SELF JOIN(셀프 조인) : 1개 테이블 내에서 JOIN하여 가상으로 2개 테이블처럼 만들어 작업하기 (테이블 1개 JOIN)
JOIN 기능은 주로 2개 이상의 테이블들로부터 필요한 자료를 불러와 한 개의 조회결과를 만드는 데 사용되곤 합니다. 하지만 종종 1개의 테이블 내에서 JOIN을 한 결과가 필요한 경우가 있습니다.
- 직원들 간에 위계 관계(상하관계)가 있고, 이것이 1개의 테이블의 같은 컬럼에 포함된 경우
- 1개 반 학생들이 2인 1조로 구성되어 있는 경우
- 음식점의 메뉴에 단품 메뉴와 세트메뉴가 함께 섞여 있는 구성인 경우
...
이러한 경우에 SQL에서 SELF JOIN으로 문제를 해결할 수 있습니다.
1. SELF JOIN의 개념과 표현
1) SELF JOIN의 개념
SELF JOIN이란, 1개의 테이블(X)에 가상으로 x1, x2라는 별칭을 부여하여 2개의 테이블인 것처럼 간주한 뒤 JOIN하는 것입니다. 1개의 컬럼 내에 섞여있는 여러 레코드들을 다른 컬럼을 통해서 위계 또는 관계를 알 수 있는 모습으로 조회할 수 있습니다.

위의 예시는 SELF JOIN의 한 예를 그림으로 나타낸 것입니다.
각 구성원들 간에 멘토-멘티 관계가 있다고 가정할 경우
A - 멘토의 구성원 번호
B - 멘토 성명
C - 멘티의 구성원 번호
이 구성원 테이블을 A컬럼과 C컬럼을 기준으로 SELF JOIN 하여,
멘토 번호-멘토 성명-멘티 번호-멘티 성명을 한 화면에서 조회할 수 있게 됩니다.
* 또한, SELF JOIN도 INNER JOIN, OUTER JOIN으로 문제의 유형에 따라 달리 수행할 수 있습니다.
2) SELF JOIN의 표현식
select x1.컬럼이름A,
x1.컬럼이름B,
x2.컬럼이름C, ...
from 테이블이름X x1, 테이블이름 X x2
where x1.컬럼이름A = X2.컬럼이름C;
- FROM 절 : 테이블1개(X)가 2개인 것처럼, 각각 다른 별칭(x1,x2)을 주어 나열합니다.
- WHERE 조건절 : 테이블X1과 테이블X2의 공통컬럼을 지정하여 관계를 설정해 줍니다.
- SELECT 다음부분 : 조회할 컬럼과 해당 컬럼이 소속된 테이블 이름을 나열하여 줍니다
* 아래의 예제에서는 scott 연습계정의 emp 테이블을 사용합니다.
2. 예제 : SELF JOIN 기법의 사용
1) 예제 : emp 테이블에서
ⓐ SELF JOIN 기법을 사용하여
ⓑ 직원번호(empno), 직원성명(ename), 담당매니저번호(mgr), 담당매니저성명(ename)을 출력하기
ⓒ 직원번호가 없거나, 담당매니저가 없으면(mgr is null) JOIN 결과에서 제외
emp 테이블에서 담당 매니저들은 직원 중의 한 명입니다. 따라서 mgr은 empno와 같은 컬럼이라고 간주하여 SELF JOIN을 수행할 수 있습니다. mgr=7800이라면, 이는 매니저의 직원번호가 7800번이라는 의미입니다.
담당매니저의 성명을 함께 조회하고자 한다면 SELF JOIN을 써야 합니다.
또한, SELF JOIN의 종류는 INNER JOIN이 될 것입니다. (* Null 인 결과를 제외)
따라서, emp 테이블은 1개이지만
- 직원 테이블 e1 : empno(직원번호), ename(직원성명), mgr(매니저 직원번호)
- 매니저를 직원으로 보았을 때의 직원테이블 e2 : empno(매니저 직원번호), ename(매니저 직원성명)
과 같은 관계라고 볼 수 있습니다.
emp 테이블이 똑같은 모습의 e1, e2로 2개가 있다고 가상으로 생각하여 JOIN 문장을 작성합니다.
select e1.empno as 직원번호,
e1.ename as 직원성명,
e1.mgr as 담당매니저_직원번호,
e2.ename as 담당매니저_성명
from emp e1, emp e2
where e1.mgr=e2.empno;
e1 emp 테이블의 mgr(매니저 직원번호)는 e2 emp 테이블의 empno(직원번호) 컬럼과 같다고 관계를 설정한 SQL 문장입니다.
오라클 SQL 디벨로퍼에서의 실행(Ctrl+Enter) 결과는 다음과 같습니다.

각 직원들의 담당매니저 직원번호, 담당매니저 성명이 함께 출력된 모습입니다.
본 예제에서는 INNER JOIN을 수행하였으므로, 직원번호(empno) 또는 매니저 직원번호(mgr)가 null인 레코드는 검색결과에서 제외되었습니다
2) 예제 : emp 테이블에서
ⓐ SELF JOIN 기법을 사용하여
ⓑ 직원번호(empno), 직원성명(ename), 담당매니저번호(mgr), 담당매니저성명(ename)을 출력하기
ⓒ 직원의 담당매니저가 없어도(mgr is null) JOIN 결과에 모두 포함시킬 것
이 예제는 '1)'과 동일하지만, 담당매니저(mgr)가 없는 직원도 모두 조회결과에 포함시켜야 하므로 OUTER JOIN을 사용하여야 합니다.
ANSI 문법으로 SQL 문장을 작성하면 아래와 같습니다.
select e1.empno as 직원번호,
e1.ename as 직원성명,
e1.mgr as 담당매니저_직원번호,
e2.ename as 담당매니저_성명
from emp e1 left join emp e2
on e1.mgr=e2.empno;위 문장을 실행(Ctrl+Enter)한 결과는 다음과 같습니다.

모든 직원의 레코드가 출력되었고, 이들의 담당 매니저 데이터가 없어도(null이어도) 해당 사항이 함께 표시되었습니다.
JOIN 심화 : 3개, 4개 이상의 테이블을 JOIN 하는 경우(multiple joins)
2개의 테이블을 JOIN 하기도 하고, 1개 테이블 내에서 SELF JOIN을 하기도 합니다. 물론, 3개, 4개, 5개... N개의 테이블에 대해서도 INNER JOIN과 OUTER JOIN을 수행할 수 있습니다. (* Multiple Joins)
1. 3개 이상의 테이블을 JOIN하는 경우(Multiple Joins)의 표현
1) X, Y, Z 3개 테이블을 INNER JOIN하는 경우
(1) Oracle 문법
select x.컬럼이름A,
y.컬럼이름B,
z.컬럼이름C, ...
from 테이블이름X x, 테이블이름Y y, 테이블이름Z z, ...
where x.컬럼이름M = y.컬럼이름N
and y.컬럼이름O = z.컬럼이름Q;
테이블 2개를 JOIN할 때와 마찬가지로,
- JOIN할 테이블들에 약칭을 붙여 FROM절에 나열하고,
- 각 테이블들 사이에 연결고리가 될 공통 컬럼 사이의 관계를 정의해 줍니다.
(2) ANSI 문법
select x.컬럼이름A,
y.컬럼이름B,
z.컬럼이름C, ...
from 테이블이름X x join 테이블이름Y y
on x.컬럼이름M = y.컬럼이름N
join 테이블이름Z z
on y.컬럼이름O = z.컬럼이름Q;마찬가지로 Oracle 문법 뿐만 아니라 ANSI 표준 문법으로도 작성할 수 있습니다.
2) X, Y, Z 3개 테이블을 테이블 X를 중심으로 OUTER JOIN하는 경우
: LEFT JOIN 사용, 테이블X의 모든 레코드를 출력
(1) Oracle 문법
INNER JOIN 뿐만 아니라 LEFT JOIN, RIGHT JOIN과 같은 OUTER JOIN도 3개 이상의 테이블들을 JOIN 할 수 있습니다.
이때, 조회 시 기준이 되는 테이블(모든 컬럼을 출력할)을 중심으로 LEFT JOIN 등으로 통일하면 혼동하지 않을 수 있습니다.
select x.컬럼이름A,
y.컬럼이름B,
z.컬럼이름C, ...
from 테이블이름X x, 테이블이름Y y, 테이블이름Z z, ...
where x.컬럼이름M = y.컬럼이름N(+)
and y.컬럼이름O = z.컬럼이름Q(+);
(2) ANSI 문법
select x.컬럼이름A,
y.컬럼이름B,
z.컬럼이름C, ...
from 테이블이름X x left join 테이블이름Y y
on x.컬럼이름M=y.컬럼이름N
left join 테이블이름Z z
on y.컬럼이름O=z.컬럼이름Q;
* 이하의 예제에서는 hr 연습계정의 employees, departments, locations, countries 테이블을 사용합니다.
2. 예제 : 3개 이상의 테이블을 JOIN하는 경우 (테이블 4개 JOIN)
1) hr연습계정의 employees, departments, locatons, countries 테이블을 사용하여
ⓐ 직원의 풀네임, 직원이 소속된 부서의 부서이름(department_name), 해당 부서가 위치한 도시의 이름(city), 해당 도시가 소속된 국가명(country_name) 컬럼을 조회합니다.
ⓑ INNER JOIN을 사용합니다. (* 기준 컬럼에서 null이 있을 경우 해당 레코드를 제외)
- 직원의 풀네임(first_name, last_name) : employees 테이블
- 부서이름(department_name) : departments 테이블
- 도시 이름(city) : locations 테이블
- 국가명(country_name) : countries 테이블
각각의 컬럼은 4개의 테이블에 흩어져 있는 정보이므로 이를 하나로 모아 보려면 JOIN을 사용해야 하는 것입니다.
공통 변수를 찾아서 각 테이블을 연결해 주면, 아래와 같이 SQL 문장을 작성할 수 있습니다.
(1) Oracle 문법
select e.first_name||' '||e.last_name as 직원성명,
d.department_name as 부서명,
l.city as 도시,
c.country_name as 국가
from employees e,
departments d,
locations l,
countries c
where e.department_id=d.department_id
and d.location_id=l.location_id
and l.country_id=c.country_id;
(2) ANSI 문법
select e.first_name||' '||e.last_name as 직원성명,
d.department_name as 부서명,
l.city as 도시,
c.country_name as 국가
from employees e join departments d
on e.department_id=d.department_id
join locations l
on d.location_id=l.location_id
join countries c
on l.country_id=c.country_id;
(3) SQL 문장 실행 결과
위 '(1)' 또는 '(2)'의 문장을 실행(Ctrl+Enter)한 결과는 아래와 같습니다.(* 두 문장의 결과는 같습니다.)

전체 107명의 직원 중 department_id 컬럼이 null이 아닌 총 106명의 레코드가 조회되었습니다.
각 직원의 성명, 직원이 속한 부서 이름, 그 부서가 속한 도시와 국가 이름을 알 수 있습니다.
2) hr연습계정의 employees, departments, locatons, countries 테이블을 사용하여
ⓐ 직원의 풀네임, 직원이 소속된 부서의 부서이름(department_name), 해당 부서가 위치한 도시의 이름(city), 해당 도시가 소속된 국가명(country_name) 컬럼을 조회합니다.
ⓑ 모든 직원의 레코드가 다 출력되도록 OUTER JOIN을 사용합니다. (* 기준 컬럼에 null이 있더라도 employees 테이블의 모든 레코드를 출력)
'1)'의 예제와 대부분이 같지만, 차이점은 'employees' 테이블의 모든 레코드가 출력되어야 하므로 employees 테이블을 중심으로 LEFT JOIN을 해야 하는 상황입니다.
(1) Oracle 문법
select e.first_name||' '||e.last_name as 직원성명,
d.department_name as 부서명,
l.city as 도시,
c.country_name as 국가
from employees e,
departments d,
locations l,
countries c
where e.department_id=d.department_id(+)
and d.location_id=l.location_id(+)
and l.country_id=c.country_id(+);
(2) ANSI 문법
(1)과 (2)의 실행 결과는 같습니다.
select e.first_name||' '||e.last_name as 직원성명,
d.department_name as 부서명,
l.city as 도시,
c.country_name as 국가
from employees e left join departments d
on e.department_id=d.department_id
left join locations l
on d.location_id=l.location_id
left join countries c
on l.country_id=c.country_id;
(3) 실행 결과

department_id 컬럼이 null인 Kimberely Grant 직원의 정보도 출력되어, 전체 직원(107명) 모두의 레코드가 조회되는 결과가 나타났습니다.
JOIN 종류 정리 : INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN, Self JOIN, Multiple JOINs

1. INNER JOIN, OUTER JOIN
1) INNER JOIN, OUTER JOIN의 특성 요약
|
JOIN
|
특성
|
문법
|
||
|
Oracle
|
ANSI
|
|||
|
INNER JOIN
|
EQUI JOIN
|
기준 컬럼의 값이 일치함
|
O
|
O
|
|
NON-EQUI JOIN
|
기준 컬럼의 값이 특정한 범주 내에 위치
|
O
|
O
|
|
|
OUTER JOIN
|
LEFT JOIN
|
JOIN 시 기준이 되는 테이블의 레코드를 전부 출력
|
O
|
O
|
|
RIGHT JOIN
|
O
|
O
|
||
|
FULL JOIN
|
JOIN 시 null이 있더라도 전부 출력
|
X
|
O
|
|
2) INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN의 관계

3) INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN의 조회결과 레코드 비교

명령어 분류 · 주요 명령어 정리 : DQL, DML, DDL, DCL, TCL
|
분류
|
명령어
|
기능
|
|
|
DQL
|
Data Query Language
|
SELECT
|
선택
|
|
DML
|
Data Manipulation Language :
테이블 데이터(레코드) 편집
|
INSERT
|
데이터 입력
|
|
UPDATE
|
데이터 업데이트
|
||
|
DELETE
|
데이터 삭제
|
||
|
MERGE
|
데이터 병합
|
||
|
DDL
|
Data Definition Language :
테이블 설정 편집
|
CREATE
|
테이블 생성
|
|
DROP
|
테이블 일체 삭제
|
||
|
ALTER
|
테이블 변경
|
||
|
TRUNCATE
|
테이블 데이터 삭제
|
||
|
COMMENT
|
테이블 데이터 삭제
|
||
|
DCL
|
Data Control Language
|
GRANT
|
권한 부여
|
|
REVOKE
|
권한 박탈
|
||
|
TCL
|
Transaction Control Language
|
COMMIT
|
변경사항 확정
|
|
ROLLBACK
|
변경사항 취소(* 이전 커밋까지)
|
||
|
SAVEPOINT
|
ROLLBACK TO SAVEPOINT는 현재 트랜잭션을 지정된 저장점으로 롤백
|
||
LEAD, LAG : 이전 행 값, 이후 행 값을 불러오는 함수 (ex. 누적도수분포로부터 도수를 구하기, 급여 차이 구하기, 성적 차이 구하기)
순서대로 정렬한 레코드에서 특정한 컬럼을 기준으로 이전 레코드의 값 또는 이후 레코드의 값을 불러와야 하는 경우가 있습니다.
- 특정한 변수를 기준으로 순서를 정렬하여, 직전 레코드의 값과 급여 또는 시급과 같은 정보를 비교할 경우(크고 작음, 대소의 비교)
- 누적도수분포 정보를 담은 테이블에서, 각 누적도수간 차이(=도수)를 계산하기 위한 경우
- 직원들 간의 임금 격차를 순차적으로 비교하는 경우
- 학생들 개인의 점수, 또는 학급별 평균점수 간 격차(평균성적의 차이)를 구하려는 경우
...
와 같은 목적을 가지고 있을 때, 직전/직후 레코드와의 차이를 보여주거나 격차를 구하기 위한 수단으로 LAG 또는 LEAD 함수를 사용할 수 있습니다.
1. LAG, LEAD 함수의 개념과 표현
1) LAG, LEAD 함수의 개념
LAG 함수는 특정 컬럼을 기준으로 직전 m번째 레코드 값을,
LEAD 함수는 직후 m번째 레코드 값을 출력해 주는 함수입니다.
|
함수
|
의미
|
|
LAG(□,m,n) OVER(ORDER BY ■)
|
- 컬럼■를 기준으로 레코드를 정렬한 뒤
- 컬럼□의 값을 기준으로,
- 정렬된 레코드 중 직전 m번째 레코드 값 출력
- 출력할 값이 없으면(컬럼■ 기준 정렬 시 첫번째 행) n 출력
|
|
LEAD(□,m,n) OVER(ORDER BY ■)
|
- 컬럼■를 기준으로 레코드를 정렬한 뒤
- 컬럼□의 값을 기준으로,
- 정렬된 레코드 중 직후 m번째 레코드 값 출력
- 출력할 값이 없으면(컬럼■ 기준 정렬 시 마지막 행) n 출력
|
2) LAG, LEAD 함수의 표현
(1) LAG 함수의 기본식
select 컬럼이름A,
lag(컬럼이름X, 오프셋숫자m, 기본출력숫자n) over(order by 컬럼이름Y)
from 테이블이름
order by 컬럼이름Z;
- 컬럼X, 컬럼Y, 컬럼Z는 같은 컬럼이 될 수 있습니다.
적지 않은 경우에 같은 컬럼입니다.
- n은 숫자를 권장합니다. 출력할 값이 없으면(컬럼Y를 기준으로 정렬했을 때 이전 행이 없는 경우 ≒ 첫번째 행으로부터 m번째까지의 행) n이 출력됩니다. n이 문자열일 경우, 해당 레코드의 LAG 값은 컬럼X의 값과 같게 출력됩니다.
- m은 컬럼Y를 기준으로 정렬했을 때, 몇(m) 번째 이전 레코드를 출력할지 간격(offset)을 결정하는 요소입니다.
※ m이 음의 정수일 경우, 오류(ORA-01428)이 발생합니다.
ORA-01428: '-1' 인수가 범위를 벗어났습니다
01428. 00000 - "argument '%s' is out of range"
*Cause:
*Action:
※ m이 소숫점 아래 값을 가진 양수일 경우, 오류는 발생하지 않지만 반올림된 정수로 간주됩니다.
※ m=0일 경우, LAG 값과 LEAD 값은 투입한 값(컬럼X) 자신이 됩니다.
(2) LEAD 함수의 기본식
select 컬럼이름A,
lead(컬럼이름X, 오프셋숫자m, 기본출력숫자n) over(order by 컬럼이름Y)
from 테이블이름
order by 컬럼이름Z;
- 컬럼X, 컬럼Y, 컬럼Z는 같은 컬럼이 될 수 있습니다.
적지 않은 경우에 같은 컬럼입니다.
- n은 숫자를 권장합니다. 출력할 값이 없으면(컬럼Y를 기준으로 정렬했을 때 이전 행이 없는 경우≒첫번째 행으로부터 m번째까지의 행) n이 출력됩니다. n이 문자열일 경우, 해당 레코드의 LAG 값은 컬럼X의 값과 같게 출력됩니다.
- m은 컬럼Y를 기준으로 정렬했을 때, 몇(m) 번째 이전 레코드를 출력할지 간격(offset)을 결정하는 요소입니다.
※ m이 음의 정수일 경우, 오류(ORA-01428)이 발생합니다.
ORA-01428: '-1' 인수가 범위를 벗어났습니다
01428. 00000 - "argument '%s' is out of range"
*Cause:
*Action:
※ m이 소숫점 아래 값을 가진 양수일 경우, 오류는 발생하지 않지만 반올림된 정수로 간주됩니다.
※ m = 0일 경우, LAG 값과 LEAD 값은 투입한 값(컬럼X) 자신이 됩니다.
* 이하의 예제에서는 hr 연습계정의 employees 테이블을 사용합니다.
2. 예제 : LAG, LEAD 함수의 표현
1) 예제 : employees 테이블에서
ⓐ 직원의 성명(first_name과 last_name), 직책ID(job_id), 급여(salary)를 출력하고, 이와 함께
ⓑ 급여를 기준으로 전체 레코드를 정렬했을 때, 직전 레코드의 급여값/직후 레코드의 급여값을 각각 출력하기
ⓒ 직전/직후 행이 없으면 직후 레코드 급여값/직전 레코드 급여값은 0으로 처리합니다.
- LAG, LEAD 함수 모두 출력하려는 값도 정렬하는 기준도 모두 급여(salary) 컬럼이 됩니다.
- 직전, 직후 레코드이므로 m=1이 될 것입니다.
- 직전/직후 행이 없을 경우 투입할 값은 n=0입니다.
이상의 정보를 바탕으로 SQL 문장을 구성하면 아래와 같습니다.
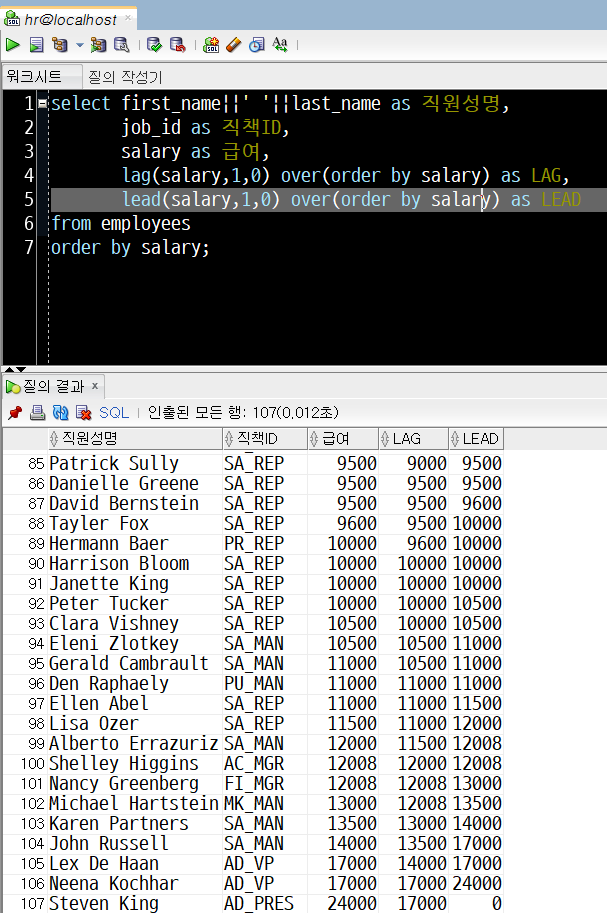
select first_name||' '||last_name as 직원성명,
job_id as 직책ID,
salary as 급여,
lag(salary,1,0) over(order by salary) as LAG,
lead(salary,1,0) over(order by salary) as LEAD
from employees
order by salary;LAG 컬럼은 salary 컬럼을 기준으로 직전 레코드의 급여(salary) 값을,
LEAD컬럼은 salary 컬럼을 기준으로 직후 레코드의 급여(salary) 값을 보여줄 것입니다.
위 SQL 문장을 실행(Ctrl+Enter)하면 아래와 같습니다.
2) 예제 : '1)'의 예제와 같은 상황에서 다음의 컬럼을 추가하기
ⓐ 직전 레코드(직원)와의 급여 차이
ⓑ 직후 레코드(직원)와의 급여 차이
즉, salary 컬럼을 기준으로 전 직원의 레코드를 정렬하였을 때 직전/직후에 놓인 직원들과 서로 salary값을 비교하여 차이를 나타내는 것입니다.
- 직전 레코드(직원)와의 급여 차이 : LAG_GAP
- 직후 레코드(직원)와의 급여 차이 : LEAD_GAP
으로 정의하여 '1)'의 예제에서 각각의 컬럼을 추가하면 다음의 예시를 들 수 있습니다.
select first_name||' '||last_name as 직원성명,
job_id as 직책ID,
salary as 급여,
lag(salary,1,0) over(order by salary) as LAG,
lead(salary,1,0) over(order by salary) as LEAD,
(salary-(lag(salary,1,0) over(order by salary))) as LAG_GAP,
((lead(salary,1,0) over(order by salary))-salary) as LEAD_GAP
from employees
order by salary;
위 문장을 실행하면 오라클 SQL 디벨로퍼는 다음과 같은 결과를 출력합니다.

급여 차이가 각각 LAG_GAP, LEAD_GAP 컬럼에 나타납니다.
- 같은 급여를 받는 직원끼리의 차이는 0
- 급여에 차이가 있을 경우 그 값은 0보다 크게 나타나고 있음을 알 수 있습니다.
같은 방법으로 누적도수분포 테이블에서 각 등급/계급/집단별 도수를 산정할 수도 있습니다.
3) 예제 : '1)'의 예제와 비교
ⓐ 직원의 성명(first_name과 last_name), 직책ID(job_id), 급여(salary)를 출력하고, 이와 함께
ⓑ 급여를 기준으로 전체 레코드를 정렬했을 때, 이전 2번째 레코드의 급여값/이후 2번째 레코드의 급여값을 각각 출력하기
ⓒ 이전, 이후 해당하는 행이 없으면 직후 레코드 급여값/직전 레코드 급여값은 999로 처리
모두 같은 조건에서 m=2, n=999로 바꾸었을 경우의 결과 예제입니다.
select first_name||' '||last_name as 직원성명,
job_id as 직책ID,
salary as 급여,
lag(salary,2,999) over(order by salary) as LAG,
lead(salary,2,999) over(order by salary) as LEAD
from employees
order by salary;위 SQL 문장을 실행한 결과는 아래와 같습니다.

- 각각 LAG, LEAD 값은 직전/직후 행이 아닌 2개 행 전/2개 행 후 row의 salary 값을 따르고 있음을 알 수 있습니다. (m=2)
- 또한, 직전 m번째/직후 m번째 항이 없을 경우(LAG는 첫번째로부터 m번째 행까지, LEAD는 마지막 행부터 m개 행) 그 값이 999로 출력됩니다. (n=999)
3) 예제 : ORDER BY 기준에 차이가 있을 경우
다른 모든 조건은 '1)'과 같되, job_id를 기준으로 컬럼을 정렬한 후 이전/이후 salary 값을 출력하도록 하는 경우에 해당합니다.
select first_name||' '||last_name as 직원성명,
job_id as 직책ID,
salary as 급여,
lag(salary,1,0) over(order by job_id) as LAG,
lead(salary,1,0) over(order by job_id) as LEAD
from employees
order by job_id;(order by job_id)로 바꾸었습니다.
'1)'과 비교를 위해 위 문장을 실행해 봅니다.
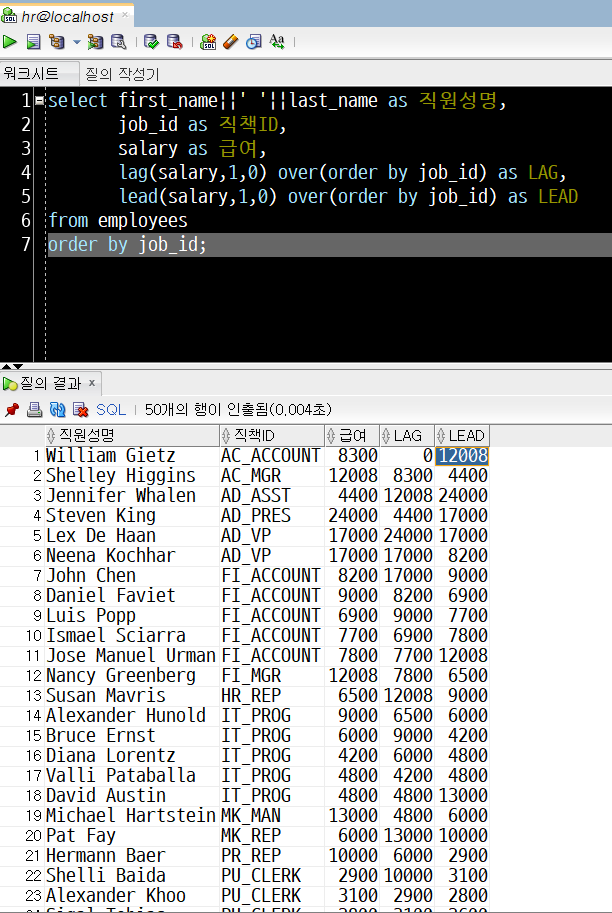
이번에는 job_id를 기준으로 오름차순 정렬된 다음, 그 상태를 기준으로 이전/이후 row의 salary 컬럼 값이 각각 LAG, LEAD로 출력되고 있습니다.
* 이슈와 필요에 따라서 적절한 LAG, LEAD 식을 구성하는 것이 가장 좋을 것입니다.
'Structured Query Language > Oracle SQL' 카테고리의 다른 글
| Oracle SQL 기본_11 (0) | 2023.04.27 |
|---|---|
| Oracle SQL 기본_10 (1) | 2023.04.26 |
| Oracle SQL 기본_08 (0) | 2023.04.24 |
| Oracle SQL 기본_07 (0) | 2023.04.21 |
| Oracle SQL 기본_06 (1) | 2023.04.20 |



