LISTAGG : 컬럼의 레코드들을 전체 그대로, 또는 그룹별로 1개 칸 속에 나열하기 (LISTAGG WITHIN GROUP(ORDER BY ~ ))
1. LISTAGG 함수의 표현과 그 용도
1) LISTAGG 함수의 용도
특정 컬럼의 내용들을 1개 셀 안에 나열하고 싶을 때 LISTAGG 함수를 사용합니다.
- 레코드의 1개 칸(셀) 내에 전체 직원의 이름 또는 ID를 나열
- 또는, 부서별/직급별/성별로 전체 직원의 이름을 나열
LISTAGG 함수는 개별 컬럼에 대해 사용할 수도 있고, GROUP BY 후 각 그룹별로도 사용할 수 있습니다.

2) LISTAGG 함수의 표현 : 기본식의 예
(1) 개별 컬럼에 대하여 : LISTAGG
select listagg(컬럼이름B, '구분문자') within group(order by 정렬기준컬럼이름Z)
from 테이블이름;
- 컬럼이름B : 데이터가 나열될 컬럼
- '구분문자' : 나열된 데이터 사이를 구분할 문자 (*입력하지 않으면 구분 없이 연속으로 붙어 나열됩니다)
- 정렬기준컬럼이름Z : 컬럼B의 데이터가 나열될 때 정렬 기준이 될 또다른 컬럼. 기본적으로 오름차순 정렬되며, 내림차순으로 정렬하려면 컬럼이름Z 뒤에 desc를 뒤에 붙여 줍니다.
이 정렬기준 Z를 설정해 주지 않으면 오류(ORA-30491)가 발생합니다.
(2) GROUP BY와 함께 LISTAGG 사용
select 컬럼이름A, listagg(컬럼이름B, '구분문자') within group(order by 정렬기준컬럼이름Z)
from 테이블이름
group by 컬럼이름A;그룹별로 나눈 다음 LISTAGG를 사용할 수도 있습니다.
2. 예제 : LISTAGG 함수의 사용
1) 예제 : emp 테이블, ename 컬럼의
- 전체 데이터들을 쉼표(,)로 구분하여 나열하되
- deptno 를 기준으로 오름차순 나열하기
위 조건을 바탕으로 LISTAGG 함수를 사용하여 SQL 문장을 구성하면 아래와 같습니다.
select listagg(ename, ', ') within group(order by deptno)
from emp;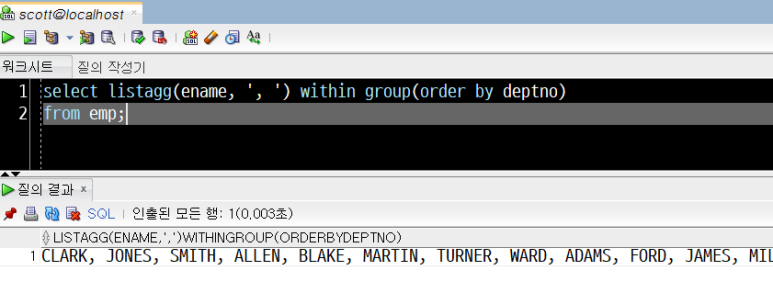
emp 테이블의 모든 직원의 이름이 쉼표로 구분되어 1개 셀 안에 나타났습니다.
2) 예제 : '1)'과 같은 예시에서 구분기호(쉼표)를 누락하는 경우
: 구분문자(쉼표)가 없이, 모든 데이터가 붙어서 연속적으로 나열되어 출력됩니다.
select listagg(ename) within group(order by deptno)
from emp;
3) 오류 예제 : '1)'과 동일한 상황에서
LISTAGG WITHIN GROUP(ORDER BY) 중 ORDER BY를 생략하는 경우
'WITHIN GROUP(ORDER BY 정렬기준컬럼이름Z)'에서, ORDER BY와 결과값을 정렬할 기준이 될 컬럼 Z는 생략할 수 없습니다.
생략할 경우 에러(ORA-30491)가 발생합니다.
select listagg(ename) within group()
from emp;위 SQL 문장은 오류를 유발하는 문장입니다. 이를 실행하면, Oracle SQL Developer는 아래와 같은 오류문구를 내보내게 됩니다.
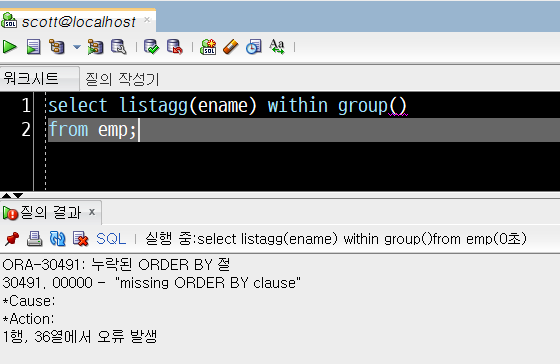
ORA-30491: 누락된 ORDER BY 절
30491. 00000 - "missing ORDER BY clause"
*Cause:
*Action:
1행, 36열에서 오류 발생
4) 예제 : 그룹별 LISTAGG의 사용
scott 연습계정의 emp 테이블
ⓐ GROUP BY를 사용하여 부서번호별로 나누고,
ⓑ LISTAGG를 사용하여 부서별 직원 이름(ename)을 쉼표로 구분하여 1개 셀 내에 부서별로 나열하되
ⓒ 나열되는 이름들은 입사일(hiredate)을 기준으로 오름차순 정렬하기
위 기준에 맞추어 LISTAGG 함수를 사용한 SQL 문장은 아래와 같습니다.
select deptno as 부서번호,
listagg(ename, ', ') within group(order by hiredate) as 전체직원
from emp
group by deptno;- 데이터를 그룹으로 묶을 기준 컬럼 : deptno
- 데이터를 나열할 컬럼 : ename
- 나열할 데이터를 구분할 구분문자 : 쉼표(,)
- 나열할 데이터를 정렬할 기준 컬럼 : hiredate

각 부서별로(10번, 20번, 30번, null) 전체 직원들의 이름이 나열되었습니다.
INNER JOIN - EQUI JOIN(등가 조인)의 개념 및 예제 : 양쪽 테이블에서 공통 컬럼, 같은 값이 존재할 경우에만 레코드를 출력하는 경우
JOIN 기능은 서로 다른 여러 테이블에 나누어져 있는 정보들 중에서 사용자가 필요한 정보만 가져와 한 화면에서 조회할 수 있게 합니다. 아래와 같은 경우에 JOIN은 굉장히 유용하게 쓰일 수 있습니다.
- 직원 정보 테이블, 직원들이 부서 정보 테이블, 부서가 소속된 지역 정보 테이블을 한 번에 조회하기
- 읍면동별 정보 테이블, 시군구별 정보 테이블, 시도별 정보 테이블을 한 번에 모아 조회하기
....
- 여러 테이블의 정보를 통합 /취합 /종합하여 한 개의 테이블로 조회하기
위계가 다른 정보(ex. 지역, 국가, 대륙, ...)들이 각기 다른 테이블로 만들어져 있다면, 각 테이블을 연결할 수 있는 공통 컬럼(변수)을 기준으로 테이블들을 JOIN할 수 도 있습니다.
JOIN은 INNER JOIN / OUTER JOIN으로 구분할 수 있고, INNER JOIN은 다시 EQUI JOIN과 NON-EQUI JOIN으로 나눌 수 있습니다.

본 페이지에서는 INNER JOIN(이너 조인) 중 EQUI JOIN(등가 조인)을 다룹니다.
1. INNER JOIN : EQUI JOIN의 개념과 표현
1) INNER JOIN : EQUI JOIN의 개념
INNER JOIN에서 양쪽 테이블에 같은 조건(공통적으로 갖고 있는 기준 컬럼)이 존재할 경우의 값만을 가져오는 경우입니다. INNER JOIN에서는 한쪽 테이블만에라도 기준 컬럼의 데이터가 null이면 결과값에 나타나지 않습니다.
* null 인 데이터도 조회하고 싶다면 OUTER JOIN을 사용해야 합니다.
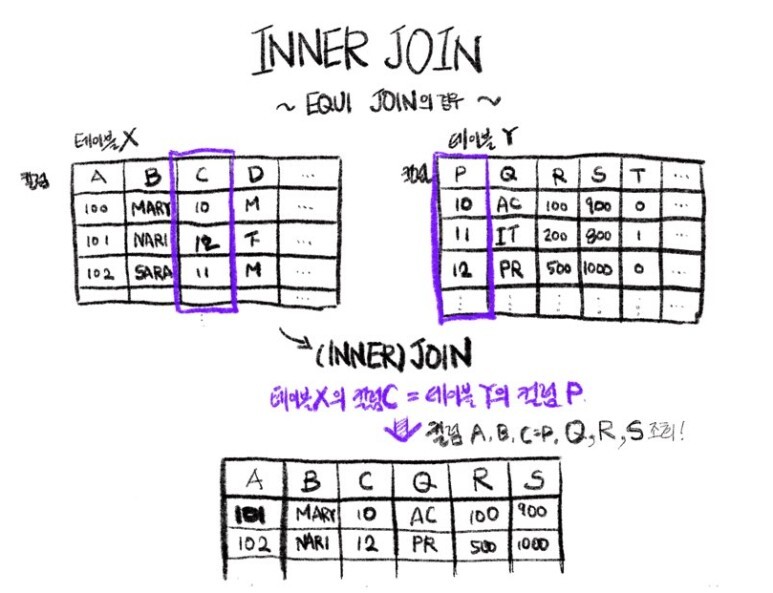
2) INNER JOIN : EQUI JOIN의 표현
오라클 SQL 디벨로퍼의 SQL 문장에서, FULL JOIN을 제외한 나머지 종류의 JOIN들은 2가지 문법으로 표현할 수 있습니다.
- Oracle 문법 : 오라클 프로그램에서 사용 가능한 JOIN 문법입니다.
'join' 명령어를 사용하지 않고, WHERE 조건절에서 JOIN 조건을 지정합니다.
- ANSI 표준 문법 : 다른 SQL 프로그램에서도 공통적으로 사용 가능한 표준 JOIN 문법입니다.
FROM 절에서 'join'명령어를 사용하며, WHERE 조건절과 JOIN절이 구분되는 특성을 갖습니다.
(* OUTER JOIN 중 FULL JOIN은 Oracle 문법이 없어, ANSI 문법만 사용할 수 있습니다)
(1) Oracle 문법 기본식
select x.컬럼이름A,
x.컬럼이름B,
y.컬럼이름P, ...
from 테이블이름X x, 테이블이름 Y y
where x.컬럼이름M=y.컬럼이름N;- FROM 절 : 테이블X와 테이블Y를 JOIN 하는 경우입니다. 테이블X와 테이블Y의 약칭을 각각 x와 y라고 합니다.
- WHERE 조건절 : 테이블X의 컬럼M과 테이블Y의 컬럼N이 같음을 명시합니다. JOIN 시 기준 컬럼이 됩니다.
- SELECT 다음 : 테이블 X의 A,B컬럼, 테이블Y의 P컬럼을 조회합니다.
(2) ANSI 문법 기본식
select x.컬럼이름A,
x.컬럼이름B,
y.컬럼이름C, ...
from 테이블이름X x join 테이블이름 Y y
on x.컬럼이름M=y.컬럼이름N;위 '(1) Oracle 문법'의 예시가 되는 기본식을 ANSI 문법으로 나타낸 것입니다. (1)과 (2)의 결과는 같습니다.
ANSI 문법에서는
- 'join' 명령어를 사용하여 JOIN하는 두 테이블을 지정하고,
- 'on' 다음에는 기준이 되는 컬럼의 관계를 설정합니다.
2. 예제 : INNER JOIN - EQUI JOIN의 사용
1) 예제 : emp테이블의 직원성명(ename), 부서번호(deptno), dept 테이블의 부서이름(dname)을 JOIN을 사용하여 조회하기
- JOIN할 테이블 : emp, dept
- emp 테이블의 약칭 : e, dept 테이블의 약칭 : d
- JOIN 기준 컬럼 : emp 테이블의 deptno=dept 테이블의 deptno
- 조회할 컬럼 : ename, deptno, dname
(1) Oracle 문법
select e.ename as 직원성명,
e.deptno as 부서번호,
d.dname as 부서이름
from emp e, dept d
where e.deptno=d.deptno;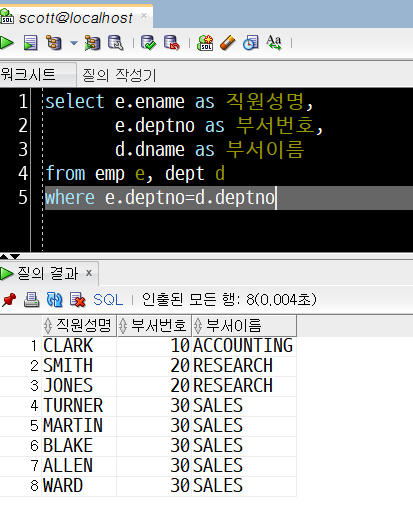
deptno가 null이 아닌 직원들의 직원 성명, 부서번호, 부서이름이 함께 출력되었습니다.
직원성명과 부서번호는 emp테이블에, 부서번호와 부서이름은 dept테이블에 있기 때문에 JOIN을 쓰지 않고 한 화면에서 직원성명과 부서이름을 함께 조회하기 어려웠습니다.
하지만 JOIN 기법은 원본 테이블을 변형시키지 않고도 다른 테이블에 나누어져 있는 정보들을 취합하여 한 화면에서 조회할 수 있게 합니다.

위 이미지는 'select*from emp;'를 통해 조회할 수 있는 emp 테이블이 가지고 있는 데이터 전체입니다.
INNER JOIN의 특성상, 기준 컬럼(deptno)의 값이 null인 레코드는 INNER JOIN 결과에서 제외되었습니다.
(* 만약에 이를 전부 포함한 결과를 원한다면 OUTER JOIN을 사용해야 합니다.)
(2) ANSI 문법
select e.ename as 직원성명,
e.deptno as 부서번호,
d.dname as 부서이름
from emp e join dept d
on e.deptno=d.deptno;같은 예제를 ANSI 문법으로도 작성하였습니다.
위 SQL 문장을 실행한 결과는 다음과 같습니다.
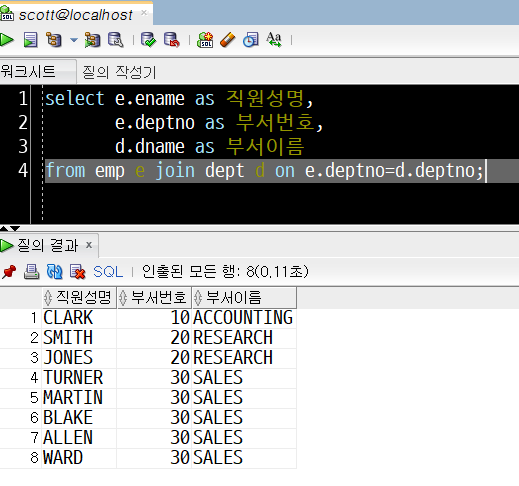
Oracle 문법을 사용했을 때와 ANSI 문법을 사용했을 때의 결과는 같습니다.
INNER JOIN - NON-EQUI JOIN(비등가 조인)의 개념 및 예제 : 한쪽 테이블이 일종의 등급표와 같이범주를 지정하는 역할을 하는 경우

1. INNER JOIN :
NON-EQUI JOIN의 개념과 표현
1) INNER JOIN :
NON-EQUI JOIN의 개념
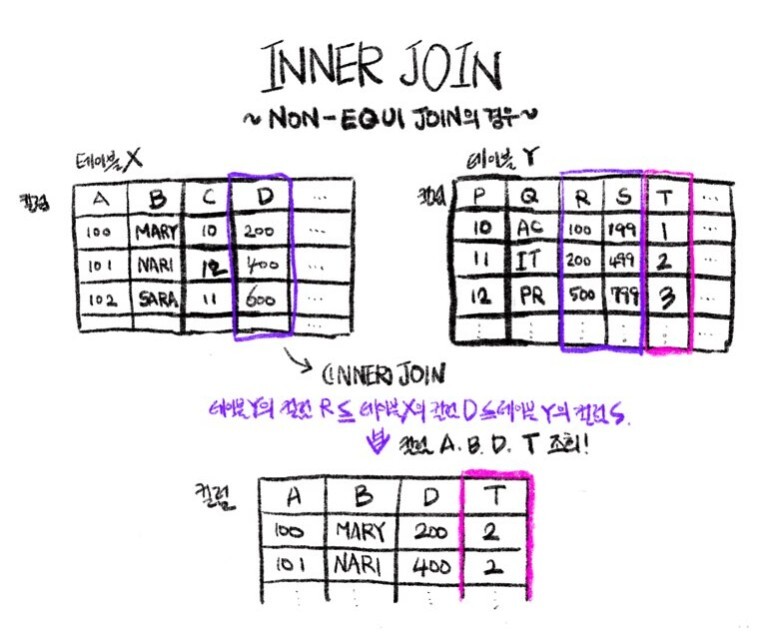
NON-EQUI JOIN(비등가 조인)은 INNER JOIN의 한 종류입니다. EQUI JOIN이 기준이 되는 공통 컬럼에서 "일치하는" 데이터를 기준으로 JOIN을 실시한다면, NON-EQUI JOIN은 기준 컬럼의 값(레코드)이 서로 같지 않더라도 서로가 지정한 범주에 속하는 관계라면 JOIN이 가능합니다. 예컨대,
- 어떤 레코드의 테이블X의 A컬럼 값이
- 테이블Y의 B컬럼이 지정하는 범주 내에 존재하는 경우
- 테이블Y의 C컬럼이 지정하는 값으로 JOIN될 수 있음
위와 같은 경우 A컬럼의 값이 B컬럼의 값과 반드시 일치하지 않더라도 INNER JOIN이 가능하며, 이러한 경우를 비등가 조인(NON-EQUI JOIN)에 해당한다고 할 수 있습니다.
- 고객의 누적 주문금액에 따른 고객 등급 지정
- 학생의 평균 점수에 따른 수준별 분반수업 시 분반 지정
- 직원의 월급 수준에 따른 급여등급 지정
...
위와 같은 예제는 모두 등급을 규정한 범주 역할을 하는 테이블이 존재하고, JOIN하여 이 기준에 따라 개별 레코드에게 값을 지정하여 주는 NON-EQUI JOIN(비등가 조인)에 해당할 것입니다.
* 물론, 비등가 조인도 INNER JOIN이므로, 한쪽 테이블만에라도 기준 컬럼의 데이터가 null이면 결과값에 나타나지 않습니다.
null 인 데이터도 조회하고 싶다면 OUTER JOIN을 사용해야 합니다.
2) INNER JOIN : NON-EQUI JOIN의 표현
오라클 SQL 디벨로퍼의 SQL 문장에서, FULL JOIN을 제외한 나머지 종류의 JOIN들은 2가지 문법으로 표현할 수 있습니다.
- Oracle 문법 : 오라클 프로그램에서 사용 가능한 JOIN 문법입니다.
'join' 명령어를 사용하지 않고, WHERE 조건절에서 JOIN 조건을 지정합니다.
- ANSI 표준 문법 : 다른 SQL 프로그램에서도 공통적으로 사용 가능한 표준 JOIN 문법입니다.
FROM 절에서 'join'명령어를 사용하며, WHERE 조건절과 JOIN절이 구분되는 특성을 갖습니다.
(* OUTER JOIN 중 FULL JOIN은 Oracle 문법이 없어, ANSI 문법만 사용할 수 있습니다)
2) INNER JOIN : NON-EQUI JOIN의 표현
오라클 SQL 디벨로퍼의 SQL 문장에서, FULL JOIN을 제외한 나머지 종류의 JOIN들은 2가지 문법으로 표현할 수 있습니다.
- Oracle 문법 : 오라클 프로그램에서 사용 가능한 JOIN 문법입니다.
'join' 명령어를 사용하지 않고, WHERE 조건절에서 JOIN 조건을 지정합니다.
- ANSI 표준 문법 : 다른 SQL 프로그램에서도 공통적으로 사용 가능한 표준 JOIN 문법입니다.
FROM 절에서 'join'명령어를 사용하며, WHERE 조건절과 JOIN절이 구분되는 특성을 갖습니다.
(* OUTER JOIN 중 FULL JOIN은 Oracle 문법이 없어, ANSI 문법만 사용할 수 있습니다)
(1) Oracle 문법 기본식
select x.컬럼이름A,
x.컬럼이름B,
x.컬럼이름C,
y.컬럼이름T, ...
from 테이블이름X x, 테이블이름 Y y
where x.컬럼이름C between y.컬럼이름R and y.컬럼이름S;- FROM 절 : 테이블X와 테이블Y를 JOIN 하는 경우입니다. 테이블X와 테이블Y의 약칭을 각각 x와 y라고 합니다.
- WHERE 조건절 : 테이블X의 컬럼M이 테이블Y의 컬럼R, 컬럼S와 크고 작은 부등호 관계(>,<,>=,<=, BETWEEN)가 있음을 명시합니다.
- SELECT 다음 : 테이블 X의 A,B컬럼, 테이블Y의 T컬럼을 조회합니다.
(2) ANSI 문법 기본식
select x.컬럼이름A,
x.컬럼이름B,
y.컬럼이름C, ...
from 테이블이름X x join 테이블이름 Y y
on x.컬럼이름C between y.컬럼이름R and y.컬럼이름S;위 '(1)Oracle 문법'의 예시가 되는 기본식을 ANSI 문법으로 나타낸 것입니다. (1)과 (2)의 결과는 같습니다.
ANSI 문법에서는
- 'join' 명령어를 사용하여 JOIN하는 두 테이블을 지정하고,
- 'on' 다음에는 기준이 되는 컬럼의 관계를 설정합니다.
따라서 WHERE 조건절과 JOIN 구문이 분리되는 것이 ANSI JOIN 문법의 특징입니다.
2. 예제 : INNER JOIN
- NON-EQUI JOIN의 사용
scott 연습계정의 emp테이블은 직원들의 성명, 부서 정보, 급여 정보(sal)를 포함하는 테이블입니다
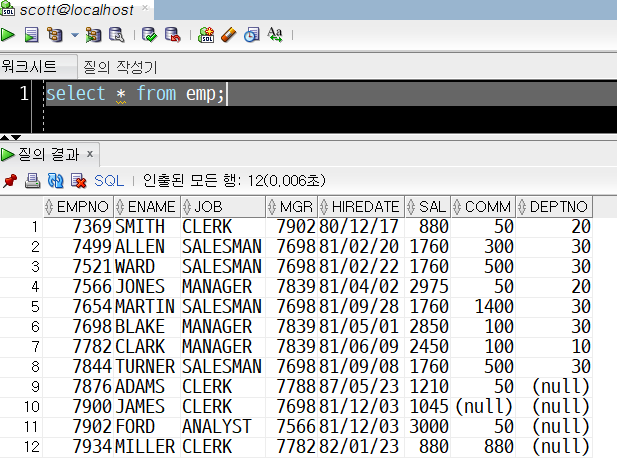
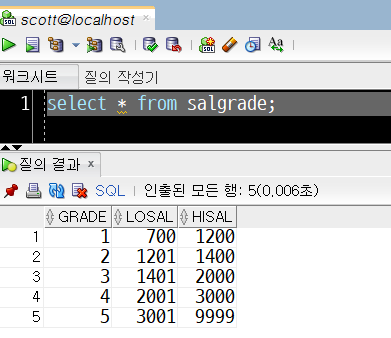
또한 scott 연습계정의 salgrade 테이블은 각 급여 범주별 등급을 정하는 일종의 등급표 역할을 하는 테이블입니다.
salgrade 테이블에 따르면,
- 급여는 등급으로 나뉠 수 있고(salgrade)
- 급여 등급(salgrade)은 그 등급의 최소 급여(losal)와 최대 급여(hisal) 범주에 포함될 경우 주어지는 것입니다.
emp 테이블에서 각각의 직원들의 급여(sal)가 어느 범주에 속하느냐에 따라 해당 직원의 급여 등급도 결정될 것입니다.
1) 예제 : emp테이블의 직원성명(ename), 급여(sal), salgrade 테이블의 급여등급(salgrade)을 JOIN을 사용하여 조회하기
- JOIN할 테이블 : emp, salgrade
- emp 테이블의 약칭 : e, salgrade 테이블의 약칭 : s
- JOIN 기준 컬럼 : emp테이블의 sal은 salgrade테이블의 losal과 hisal 사이에 위치함
- 조회할 컬럼 : ename, sal, salgrade
select e.ename as 직원성명,
e.sal as 급여,
s.grade as 급여등금
from emp e, salgrade s
where e.sal between s.losal and s.hisal;
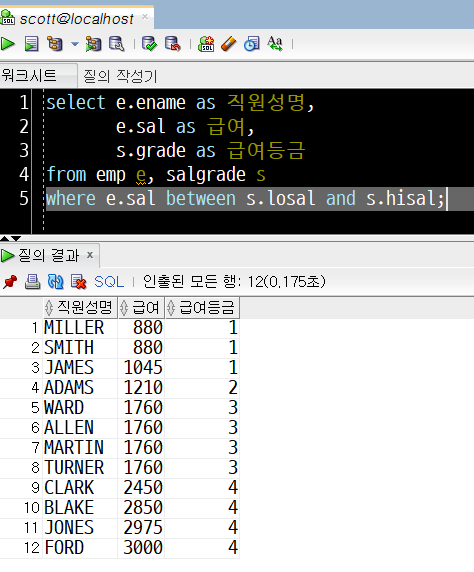
sal이 null이 아닌 직원들의 성명, 급여(sal), 급여등급이 출력되었습니다.
직원성명과 급여는 emp테이블에, 급여등급은 salgrade 테이블에 있는 변수(컬럼)입니다. 따라서 JOIN을 사용하지 않으면 한 화면에서 직원성명과 부서이름을 함께 조회하기 어려웠습니다.
하지만 JOIN 기법은 원본 테이블을 변형시키지 않고도 다른 테이블에 나누어져 있는 정보들을 취합하여 한 화면에서 조회할 수 있게 합니다.
(2) ANSI 문법
같은 예제를 ANSI 문법으로도 작성하였습니다.
select e.ename as 직원성명,
e.sal as 급여,
s.grade as 급여등금
from emp e join salgrade s
on e.sal between s.losal and s.hisal;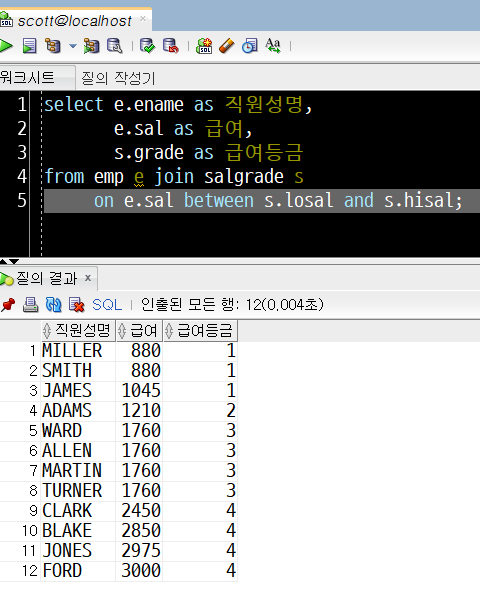
Oracle 문법을 사용했을 때와 ANSI 문법을 사용했을 때의 결과는 같습니다.
OUTER JOIN - LEFT JOIN, RIGHT JOIN : 한쪽 테이블의 전체 레코드를 기준으로 JOIN 결과에 출력하는 방법

1. OUTER JOIN :
LEFT JOIN, RIGHT JOIN의 개념과 표현
1) OUTER JOIN의 개념
INNER JOIN(이너 조인)은 조인된 두 테이블에서, 조인 기준이 된 컬럼에 데이터가 양쪽 모두 존재하는 경우에만(null이 아닌 경우 등) 결과값을 출력했었습니다.
하지만 둘 중 한쪽 테이블을 기준으로 LEFT 또는 RIGHT JOIN을 할 경우, 그 기준이 되는 테이블의 모든 레코드를 출력하게 됩니다.
LEFT JOIN과 RIGHT JOIN은 본질적으로 같지만, SQL 문장 작성 시 두 테이블의 표기 순서에 차이가 있습니다.
즉, 헛갈릴 경우 테이블 순서를 바꾸어 모두 LEFT JOIN으로 통일하는 등의 작업도 가능합니다.
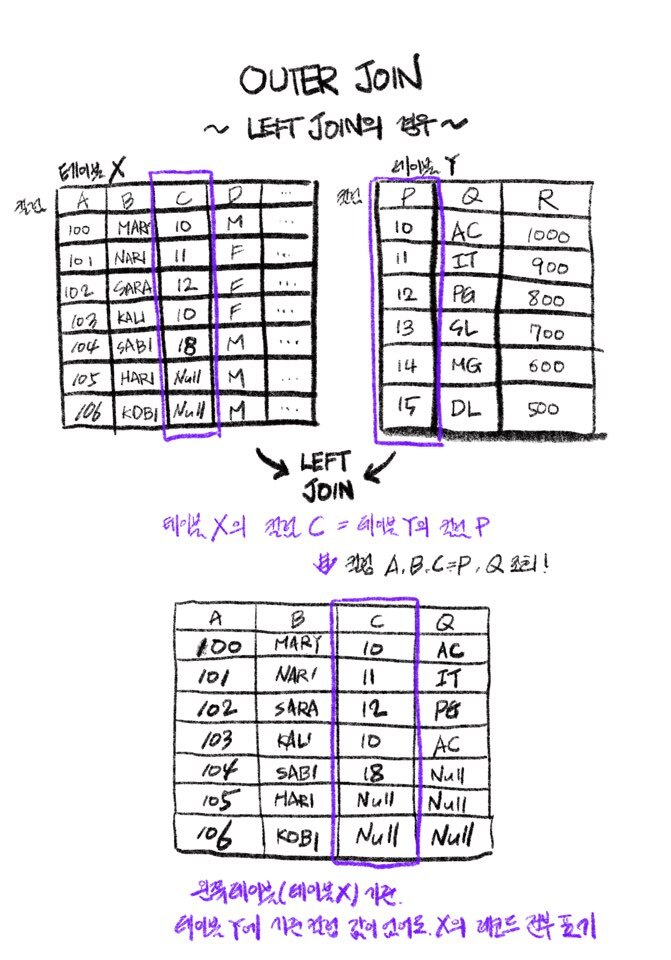
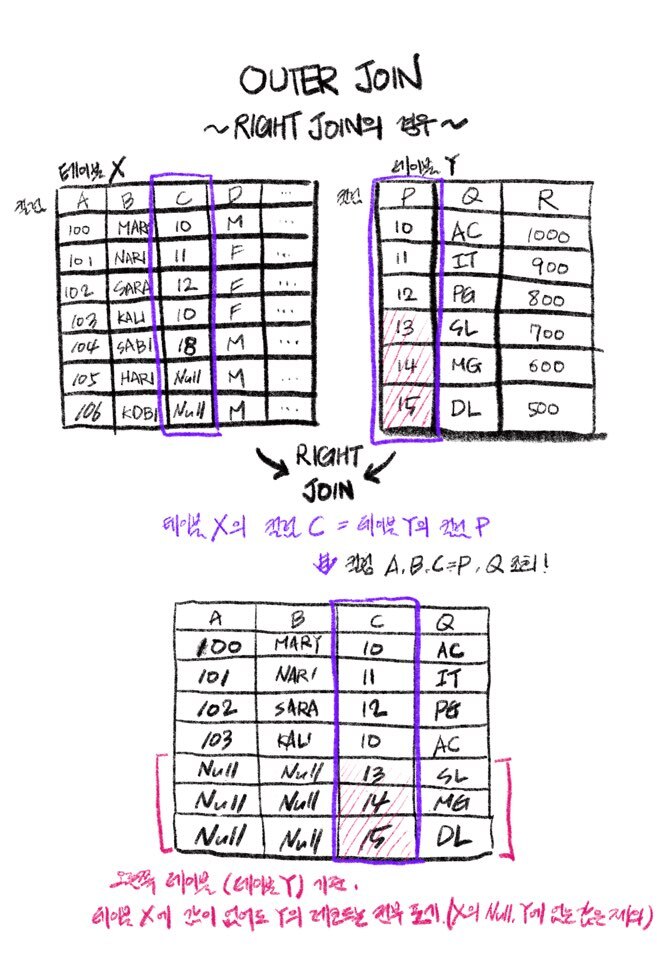
2) OUTER JOIN :
LEFT JOIN, RIGHT JOIN의 표현
오라클 SQL 디벨로퍼의 SQL 문장에서, FULL JOIN을 제외한 나머지 종류의 JOIN들은 2가지 문법으로 표현할 수 있습니다.
- Oracle 문법 : 오라클 프로그램에서 사용 가능한 JOIN 문법입니다.
'join' 명령어를 사용하지 않고, WHERE 조건절에서 JOIN 조건을 지정합니다.
- ANSI 표준 문법 : 다른 SQL 프로그램에서도 공통적으로 사용 가능한 표준 JOIN 문법입니다.
FROM 절에서 'join'명령어를 사용하며, WHERE 조건절과 JOIN절이 구분되는 특성을 갖습니다.
(* OUTER JOIN 중 FULL JOIN은 Oracle 문법이 없어, ANSI 문법만 사용할 수 있습니다)
LEFT JOIN, RIGHT JOIN의 두 문법상 차이점은 다음과 같습니다.
- Oracle 문법 : 데이터가 전부 포함되지 않는 쪽에 (+) 표시
- ANSI 문법 : 데이터가 전부 포함되어야 하는 쪽을 기준으로 'LEFT JOIN', 'RIGHT JOIN' 표시
(SQL 문장에서 LEFT OUTER JOIN, RIGHT OUTER JOIN은 LEFT JOIN, RIGHT JOIN과 같습니다.)
(1) LEFT JOIN : Oracle 문법 기본식
select x.컬럼이름A,
x.컬럼이름B,
y.컬럼이름P, ...
from 테이블이름X x, 테이블이름 Y y
where x.컬럼이름M = y.컬럼이름N(+);- FROM 절 : 테이블X와 테이블Y를 JOIN 하는 경우입니다. 테이블X와 테이블Y의 약칭을 각각 x와 y라고 합니다.
- WHERE 조건절 : 테이블X의 컬럼M과 테이블Y의 컬럼N이 같음을 명시합니다. JOIN 시 기준 컬럼이 됩니다.
이 때, 테이블X에 대하여 LEFT JOIN을 할 경우, 테이블X의 레코드가 모두 포함되어야 합니다.
- SELECT 다음 : 테이블 X의 A,B컬럼, 테이블Y의 P컬럼을 조회합니다.
(2) LEFT JOIN : ANSI 문법 기본식
select x.컬럼이름A,
x.컬럼이름B,
y.컬럼이름C, ...
from 테이블이름X x left join 테이블이름 Y y
on x.컬럼이름M = y.컬럼이름N;
- FROM 절 : 테이블X와 테이블Y를 JOIN 하는 경우입니다. 테이블X와 테이블Y의 약칭을 각각 x와 y라고 합니다.
- WHERE 조건절 : 테이블X의 컬럼M과 테이블Y의 컬럼N이 같음을 명시합니다. JOIN 시 기준 컬럼이 됩니다.
이 때, 테이블Y에 대하여 RIGHT JOIN을 할 경우, 테이블Y의 레코드가 모두 포함되어야 합니다.
- SELECT 다음 : 테이블 X의 A,B컬럼, 테이블Y의 P컬럼을 조회합니다.
(4) RIGHT JOIN : ANSI 문법 기본식
select x.컬럼이름A,
x.컬럼이름B,
y.컬럼이름C, ...
from 테이블이름X x right join 테이블이름 Y y
on x.컬럼이름M = y.컬럼이름N;
위 '(1)Oracle 문법'의 예시가 되는 기본식을 ANSI 문법으로 나타낸 것입니다. (1)과 (2)의 결과는 같습니다.
ANSI 문법에서는
- 'right join' 명령어를 사용하여 RIGHT JOIN하는 두 테이블과, 모든 레코드가 출력되어야 할 기준 테이블(테이블Y)을 설정합니다.
- 'on' 다음에는 기준이 되는 컬럼의 관계를 설정합니다.
* 이하 예제에서는 scott 연습계정의 emp, dept 테이블을 사용합니다.
2. 예제 : OUTER JOIN
- LEFT, RIGHT JOIN의 사용
* 참고 : emp 테이블과 dept 테이블의 전체 컬럼과 레코드를 조회한 결과는 아래와 같습니다.


1) LEFT JOIN을 사용하여 :
ⓐ emp 테이블과 dept 테이블의 컬럼 중
ⓑ 직원번호(empno), 직원성명(ename), 부서번호(deptno), 부서이름(dname) 컬럼을 출력하되,
ⓒ emp 테이블의 모든 레코드가 출력되게끔 하기
이 경우 emp 테이블을 기준으로 LEFT JOIN을 하면, emp 테이블의 모든 레코드가 출력되는 JOIN 결과가 나오게 될 것입니다.
(1) Oracle 문법
select e.empno,
e.ename,
d.deptno,
d.dname
from emp e, dept d
where e.deptno = d.deptno(+);
- JOIN할 테이블 : emp, dept
- 모든 레코드를 출력해야 하는 기준 테이블 : emp
- JOIN 종류 : emp 테이블에 대한 left join
- emp 테이블의 약칭 : e, dept 테이블의 약칭 : d
- JOIN 기준 컬럼 : emp테이블의 deptno = dept테이블의 deptno
- 조회할 컬럼 : ename, deptno, dname
위 SQL 문장을 실행(Ctrl+Enter)하면, 아래와 같은 결과가 출력됩니다.

JOIN 기준 컬럼인 deptno에 null이 있더라도, emp 테이블이 보유한 모든 레코드가 출력되었습니다.
또한 dept 테이블의 경우, emp테이블에 없는 40번 부서의 경우에 결과에 포함되지 못했습니다.
(2) ANSI 문법
select e.empno,
e.ename,
d.deptno,
d.dname
from emp e left join dept d
on e.deptno = d.deptno;ANSI 문법은 'left join'이라고 명시하여 두 테이블을 LEFT JOIN 합니다.
이 때, LEFT JOIN 시에는 기준이 되는(모든 레코드를 출력해야 하는) 테이블이 왼쪽(LEFT)에 위치합니다.

2) RIGHT JOIN을 사용하여 :
ⓐ emp 테이블과 dept 테이블의 컬럼 중
ⓑ 직원번호(empno), 직원성명(ename), 부서번호(deptno), 부서이름(dname) 컬럼을 출력하되,
ⓒ dept 테이블의 모든 레코드가 출력되게끔 하기
'1)'예제와 반대로 dept 테이블을 기준으로 RIGHT JOIN을 하면, dept 테이블의 모든 레코드가 출력되는 JOIN 결과가 나오게 될 것입니다. 또한, dept 테이블의 값이 없는 emp 테이블 레코드는 조회 결과에서 제외될 것입니다.
(1) Oracle 문법
select e.empno,
e.ename,
d.deptno,
d.dname
from emp e, dept d
where e.deptno(+) = d.deptno;- JOIN할 테이블 : emp, dept
- 모든 레코드를 출력해야 하는 기준 테이블 : emp
- JOIN 종류 : dept 테이블에 대한 right join
- emp 테이블의 약칭 : e, dept 테이블의 약칭 : d
- JOIN 기준 컬럼 : emp테이블의 deptno = dept테이블의 deptno
- 조회할 컬럼 : ename, deptno, dname
위 SQL 문장을 실행(Ctrl+Enter)하면, 아래와 같은 결과가 출력됩니다.

JOIN 기준 컬럼인 dept 테이블이 보유한 모든 레코드가 출력되었습니다.
마지막 9번 행의 경우, emp 테이블에 40번 부서에 속한 직원이 없음에도((null), (null)) 40번 부서 레코드가 조회되었습니다.
그러나, 기준컬럼(deptno)이 null인 emp 테이블의 레코드들은 조회 결과에서 제외되었습니다.(ADAMS, JAMES, FORD, MILLER)
(2) ANSI 문법
select e.empno,
e.ename,
d.deptno,
d.dname
from emp e right join dept d
on e.deptno = d.deptno;
ANSI 문법은 ' right join '이라고 명시하여 두 테이블을 RIGHT JOIN 합니다.
이 때, RIGHT JOIN 시에는 기준이 되는(모든 레코드를 출력해야 하는) 테이블이 오른쪽(RIGHT)에 위치합니다.
select e.empno,
e.ename,
d.deptno,
d.dname
from dept d left join emp e
on e.deptno=d.deptno;(* 참고 : FROM 절에서 두 테이블(emp, dept)의 서술 순서를 바꾸어 LEFT JOIN 문장으로 바꾸어도 결과는 같습니다.)
오라클 SQL 디벨로퍼의 실행 결과는 아래와 같습니다.
OUTER JOIN - FULL JOIN : 한쪽에 null이 있더라도, 양쪽 테이블의 전체 레코드를 모두 JOIN 결과에 포함시켜 출력하는 방법

1. OUTER JOIN - FULL JOIN의 개념과 표현
1) FULL JOIN의 개념
FULL JOIN은 두 테이블을 연결하여 하나의 조회 결과를 보여주되,
- 기준 컬럼의 값을 공통적으로 갖고 있는 레코드들(INNER JOIN 결과)
- 양쪽 테이블 각각에 대하여 한쪽 테이블의 값은 있고, 다른 테이블에는 없는 경우의 레코드들(RIGHT, LEFT JOIN 결과)
을 모두 모아서 보여 주는 JOIN 방법입니다.
즉, FULL JOIN은 LEFT JOIN, RIGHT JOIN의 결과를 모두 합하여 보여줍니다.
동일한 조건 하에서 LEFT JOIN 조회결과와 RIGHT JOIN 조회결과의 합집합이라고 볼 수 있습니다.

아래는 Oracle SQL Developer에 실제 작성된 문장의 출력 결과입니다. 동일한 조건 하에서 FULL JOIN, LEFT JOIN< RIGHT JOIN, INNER JOIN인 경우로 나누어 비교하였습니다.

- INNER JOIN : 기준 컬럼과 관련한 null 데이터가 없음. LEFT JOIN 결과와 RIGHT JOIN 결과의 교집합
- FULL JOIN : LEFT JOIN 결과와 RIGHT JOIN 결과의 합집합
즉, 기준 컬럼에 대하여 한쪽이 null이어도 모든 레코드를 조회하는 것이 FULL JOIN입니다.
2) FULL JOIN의 표현
다른 OUTER JOIN과 달리, FULL JOIN은 ANSI 문법으로만 작성할 수 있습니다.
(* 2020년 12월 30일 기준, Oracle 문법에는 FULL JOIN이 없습니다.)
select x.컬럼이름A,
x.컬럼이름B,
y.컬럼이름C, ...
from 테이블이름X x full join 테이블이름 Y y
on x.컬럼이름M = y.컬럼이름N;- FROM 절 : 테이블X와 테이블Y를 JOIN 하는 경우입니다. 테이블X와 테이블Y의 약칭을 각각 x와 y라고 합니다.
'full join' 이라고 JOIN 종류를 명시하여 줍니다.
SELECT 다음 : 테이블 X의 A,B컬럼, 테이블Y의 C컬럼을 조회합니다.
* 이하의 예제에서는 scott 연습계정의 emp테이블, dept 테이블을 사용합니다.
2. 예제 : FULL JOIN의 사용
1) 예제 : emp 테이블, dept 테이블에 대하여
ⓐ 두 테이블을 JOIN하여 직원성명(ename), 부서번호(deptno), 부서이름(dname) 컬럼을 출력하되
ⓑ 기준 컬럼(deptno)에 대하여 한쪽 테이블이 null이더라도 모두 결과데이터로 조회하기
FULL JOIN을 사용해야 합니다. FULL JOIN은 ANSI 문법으로만 작성이 가능합니다.
select e.ename as 직원성명,
e.deptno as 부서번호,
d.dname as 부서이름
from emp e full join dept d
on e.deptno=d.deptno;
위 문장을 실행(Ctrl+Enter)하면, 오라클 SQL 디벨로퍼는 아래와 같은 결과를 출력합니다.
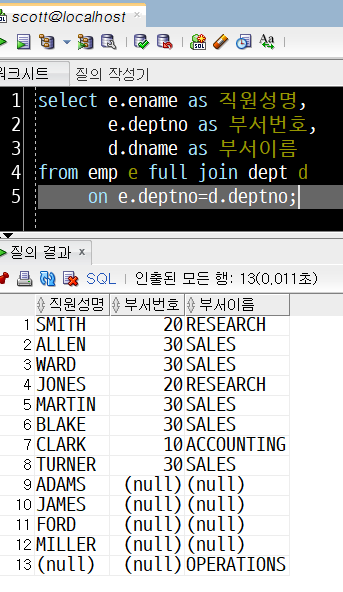
- emp 테이블과 dept 테이블 모두 공통의 deptno 값을 갖고 있는 경우 (행 1~8)
- emp 테이블에는 있는 레코드이지만, dept 테이블에 값이 없는 레코드(행 9~12)
- emp테이블에 없는 레코드이지만, dept테이블에는 있는 레코드(행 13)
위 3가지 경우가 모두 포함된 FULL JOIN 결과를 얻었습니다.
* 참고 : 아래는 같은 조건의 문제에 대해 FULL JOIN, LEFT JOIN, RIGHT JOIN, INNER JOIN을 했을 때의 결과를 비교한 것입니다.

'Structured Query Language > Oracle SQL' 카테고리의 다른 글
| Oracle SQL 기본_10 (1) | 2023.04.26 |
|---|---|
| Oracle SQL 기본_09 (1) | 2023.04.25 |
| Oracle SQL 기본_07 (0) | 2023.04.21 |
| Oracle SQL 기본_06 (1) | 2023.04.20 |
| Oracle SQL 기본_05 (0) | 2023.04.20 |



