Seaborn
엄청나게 화려한 시각화 기법들을 제공하며, 기본적으로 이쁘다.
pandas DataFrame과 매우 호환이 잘된다.
histplot, barplot, jointplot, lineplot, ...
e.g. sns.xxxplot(data=df) <--- 기본세팅!
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 위 4개는 데이터 필수 4종 라이브러리
# 외워주면 사용하기 편하다.
# Seaborn에서 사용할 수 있는 dataset의 목록은 get_dataset_names로 한 번에 알 수 있다.
# Seaborn 데이터셋 목록
sns.get_dataset_names()
['anagrams', 'anscombe', 'attention', 'brain_networks', 'car_crashes', 'diamonds', 'dots', 'exercise', 'flights', 'fmri', 'gammas', 'geyser', 'iris', 'mpg', 'penguins', 'planets', 'tips', 'titanic']
# 데이터셋 불러오기
sns.load_dataset('dataset')
# 라이브러리와 데이터를 불러오고, 시각화를 위한 세팅을 하자
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset("penguins")
data
# Nan이 많다, 삭제하고 싶으면 dropna( ) 를 사용하자.
data = data.dropna() # nan값 삭제
data
Histplot
- 가장 기본적으로 사용되는 히스토그램을 출력하는 plot.
- 전체 데이터를 특정 구간별 정보를 확인할 때 사용
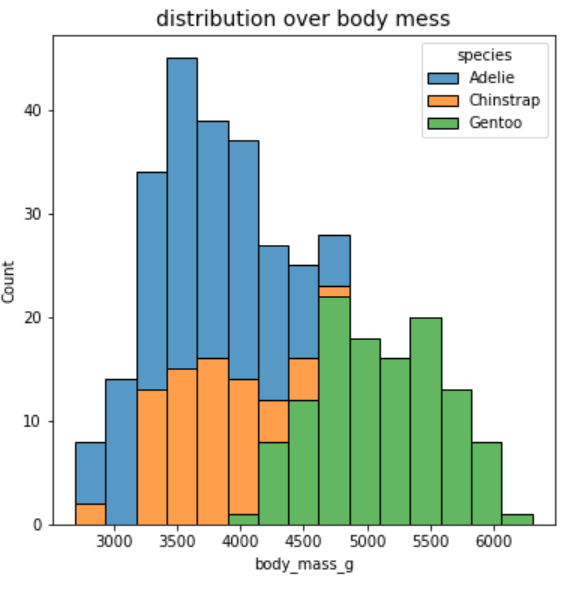
# penguin 데이터에 histplot을 출력
plt.figure(figsize=(6,6))
plt.title("distribution over body mess", fontsize=14)
sns.histplot(data= data, x="body_mass_g", bins = 15, hue="species", multiple="stack" )
plt.show()
# hue : 내가 선택한 샐깔로 정보차이를 제공
# bins : 구간의 간격
# multiple = "stack" 은 겹치는거 나뉘서 보여줌
# title( ) : 제목 넣고 싶을때 사용
Displot
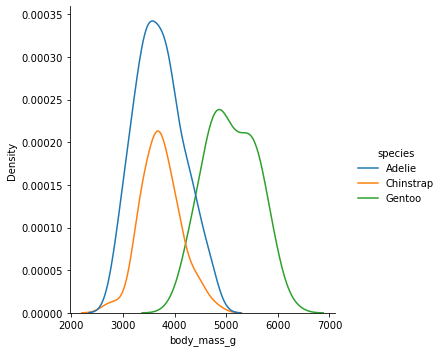
- distribution들을 여러 subplot들로 나눠서 출력해주는 plot.
- displot에 kind를 변경하는 것으로, histplot, kdeplot(밀도함수), ecdfplot 모두 출력이 가능합니다.
- e.g. displot(kind="hist")
# penguin 데이터에 displot을 출력
sns.displot(data = data, kind="kde", x = 'body_mass_g', hue="species")
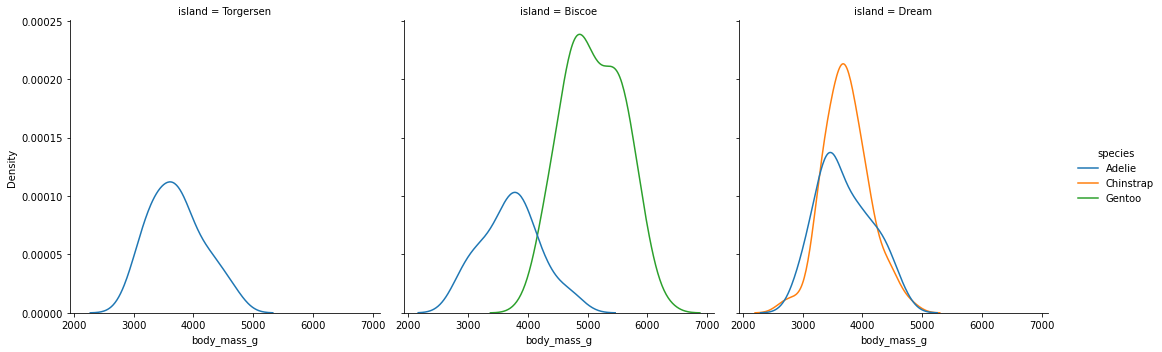
sns.displot(data = data, kind="kde", x = 'body_mass_g', hue="species",col="island")
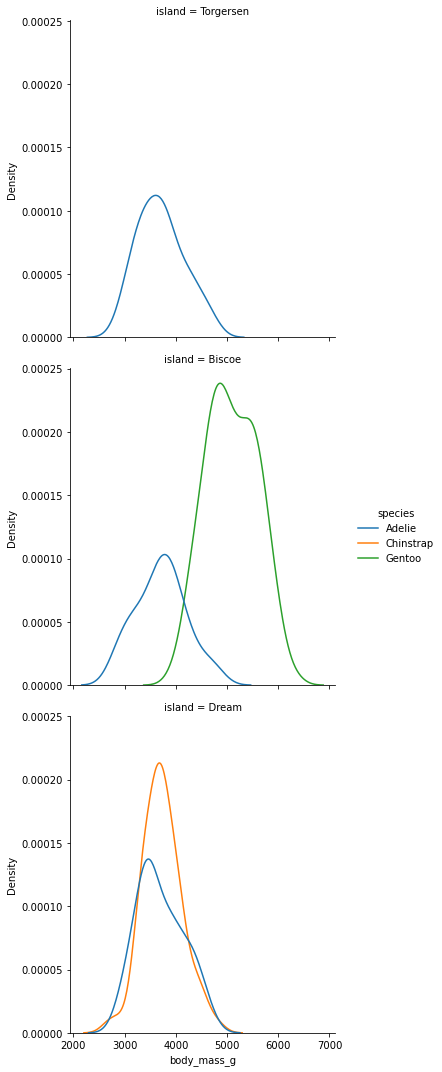
sns.displot(data = data, kind="kde", x = 'body_mass_g', hue="species",row="island")
Barplot
- 어떤 데이터에 대한 값의 크기를 막대로 보여주는 plot. (a.k.a. 막대그래프)
- 가로 / 세로 두 가지로 모두 출력 가능
- 히스토그램과는 다르다!
# penguin 데이터에 barplot을 출력
sns.barplot(data =data, x= "species", y="body_mass_g") # x축의 종류
plt.show()
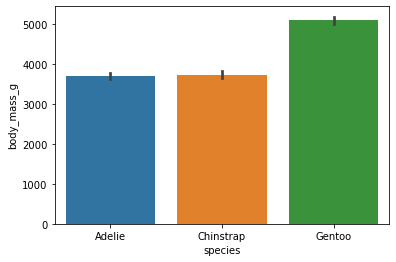
sns.barplot(data =data, y= "species", x="body_mass_g",hue="sex") # y축 종류
plt.show() # 그래프의 위의 검은색 이 에러의 정도

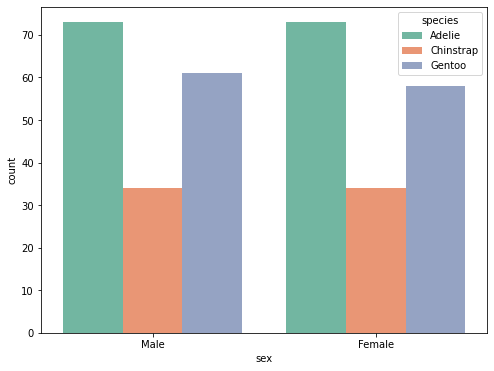
Countplot
- 범주형 속성을 가지는 데이터들의 histogram을 보여주는 plot
- 종류별 count를 보여주는 방법
# penguin 데이터에 countplot을 출력
plt.figure(figsize=(8,6))
sns.set_palette("Set2") # 색상 테마 고를수 있음
sns.countplot(data=data, x="sex", hue= "species")# y는 보통 고정,
plt.show()
Boxplot
- 데이터의 각 종류별로 사분위 수(quantile)를 표시하는 plot.
- 특정 데이터의 전체적인 분포를 확인하기 좋은 시각화 기법.
- box와 전체 range의 그림을 통해 outlier를 찾기 쉬움. (IQR : Inter-Quantile Range)
# penguin 데이터에 boxplot을 출력
plt.figure(figsize=(8,6))
sns.boxplot(data=data, x= "species",y= "bill_depth_mm" , hue = "sex")
plt.show()
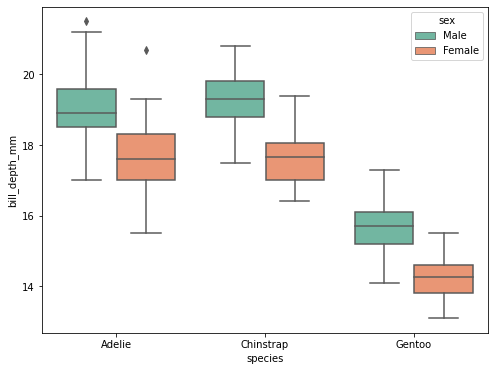
# What is boxplot?
# 전체의 데이터의 분산을 표시하는 방법
# 네모는 전체의 데이터의 50%, 4분위수의 25%~75%, 박스 안의 선은 중앙값.
# 박스크기가 작다 4분위의 범위가 작게 퍼져있다.
Violinplot
- 데이터에 대한 분포 자체를 보여주는 plot.
- boxplot과 비슷하지만, 전체 분포에 대한 그림을 보여준다는 점에서 boxplot과 다르다.
- 보통 boxplot과 함께 표시하면, 평균 근처에 데이터가 얼마나 있는지(boxplot) 전체적으로 어떻게 퍼져있는지(violinplot) 모두 확인이 가능하다.
# penguin 데이터에 violinplot을 출력
plt.figure(figsize=(8,6))
sns.violinplot(data=data, x="species",y="bill_depth_mm" , hue= "sex")
plt.show()
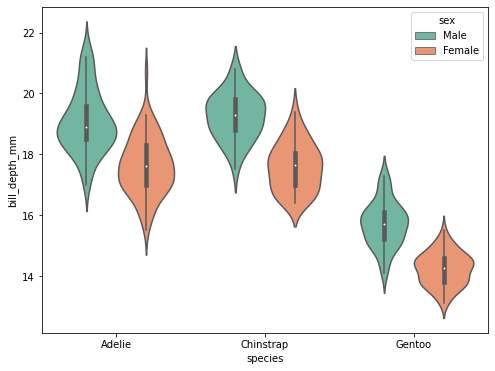
# boxplot과 친구
# 점은 중앙값
Lineplot
- 특정 데이터를 x, y로 표시하여 관계를 확인할 수 있는 plot. (선 그래프)
- 수치형 지표들 간의 경향을 파악할 때 많이 사용한다.
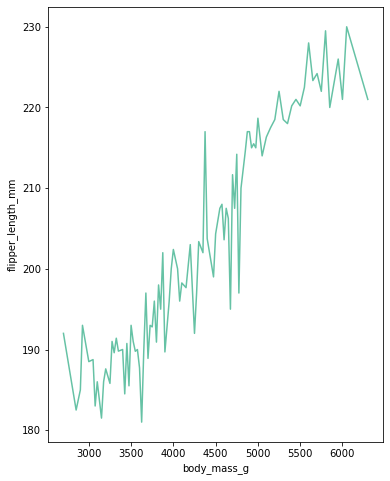
# penguin 데이터에 lineplot을 출력
plt.figure(figsize=(6,8))
sns.lineplot(data=data, x= "body_mass_g", y="flipper_length_mm",ci=None)
# 백그라운드는 해당 수치가 에러나올수 있는 범위, ci라고 부르고, ci = None으로 없앰
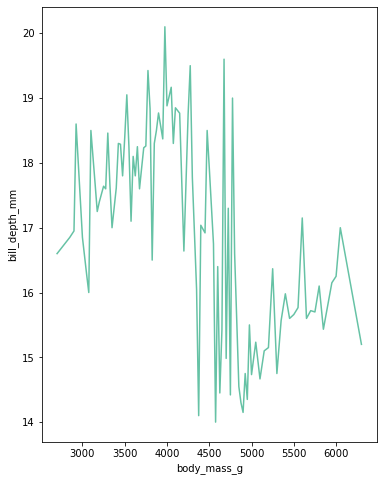
plt.figure(figsize=(6,8))
sns.lineplot(data=data, x= "body_mass_g", y="bill_depth_mm",ci=None)
# 백그라운드는 해당 수치가 에러나올수 있는 범위, ci라고 부르고, ci=None으로 없앰
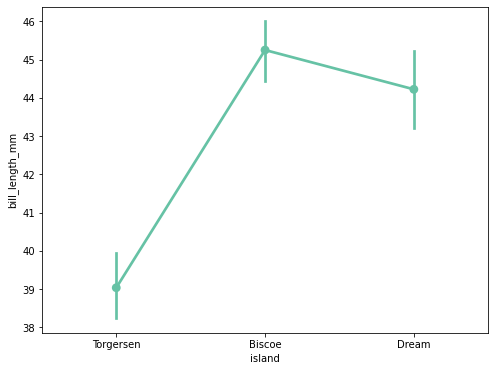
Pointplot
- 특정 수치 데이터를 error bar와 함께 출력해주는 plot.
- 수치 데이터를 다양한 각도에서 한 번에 바라보고 싶을 때 사용한다
- 데이터와 error bar를 한 번에 찍어주기 때문에, 살펴보고 싶은 특정 지표들만 사용하는 것이 좋다.
# penguin 데이터에 pointplot을 출력
plt.figure(figsize=(8,6))
sns.pointplot(data=data, x="island", y="bill_length_mm")
plt.show()# 에러를 잘 보여줌, so Lineplot에서 에러를 잘 보고 싶으면 pointplot을 사용
Scatterplot
- lineplot과 비슷하게 x, y에 대한 전체적인 분포를 확인하는 plot.
- lineplot은 경향성에 초점을 둔다면, scatterplot은 데이터 그 자체가 퍼져있는 모양에 중점을 둔다.
# penguin 데이터에 scatterplot을 출력
plt.figure(figsize=(10,6))
sns.scatterplot(data=data, x="flipper_length_mm", y="body_mass_g",hue="sex")
plt.show()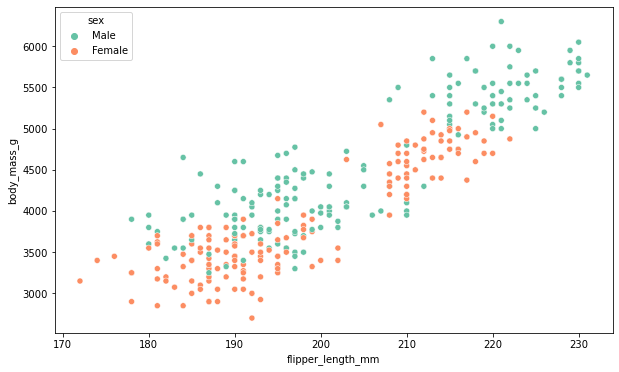
Pairplot
- 주어진 데이터의 각 feature들 사이의 관계를 표시하는 Plot.
- scatterplot, FacetGrid, kdeplot을 이용하여 feature간의 관계를 잘 보여준다.
- 각 feature에 대해 계산된 모든 결과를 보여주기 때문에, feature가 많은 경우 사용하기 적합하지 않다.
# penguin 데이터에 pairplot을 출력합니다.
plt.figure(figsize=(10,10))
sns.pairplot(data=data,hue="species")
plt.show()
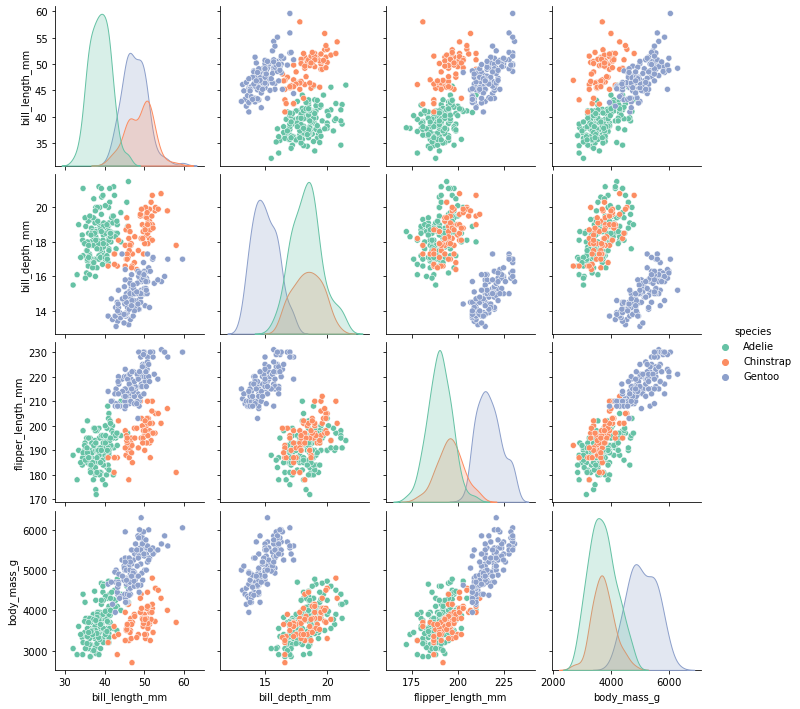
# 각 뉴매릭 4가지의 피쳐 바이 피쳐로 나온다! 4X4는 16개
plt.figure(figsize=(10,10))
sns.pairplot(data=data,hue="sex")
plt.show()
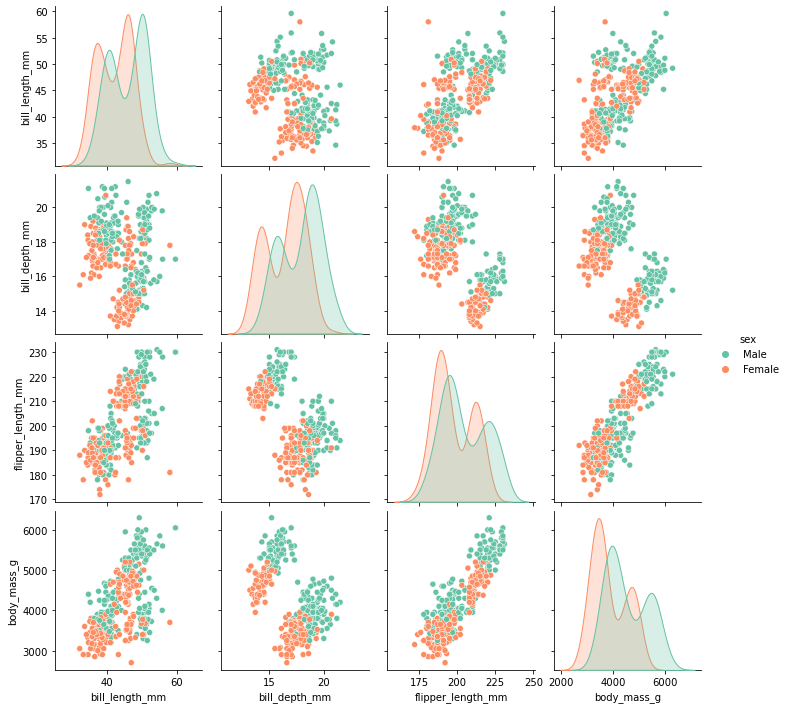
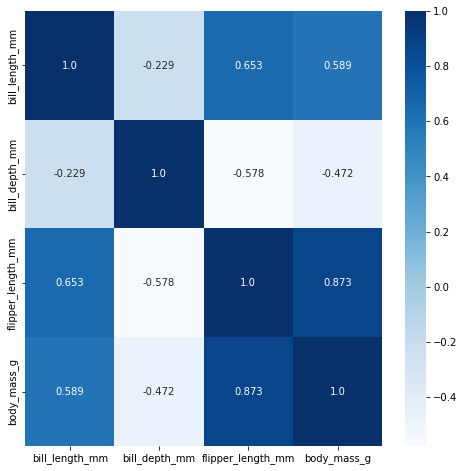
Heatmap
- 정사각형 그림에 데이터에 대한 정도 차이를 색 차이로 보여주는 plot.
- 말 그대로 heatmap이기 때문에, 열화상카메라로 사물을 찍은 것처럼 정보의 차이를 보여준다.
- pairplot과 비슷하게 feature간 관계를 시각화할 때 많이 사용한다.
상관관계란?
- 어떤 X값의 변화에 따라 Y값의 선형적으로 변화하는지를 측정한 지표.
- [-1, 1]
- e.g. 아이스크림 판매량 증가 <----> 상어에 물린 사람 수
# penguin 데이터에 heatmap을 출력
plt.figure(figsize=(8,8))
sns.heatmap(data=corr, square=True,cmap="Blues" )
plt.show()
# sns.set_palette("Set2") 적용안되서, cmap을 사용한다.
# data= corr 상관계수를 사용하여야함

plt.figure(figsize=(8,8))
sns.heatmap(data=corr,cmap="Blues",annot=True,fmt=".3" )
plt.show()
# annot = True , fmt = ".3" 숫자표시 & 소수점 자리수
'Python > Data Analysis Library' 카테고리의 다른 글
| 02. Package pandas finance (0) | 2022.07.27 |
|---|---|
| 01. Package_Numpy (0) | 2022.07.25 |
| Part03 Chapter.02 데이터 분석 라이브러리 08 pyplot 기초 (실습) (0) | 2022.07.24 |
| Part03 Chapter.02 데이터 분석 라이브러리 07. Seaborn을 사용하는 이유 (0) | 2022.07.18 |
| Part03 Chapter.02 데이터 분석 라이브러리 06. Pandas method (실습) (0) | 2022.07.18 |



