.
2. 예제 : 테이블에의 데이터 입력
CREATE TABLE로 예제에 사용할 임의의 테이블 RESID을 만들겠습니다.
create table resid (
rno number(3,0) constraint pk_rno primary key,
rname varchar2(30) constraint nn_rname not null,
movingdate date,
zipcode varchar2(5),
rent number(10,0) constraint ck_rent check (rent>=0)
);테이블에 소속된 컬럼의 이름과 대략의 특성은 아래와 같습니다.
|
속성
|
컬럼이름
|
데이터 유형
|
필요 제약조건
|
|
번호
|
rno
|
숫자(3자리)
|
중복 불가, null 불가
|
|
이름
|
rname
|
문자
|
null 불가
|
|
이사 온 날짜
|
movingdate
|
날짜
|
|
|
우편번호
|
zipcode
|
문자
|
|
|
방세
|
rent
|
숫자(10자리)
|
양수
|
1) 예제 : 위 RESID 테이블에 임의로 1개씩 행을 추가하기
먼저 1개의 행을 추가하겠습니다.
101번지에 사는 Andrea Lloyd 씨는 2012년 11월 23일에 왔고, 우편번호는 04990이며, 월세는 70이라고 가정합니다.
insert into resid
values(101, 'Andrea Lloyd', to_date('2012/11/23', 'YYYY/MM/DD'), 04990, 70);RESID 테이블이 존재하는 상태에서 위 SQL 문장을 실행(Ctrl+Enter)하면, 1개 행이 삽입되었다는 알림 문구가 하단에 출력된 모습을 볼 수 있습니다.

* 문법에 맞지 않는 문장일 경우, 오류(ORA-00984)가 발생할 수 있습니다.
오류가 발생한 경우에는 행이 추가되지 않습니다.
SQL 오류: ORA-00984: 열을 사용할 수 없습니다
00984. 00000 - "column not allowed here"
*Cause:
*Action:
INSERT INTO로 4개 행을 더 추가합니다.
insert into resid
values(102, 'Yanis Grey', to_date('2015/04/13', 'YYYY/MM/DD'), 04991, 100);
insert into resid
values(103, 'Eloin Cleveth', to_date('2008/09/26', 'YYYY/MM/DD'), 04990, 90);
insert into resid
values(104, 'Luca Turilli', to_date('2019/02/05', 'YYYY/MM/DD'), 00000, 50);
insert into resid
values(201, 'Sabine Idel', to_date('2013/07/04', 'YYYY/MM/DD'), null, 65);위 4개의 SQL 문장을 각각 실행하면, 각각의 행이 RESID 테이블에 삽입되었음이 스크립트 출력창에 나타납니다.

2) RESID 테이블에 INSERT INTO로 추가한 행 확인하기
select * from resid;SELECT FROM 구문을 이용해 RESID 테이블에 INSERT INTO로 입력한 행이 추가되었는지 확인하고자 합니다.
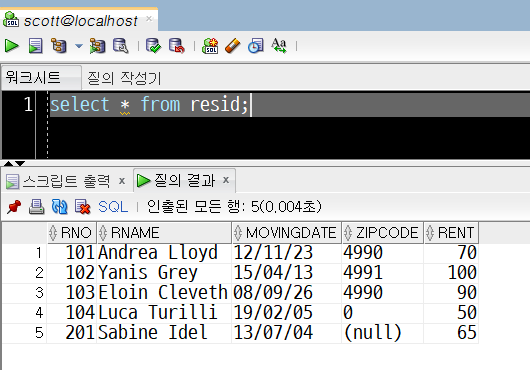
총 5개의 행이 RESID 테이블에 추가된 상태임을 알 수 있습니다.
INSERT SELECT : 테이블Y의 데이터를 선택하여, 테이블X로 복사하기(≒ 레코드 복사 + 붙여넣기)
1. INSERT SELECT의 개념과 표현
1) INSERT SELECT의 개념
INSERT SELECT 구문은 테이블Y에서 조건에 따라 검색한 컬럼의 데이터들을 테이블X의 컬럼에 삽입하는 기능을 합니다. 즉, 테이블Y에서 조건에 맞는 행을 복사하여 테이블X에 붙여넣기 한다고도 이해할 수 있습니다.
|
구문
|
특징
|
|
INSERT INTO
|
1개의 테이블에 1개의 행을 입력하기
|
|
INSERT SELECT
|
테이블2에서 검색한 컬럼의 데이터들을 테이블1의 컬럼에 삽입(복사+붙여넣기)
|
|
INSERT ALL INTO
|
여러 테이블에 여러 행 입력, 다른 테이블에 동시에 같은 행 입력하기
|

2) INSERT SELECT 구문의 표현 :
테이블Y에서 조건에 맞는 레코드를 테이블X에 복사하기
테이블의 모든 컬럼을 복사하지 않더라도, 복사될 테이블의 데이터 유형과 제약조건에 맞도록 일부 컬럼만을 선택하여 복사할 수 있습니다.
insert into 테이블이름X (컬럼이름XA,컬럼이름XB,...)
select 컬럼이름YA,컬럼이름YB, ...
from 테이블이름Y
where 조건;
* 이하의 예제에서는 scott 연습계정을 사용합니다.
2. 예제 : INSERT SELECT 의 사용
ⓐ 임의의 테이블 samp를 만들기 : gid(숫자), gname(문자), gmoney(숫자) 컬럼 생성
ⓑ scott 연습계정에서 sal>0인 레코드들에 대하여 empno, ename 컬럼을 복사하여 gid, gname에 붙여넣기
먼저 gid, gname, gmoney 컬럼을 갖는 테이블 samp를 만듭니다.
create table samp(
gid number(6) constraint pk_01 primary key,
gname varchar(30) constraint nn_02 not null,
gmoney number(10) constraint ck_01 check (gmoney>=0)
)
;
samp 테이블이 생성되었다면, 이제 여기에 emp테이블에서 조건에 맞는 레코드들만 복사하여 붙여넣기 해주어야 합니다.
sal > 1000 인 레코드에 대하여 empno, ename 컬럼의 내용들을 복사하는 INSERT SELECT 구문은 다음과 같습니다.
insert into samp(gid, gname)
select empno, ename
from emp
where sal>1000;위 SQL 문장을 실행(Ctrl+Enter)하면, emp테이블의 전체(12명) 중 조건에 맞는 10명의 레코드가 복사되었다는 알림이 스크립트 창에 출력됩니다.

총 10개 행이 emp 테이블로부터 samp 테이블로 삽입(복사) 되었습니다.
INSERT SELECT의 결과를 보려면, samp 테이블 전체를 조회해 보도록 합니다.
select * from samp;

emp 테이블의 지정한 조건에 따른 값들이 복사되었습니다.
복사대상이 아니었던(지정되지 않은) gmoney 컬럼은 비어있는 상태이므로 null로 표시되고 있습니다.
INSERT ALL : 여러개의 테이블에 동시에 데이터 입력하기 (각각 다른 데이터 입력하기, 다른 테이블의 레코드 복사하기, ...)
1. INSERT ALL의 개념과 표현
1) INSERT ALL의 개념
INSERT ALL은 한꺼번에 여러 개의 테이블에 데이터를 입력하거나, 1개의 테이블(테이블A)로부터 다른 여러 개의
테이블(테이블X, 테이블Y,...)로 데이터를 복사하여 입력할 때 사용합니다.
즉, INSERT ALL은 여러개의 테이블에 동시에 데이터를 입력하기 위해 사용하는 구문입니다.
|
구문
|
특징
|
|
INSERT INTO
|
1개의 테이블에 1개의 행을 입력하기
|
|
INSERT SELECT
|
테이블2에서 검색한 컬럼의 데이터들을 테이블1의 컬럼에 삽입(복사+붙여넣기)
|
|
INSERT ALL INTO
|
여러 테이블에 여러 행 입력, 다른 테이블에 동시에 같은 행 입력하기
|
2) INSERT ALL의 표현
INSERT ALL을 사용하여 여러 개의 테이블에 동시에 데이터를 입력하는 몇 가지의 다른 유형들이 있습니다.
(1) 기본식 : 서로 다른 테이블 X,Y 2개에 각각 다른 데이터를 입력하기
INSERT ALL 다음에 각기 테이블 이름, 컬럼 이름, 컬럼에 투입할 값을 지정해 줍니다.
이때 데이터들은 다른 테이블로부터 복사해온 값이 아니기 때문에, 마지막 SELECT-FROM 구문에서 가상테이블 DUAL을 사용해 줍니다.
insert all
into 테이블이름X(컬럼이름AX,컬럼이름BX) values (값X1, 값X2)
into 테이블이름Y(컬럼이름AY,컬럼이름BY) values (값Y1, 값Y2)
select * from dual;위 식은
- 테이블X의 컬럼AX, 컬럼BX에 값 X1, X2를 입력하고
- 테이블Y의 컬럼AY, 컬럼BY에 값 Y1, Y2를 입력합니다.
(2) 기본식 : 다른 테이블 A의 데이터를 테이블x, 테이블Y에 각각 입력하기
값을 새로 입력하지 않고, 기존에 존재하는 테이블A로부터 테이블X와 테이블Y로 원하는 부분을 복사+붙여넣기 할 수도 있습니다.
insert all
when 조건A1 then
into 테이블이름X (컬럼이름X1, 컬럼이름X2)
when 조건A2 then
into 테이블이름Y (컬럼이름Y1, 컬럼이름Y2)
select 컬럼이름A1, 컬럼이름A2
from 테이블이름A;
위 식은 다음과 같은 기능을 수행합니다.
- 테이블A의 컬럼A1, 컬럼A2에 대하여
- 테이블A의 레코드 중 조건A1을 만족하는 행들은 : 테이블X의 컬럼X1, 컬럼X2로 입력
- 테이블A의 레코드 중 조건A2를 만족하는 행들은 : 테이블Y의 컬럼Y1, 컬럼Y2로 입력
(3) 기본식 : 다른 테이블에 동시에 같은 데이터 입력하기
또는, 테이블A로부터 선택한 같은 행들을 테이블X와 테이블Y에 동시에 입력할 수도 있습니다.
insert all
into 테이블이름X (컬럼이름X1, 컬럼이름X2)
into 테이블이름Y (컬럼이름Y1, 컬럼이름Y2)
select 컬럼이름A1, 컬럼이름A2
from 테이블이름A
where 조건A1;- 테이블A의 컬럼A1, 컬럼A2에 대하여
- 조건A1을 만족하는 행들을
- 테이블X의 컬럼X1과 컬럼X2에 복사하고,
- 테이블Y의 컬럼Y1과 컬럼Y2에 복사
* 이하의 예제에서는 scott 연습계정을 사용합니다.
2. 예제 : INSERT ALL 구문의 사용
먼저, 예제에 사용하기 위하여 임의의 테이블 emp2, empg를 생성합니다.
emp2 - 컬럼 : empno, ename, esal
empg - 컬럼 : gno, gname, zipcode
create table emp2 (
empno number(4,0) constraint pk_empno primary key,
ename varchar2(30) constraint nn_ename not null,
esal number(10,0)
)
;
create table empg (
gno number(4,0) constraint pk_gno primary key,
gname varchar2(20) constraint nn_gname not null,
zipcode varchar2(10)
)
;
위 SQL 문장을 각각 실행하면, 테이블 emp2와 테이블 empg가 생성되었다고 각각 스크립트 출력창에 메시지가 나타나게 됩니다.


1) 예제 : 서로 다른 테이블 emp2,empg에 각각 다른 데이터를 입력하기
ⓐ emp2 테이블에는 empno:0001, ename:Andrea Lloyd 레코드 입력
ⓑ empg 테이블에는 gno:1000, gname:Yanis Grey 레코드 입력
서로 다른 테이블에 각각 다른 레코드를 1줄씩 입력하는 경우입니다.
가상테이블DUAL을 사용하여, 각 테이블의 컬럼에 직접 VALUES를 지정해 줍니다.
insert all
into emp2(empno, ename) values (0001, 'Andrea Lloyd')
into empg(gno, gname) values (1000, 'Yanis Grey')
select * from dual;
INSERT ALL 결과,
- emp2 테이블에 1개 행
- empg 테이블에 1개 행
도합 2개 행이 삽입되었다고 스크립트 출력창에 메시지가 나타났습니다.
각각의 테이블을 확인해 보면, Andrea Lloyd / Yanis Grey 레코드가 추가된 것을 볼 수 있습니다.
select * from emp2;
select * from empg;

2) 예제 : emp테이블의 데이터를 emp2, empg 테이블에 각각 입력하기
ⓐ emp2테이블에는 emp테이블 중 이름(ename)에 'Z'가 들어가는 행을 삽입
ⓑ empg 테이블에는 emp테이블 중 이름에 'T'가 들어가는 행을 삽입
각 조건에 따라, emp테이블의 각 조건에 따라 emp2, empg 테이블에 복사되는 행이 달라질 수 있습니다. INSERT ALL에 WHEN-THEN, SELECT-FROM을 함께 사용하여 SQL 문장을 구성합니다.
insert all
when lower(ename) like '%z%' then
into emp2 (empno, ename)
when lower(ename) like '%t%' then
into empg (gno, gname)
select empno, ename
from emp;위 문장을 실행(Ctrl+Enter)하면, 조건을 충족한 행의 지정된 컬럼들이 emp2, empg 테이블에 삽입됩니다.



emp테이블에서 이름에 Z(z)가 포함된 레코드는 없었으므로, emp2 테이블에는 아무것도 추가되지 않았습니다.
그러나 이름에 T(t)가 포함되는 레코드(SMITH, MARTIN, TURNER의 행)는 empg 테이블에 추가된 것을 발견할 수 있습니다.
3) 예제 : emp2, empg 테이블에 동시에 같은 데이터 입력하기
- emp 테이블에서 이름(ename)에 'E(e)'가 들어가는 레코드의 empno, ename컬럼
(* rollback 등을 사용하여, '예제1)'의 상황에서 이어집니다. rollback 등을 사용하여, 예제 '2)'에서 추가된 행이 있었다면 그 이전의 상태로 되돌려 주세요.)
특정 테이블(A)로부터 여러 개의 테이블(X, Y,...)에 같은 데이터를 입력할 경우에도 INSERT ALL 구문을 사용하지만, 이때 WHEN-THEN 절은 각 테이블X, Y마다 들어가지 않고 SELECT-FROM 절의 마지막 부분에 공통사항으로 등장합니다.
insert all
into emp2 (empno, ename)
into empg (gno, gname)
select empno, ename
from emp
where lower(ename) like '%e%';

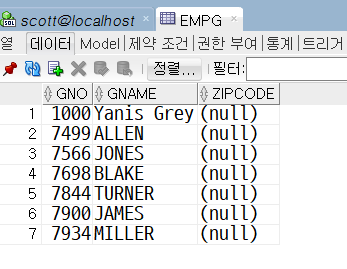
emp2테이블, empg 테이블에 각각 이름에 'E'가 포함된 같은 레코드가 입력되었습니다.
'Structured Query Language > Oracle SQL' 카테고리의 다른 글
| Oracle SQL 기본_12 (1) | 2023.04.28 |
|---|---|
| Oracle SQL 기본_11 (0) | 2023.04.27 |
| Oracle SQL 기본_09 (1) | 2023.04.25 |
| Oracle SQL 기본_08 (0) | 2023.04.24 |
| Oracle SQL 기본_07 (0) | 2023.04.21 |



