Pandas
- 데이터 과학자를 위해 테이블형태로 데이터를 다룰 수 있게 해주는 패키지(python용 엑셀)
- 기존 데이터처리 라이브러리인 numpy 대신 주로 사용
- 일반인이 데이터분석을 접하기 쉽게 만들어준 결정적인 라이브러리
- pandas만으로도 충분히 데이터 분석이 가능할 정도로 고수준의 함수들을 내장
- 앞으로 진행하는 데이터분석 과정에서 주로 사용하게 될 데이터구조
1. pandas 설치 및 import
콘솔창에서 실행 시
pip install pandas
conda install pandas
주피터 노트북으로 실행 시
!pip install pandas
아나콘다 환경으로 python 환경설정 시 기본적으로 설치가 되어있음
# pandas 설치
!pip install pandas
# pandas import
# pd라는 닉네임은 많은 파이썬 유저들이 사용하고 있는 닉네임,
# 분석을 위한 필수는 아니지만 되도록이면 위와 같이 사용을 해줍시다.
# 둘이 세트이다!
import numpy as np
import pandas as pd
pd.options.display.max_columns = 200
# 불러들이는 데이터에 맞춰 모든 컬럼을 확인 가능하도록 옵션값을 주었습니다.
# head() 사용하면 컬럼이 디폴드로 50개 로 나옴, 전부 확인하기 힘드니 200으로 설정
pd.options.display.max_info_columns =200
# info()에서 컬럼 확인하기 위해서 사용
2. DataFrame
- 엑셀에 익숙한 사용자를 위해 제작 된 테이블형태의 데이터 구조
- 다양한 형태의 데이터를 받아 사용할 수 있으며 다양한 통계, 시각화 함수를 제공한다.
실제 데이터를 불러들이고 값을 확인 해 보며 기본적인 pandas 사용법을 익혀보도록 하겠습니다.
2.1 데이터 불러오기
pandas는 다양한 데이터 파일 형태를 지원하며 주로 csv, xlsx, sql, json을 사용합니다.
read_csv()
read_excel()
read_sql()
read_json()
json_normalize()
# 지금현재 주피터 노트북이 실행되고 있는 경로
pwd
>>> 'C:\\Users\\JIN SEONG EUN\\Desktop\\빅데이터 분석가 과정\\SeSAC'
# DataFrame 의 약자로서 형식적으로 df 변수명을 사용한다.
# pandas패키지의 read_csv( ) 함수를 사용하여 loan1.csv 파일을 불러들여
데이터프레임을 만들고 df 이름의 변수로 저장 해보자
# 목차는 데이터 분석 하는 루틴대로 제작하였다. 참조하여라
# csv 콤마로 데이터를 구분, 빠르다.
# 하지만 데이터가 커질수록 용량이 기하급수적으로 커진다.
df = pd.read_csv("파일 경로")
# (현재경로를 . 으로 표현가능) (./data/loan1.csv)
"C:/Users/JIN SEONG EUN/Desktop/빅데이터 분석가 과정/SeSAC/data/loan1.csv"
df

# 이번엔 엑셀 파일을 열어보자
df1 = pd.read_excel("C:/Users/JIN SEONG EUN/Desktop/빅데이터 분석가 과정/SeSAC/data/loan1.xlsx")
df1

# 엑셀파일 읽는 모듈, 설치시 하나하나 설치해야함
# 만약 모듈을 찾을 수 없는 오류가 발생한다면 추가 모듈 설치
# 필요 모듈 import
!pip install xlrd,
!pip install openpyxl,
!pip install pyxlsb
# 엑셀파일에 시트에 따라 데이터 구분이 지어진 경우 시트별로 데이터프레임 제작 가능
# 다른 엑셀파일형식을 가져올 때 engine파라메터 추가해주면 된다.
df1 = pd.read_excel('./data/loan1.xlsb',
sheet_name='구매영수증상세+상품마스터포함',
engine='pyxlsb',
encoding='utf-8') # 윈도우의 경우 cp949 웬만한 한글데이터
# 참고사항
# 참고! 실습은 하지 않지만, 쿼리를 사용하여 데이터베이스로부터 데이터프레임을 만드는 것도 가능하다.
# 데이터베이스로 부터 자료 읽기
# sql 사용하고 바로 불러올떄 사용
# 필요한 모듈 추가 설치 - 각 데이터베이스 별로 다릅니다.
# !pip install pymysql
# sql 모듈 로드하기
# import pymysql
# mysql, mariadb, sqlite, postgresql, ms-sql, oracle, mongodb
# 접속하기
# 접속방법 또한 DB 종류에 따라 다릅니다.
# con = pymysql.connect(host='db서버주소', port=3306, user='id', passwd='pwd', db='dbname')
# query 만들기
# query = 'select * from samples'
# 자료 불러오기
# data = pd.read_sql(query, con=con)
2.2 데이터 저장하기
불러들인 혹은 작업을 마친 데이터프레임을 다양한 파일형태로 저장이 가능합니다
to_csv()
to_excel()
to_sql()
df.to_csv("./data/save_test.csv", index= False)
# index= False 파라메터는 기존 데이터프레임의 인덱스를 무시하고 저장
# index= False 는 기본적으로 사용해야함 안그럼 인덱스를 데이터로 저장함
df.to_excel("./data/save_test.xlsx", index= False)
# 원본 데이터를 변경해서 쓰는 경우가 아니라면, 이렇게 저장을 자주 해주는게 좋다
2.3 사용 데이터 간략 설명
- 미국 핀테크 회사인 lending club의 대출 데이터베이스
- 클라우드펀딩과 대출을 결합한 핀테크의 시초라고 부를 수 있는 회사
- 방대한 양의 대출정보를 공개하면서 금융정보분석에도 기여한 공이 큰 데이터
- 2007 ~ 2015 년 대출정보 및 개인정보를 담고 있음
- 226만 건, 145 항목 정보를 담고있음
- 실습데이터는 이 중 4만건을 추출한 데이터를 사용한다.
데이터출처: https://www.kaggle.com/wordsforthewise/lending-club
2.4 데이터 살펴보기
# 데이터를 불러들인 후 가장 처음 하는 작업
# 데이터의 구조, 형태 파악하기
# 데이터의 첫 5개 데이터 하나(샘플, 인스턴스) 확인하기
# 10개를 확인하려면?
# 데이터 샘플, 인스턴스, 레코드 다 같은말임
df.head()

# 데이터의 마지막 5개 샘플 확인하기
# 데이터가 잘 가져왔는지 확인 할 때 보통 쓴다.
df.tail()
# 데이터의 갯수를 살펴보자
df.shape
>>> (20000, 145)
# 2만개, 145콜럼
# 데이터의 전반적인 정보를 확인해보자
df.info()
# dtype 정보에서는 각 컬럼별 데이터 타입을 확인 할 수 있습니다.
# object == str 이라고 생각하셔도 무방합니다.
# verbose, null_counts<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20000 entries, 0 to 19999
Data columns (total 145 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 0 non-null float64
1 member_id 0 non-null float64
2 loan_amnt 20000 non-null int64
3 funded_amnt 20000 non-null int64
4 funded_amnt_inv 20000 non-null float64
5 term 20000 non-null object
6 int_rate 20000 non-null float64
7 installment 20000 non-null float64
8 grade 20000 non-null object
9 sub_grade 20000 non-null object
10 emp_title 18269 non-null object
11 emp_length 18296 non-null object
12 home_ownership 20000 non-null object
13 annual_inc 20000 non-null float64
14 verification_status 20000 non-null object
15 issue_d 20000 non-null object
16 loan_status 20000 non-null object
17 pymnt_plan 20000 non-null object
18 url 0 non-null float64
19 desc 0 non-null float64
20 purpose 20000 non-null object
21 title 20000 non-null object
22 zip_code 20000 non-null object
23 addr_state 20000 non-null object
24 dti 19961 non-null float64
25 delinq_2yrs 20000 non-null float64
26 earliest_cr_line 20000 non-null object
27 inq_last_6mths 20000 non-null float64
28 mths_since_last_delinq 8992 non-null float64
29 mths_since_last_record 2914 non-null float64
30 open_acc 20000 non-null float64
31 pub_rec 20000 non-null float64
32 revol_bal 20000 non-null int64
33 revol_util 19963 non-null float64
34 total_acc 20000 non-null float64
35 initial_list_status 20000 non-null object
36 out_prncp 20000 non-null float64
37 out_prncp_inv 20000 non-null float64
38 total_pymnt 20000 non-null float64
39 total_pymnt_inv 20000 non-null float64
40 total_rec_prncp 20000 non-null float64
41 total_rec_int 20000 non-null float64
42 total_rec_late_fee 20000 non-null float64
43 recoveries 20000 non-null float64
44 collection_recovery_fee 20000 non-null float64
45 last_pymnt_d 19970 non-null object
46 last_pymnt_amnt 20000 non-null float64
47 next_pymnt_d 15056 non-null object
48 last_credit_pull_d 20000 non-null object
49 collections_12_mths_ex_med 20000 non-null float64
50 mths_since_last_major_derog 4862 non-null float64
51 policy_code 20000 non-null int64
52 application_type 20000 non-null object
53 annual_inc_joint 2792 non-null float64
54 dti_joint 2792 non-null float64
55 verification_status_joint 2792 non-null object
56 acc_now_delinq 20000 non-null float64
57 tot_coll_amt 20000 non-null float64
58 tot_cur_bal 20000 non-null float64
59 open_acc_6m 20000 non-null float64
60 open_act_il 20000 non-null float64
61 open_il_12m 20000 non-null float64
62 open_il_24m 20000 non-null float64
63 mths_since_rcnt_il 19242 non-null float64
64 total_bal_il 20000 non-null float64
65 il_util 16740 non-null float64
66 open_rv_12m 20000 non-null float64
67 open_rv_24m 20000 non-null float64
68 max_bal_bc 20000 non-null float64
69 all_util 19994 non-null float64
70 total_rev_hi_lim 20000 non-null float64
71 inq_fi 20000 non-null float64
72 total_cu_tl 20000 non-null float64
73 inq_last_12m 20000 non-null float64
74 acc_open_past_24mths 20000 non-null float64
75 avg_cur_bal 19997 non-null float64
76 bc_open_to_buy 19653 non-null float64
77 bc_util 19646 non-null float64
78 chargeoff_within_12_mths 20000 non-null float64
79 delinq_amnt 20000 non-null float64
80 mo_sin_old_il_acct 19242 non-null float64
81 mo_sin_old_rev_tl_op 20000 non-null float64
82 mo_sin_rcnt_rev_tl_op 20000 non-null float64
83 mo_sin_rcnt_tl 20000 non-null float64
84 mort_acc 20000 non-null float64
85 mths_since_recent_bc 19672 non-null float64
86 mths_since_recent_bc_dlq 4076 non-null float64
87 mths_since_recent_inq 17495 non-null float64
88 mths_since_recent_revol_delinq 5889 non-null float64
89 num_accts_ever_120_pd 20000 non-null float64
90 num_actv_bc_tl 20000 non-null float64
91 num_actv_rev_tl 20000 non-null float64
92 num_bc_sats 20000 non-null float64
93 num_bc_tl 20000 non-null float64
94 num_il_tl 20000 non-null float64
95 num_op_rev_tl 20000 non-null float64
96 num_rev_accts 20000 non-null float64
97 num_rev_tl_bal_gt_0 20000 non-null float64
98 num_sats 20000 non-null float64
99 num_tl_120dpd_2m 18819 non-null float64
100 num_tl_30dpd 20000 non-null float64
101 num_tl_90g_dpd_24m 20000 non-null float64
102 num_tl_op_past_12m 20000 non-null float64
103 pct_tl_nvr_dlq 20000 non-null float64
104 percent_bc_gt_75 19651 non-null float64
105 pub_rec_bankruptcies 20000 non-null float64
106 tax_liens 20000 non-null float64
107 tot_hi_cred_lim 20000 non-null float64
108 total_bal_ex_mort 20000 non-null float64
109 total_bc_limit 20000 non-null float64
110 total_il_high_credit_limit 20000 non-null float64
111 revol_bal_joint 2792 non-null float64
112 sec_app_earliest_cr_line 2792 non-null object
113 sec_app_inq_last_6mths 2792 non-null float64
114 sec_app_mort_acc 2792 non-null float64
115 sec_app_open_acc 2792 non-null float64
116 sec_app_revol_util 2745 non-null float64
117 sec_app_open_act_il 2792 non-null float64
118 sec_app_num_rev_accts 2792 non-null float64
119 sec_app_chargeoff_within_12_mths 2792 non-null float64
120 sec_app_collections_12_mths_ex_med 2792 non-null float64
121 sec_app_mths_since_last_major_derog 998 non-null float64
122 hardship_flag 20000 non-null object
123 hardship_type 64 non-null object
124 hardship_reason 64 non-null object
125 hardship_status 64 non-null object
126 deferral_term 64 non-null float64
127 hardship_amount 64 non-null float64
128 hardship_start_date 64 non-null object
129 hardship_end_date 64 non-null object
130 payment_plan_start_date 64 non-null object
131 hardship_length 64 non-null float64
132 hardship_dpd 64 non-null float64
133 hardship_loan_status 64 non-null object
134 orig_projected_additional_accrued_interest 50 non-null float64
135 hardship_payoff_balance_amount 64 non-null float64
136 hardship_last_payment_amount 64 non-null float64
137 disbursement_method 20000 non-null object
138 debt_settlement_flag 20000 non-null object
139 debt_settlement_flag_date 61 non-null object
140 settlement_status 61 non-null object
141 settlement_date 61 non-null object
142 settlement_amount 61 non-null float64
143 settlement_percentage 61 non-null float64
144 settlement_term 61 non-null float64
dtypes: float64(106), int64(4), object(35)
memory usage: 22.1+ MB
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20000 entries, 0 to 19999
Data columns (total 145 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 0 non-null float64
1 member_id 0 non-null float64
2 loan_amnt 20000 non-null int64
3 funded_amnt 20000 non-null int64
4 funded_amnt_inv 20000 non-null float64
5 term 20000 non-null object
6 int_rate 20000 non-null float64
7 installment 20000 non-null float64
8 grade 20000 non-null object
9 sub_grade 20000 non-null object
10 emp_title 18269 non-null object
11 emp_length 18296 non-null object
12 home_ownership 20000 non-null object
13 annual_inc 20000 non-null float64
14 verification_status 20000 non-null object
15 issue_d 20000 non-null object
16 loan_status 20000 non-null object
17 pymnt_plan 20000 non-null object
18 url 0 non-null float64
19 desc 0 non-null float64
20 purpose 20000 non-null object
21 title 20000 non-null object
22 zip_code 20000 non-null object
23 addr_state 20000 non-null object
24 dti 19961 non-null float64
25 delinq_2yrs 20000 non-null float64
26 earliest_cr_line 20000 non-null object
27 inq_last_6mths 20000 non-null float64
28 mths_since_last_delinq 8992 non-null float64
29 mths_since_last_record 2914 non-null float64
30 open_acc 20000 non-null float64
31 pub_rec 20000 non-null float64
32 revol_bal 20000 non-null int64
33 revol_util 19963 non-null float64
34 total_acc 20000 non-null float64
35 initial_list_status 20000 non-null object
36 out_prncp 20000 non-null float64
37 out_prncp_inv 20000 non-null float64
38 total_pymnt 20000 non-null float64
39 total_pymnt_inv 20000 non-null float64
40 total_rec_prncp 20000 non-null float64
41 total_rec_int 20000 non-null float64
42 total_rec_late_fee 20000 non-null float64
43 recoveries 20000 non-null float64
44 collection_recovery_fee 20000 non-null float64
45 last_pymnt_d 19970 non-null object
46 last_pymnt_amnt 20000 non-null float64
47 next_pymnt_d 15056 non-null object
48 last_credit_pull_d 20000 non-null object
49 collections_12_mths_ex_med 20000 non-null float64
50 mths_since_last_major_derog 4862 non-null float64
51 policy_code 20000 non-null int64
52 application_type 20000 non-null object
53 annual_inc_joint 2792 non-null float64
54 dti_joint 2792 non-null float64
55 verification_status_joint 2792 non-null object
56 acc_now_delinq 20000 non-null float64
57 tot_coll_amt 20000 non-null float64
58 tot_cur_bal 20000 non-null float64
59 open_acc_6m 20000 non-null float64
60 open_act_il 20000 non-null float64
61 open_il_12m 20000 non-null float64
62 open_il_24m 20000 non-null float64
63 mths_since_rcnt_il 19242 non-null float64
64 total_bal_il 20000 non-null float64
65 il_util 16740 non-null float64
66 open_rv_12m 20000 non-null float64
67 open_rv_24m 20000 non-null float64
68 max_bal_bc 20000 non-null float64
69 all_util 19994 non-null float64
70 total_rev_hi_lim 20000 non-null float64
71 inq_fi 20000 non-null float64
72 total_cu_tl 20000 non-null float64
73 inq_last_12m 20000 non-null float64
74 acc_open_past_24mths 20000 non-null float64
75 avg_cur_bal 19997 non-null float64
76 bc_open_to_buy 19653 non-null float64
77 bc_util 19646 non-null float64
78 chargeoff_within_12_mths 20000 non-null float64
79 delinq_amnt 20000 non-null float64
80 mo_sin_old_il_acct 19242 non-null float64
81 mo_sin_old_rev_tl_op 20000 non-null float64
82 mo_sin_rcnt_rev_tl_op 20000 non-null float64
83 mo_sin_rcnt_tl 20000 non-null float64
84 mort_acc 20000 non-null float64
85 mths_since_recent_bc 19672 non-null float64
86 mths_since_recent_bc_dlq 4076 non-null float64
87 mths_since_recent_inq 17495 non-null float64
88 mths_since_recent_revol_delinq 5889 non-null float64
89 num_accts_ever_120_pd 20000 non-null float64
90 num_actv_bc_tl 20000 non-null float64
91 num_actv_rev_tl 20000 non-null float64
92 num_bc_sats 20000 non-null float64
93 num_bc_tl 20000 non-null float64
94 num_il_tl 20000 non-null float64
95 num_op_rev_tl 20000 non-null float64
96 num_rev_accts 20000 non-null float64
97 num_rev_tl_bal_gt_0 20000 non-null float64
98 num_sats 20000 non-null float64
99 num_tl_120dpd_2m 18819 non-null float64
100 num_tl_30dpd 20000 non-null float64
101 num_tl_90g_dpd_24m 20000 non-null float64
102 num_tl_op_past_12m 20000 non-null float64
103 pct_tl_nvr_dlq 20000 non-null float64
104 percent_bc_gt_75 19651 non-null float64
105 pub_rec_bankruptcies 20000 non-null float64
106 tax_liens 20000 non-null float64
107 tot_hi_cred_lim 20000 non-null float64
108 total_bal_ex_mort 20000 non-null float64
109 total_bc_limit 20000 non-null float64
110 total_il_high_credit_limit 20000 non-null float64
111 revol_bal_joint 2792 non-null float64
112 sec_app_earliest_cr_line 2792 non-null object
113 sec_app_inq_last_6mths 2792 non-null float64
114 sec_app_mort_acc 2792 non-null float64
115 sec_app_open_acc 2792 non-null float64
116 sec_app_revol_util 2745 non-null float64
117 sec_app_open_act_il 2792 non-null float64
118 sec_app_num_rev_accts 2792 non-null float64
119 sec_app_chargeoff_within_12_mths 2792 non-null float64
120 sec_app_collections_12_mths_ex_med 2792 non-null float64
121 sec_app_mths_since_last_major_derog 998 non-null float64
122 hardship_flag 20000 non-null object
123 hardship_type 64 non-null object
124 hardship_reason 64 non-null object
125 hardship_status 64 non-null object
126 deferral_term 64 non-null float64
127 hardship_amount 64 non-null float64
128 hardship_start_date 64 non-null object
129 hardship_end_date 64 non-null object
130 payment_plan_start_date 64 non-null object
131 hardship_length 64 non-null float64
132 hardship_dpd 64 non-null float64
133 hardship_loan_status 64 non-null object
134 orig_projected_additional_accrued_interest 50 non-null float64
135 hardship_payoff_balance_amount 64 non-null float64
136 hardship_last_payment_amount 64 non-null float64
137 disbursement_method 20000 non-null object
138 debt_settlement_flag 20000 non-null object
139 debt_settlement_flag_date 61 non-null object
140 settlement_status 61 non-null object
141 settlement_date 61 non-null object
142 settlement_amount 61 non-null float64
143 settlement_percentage 61 non-null float64
144 settlement_term 61 non-null float64
dtypes: float64(106), int64(4), object(35)
memory usage: 22.1+ MB
# 데이터의 기초 통계량을 확인해보자
df.describe()

# 인덱스의 구성을 확인해보자.
# 데이터 프레임의 인덱스 구성을 보여준다.
# 날짜, 시간, 연도가 인덱스가 될 수 있다.
df.indexRangeIndex(start=0, stop=20000, step=1)
# 컬럼의 구성을 확인해보자.
df.columnsIndex(['id', 'member_id', 'loan_amnt', 'funded_amnt', 'funded_amnt_inv',
'term', 'int_rate', 'installment', 'grade', 'sub_grade',
...
'hardship_payoff_balance_amount', 'hardship_last_payment_amount',
'disbursement_method', 'debt_settlement_flag',
'debt_settlement_flag_date', 'settlement_status', 'settlement_date',
'settlement_amount', 'settlement_percentage', 'settlement_term'],
dtype='object', length=145)
# 데이터셋을 살펴 본 결과 정체를 알 수 없는 많은 컬럼이 있는 걸 확인했고,
20000개의 샘플이 불러들여진 것을 확인 할 수 있었습니다.
추가로 데이터 중간 중간 비어있는 값도 있는 것을 확인했습니다.
2.5 데이터접근 (인덱싱, 슬라이싱, 샘플링)
# 첫 샘플 혹은 레코드(대출건)에 대한 데이터를 살펴보겠습니다.
# 인덱스넘버로 데이터에 접근하는 .iloc[색인]
# 각 컬럼이나, 행단위 접근했을 때 출력되는 벡터 데이터를 Serise(시리즈) 라고 하는 자료구조
# index, values로 각각의 속성에 접근 가능
# index location
df.iloc[0]
>>> id NaN
member_id NaN
loan_amnt 15000
funded_amnt 10000
funded_amnt_inv 10000.0
...
settlement_status NaN
settlement_date NaN
settlement_amount NaN
settlement_percentage NaN
settlement_term NaN
Name: 0, Length: 145, dtype: object
df.iloc[0].index
>>> Index(['id', 'member_id', 'loan_amnt', 'funded_amnt', 'funded_amnt_inv',
'term', 'int_rate', 'installment', 'grade', 'sub_grade',
...
'hardship_payoff_balance_amount', 'hardship_last_payment_amount',
'disbursement_method', 'debt_settlement_flag',
'debt_settlement_flag_date', 'settlement_status', 'settlement_date',
'settlement_amount', 'settlement_percentage', 'settlement_term'],
dtype='object', length=145)
df.iloc[0].values
>>> array([nan, nan, 15000, 10000, 10000.0, ' 36 months', 9.44, 320.05, 'B',
'B1', 'mechanic', '6 years', 'MORTGAGE', 80000.0, 'Not Verified',
'Dec-2017', 'Current', 'n', nan, nan, 'credit_card',
'Credit card refinancing', '762xx', 'TX', 14.82, 0.0, 'Jul-2007',
0.0, 34.0, nan, 8.0, 0.0, 5225, 73.6, 30.0, 'w', 6442.28, 6442.28,
4493.81, 4493.81, 3557.72, 936.09, 0.0, 0.0, 0.0, 'Feb-2019',
320.05, 'Mar-2019', 'Feb-2019', 0.0, nan, 1, 'Individual', nan,
nan, nan, 0.0, 0.0, 173110.0, 0.0, 2.0, 0.0, 2.0, 23.0, 12496.0,
39.0, 0.0, 0.0, 3949.0, 45.0, 7100.0, 1.0, 0.0, 0.0, 2.0, 21639.0,
1875.0, 73.6, 0.0, 0.0, 125.0, 78.0, 26.0, 23.0, 3.0, 26.0, nan,
21.0, nan, 0.0, 2.0, 2.0, 4.0, 4.0, 21.0, 4.0, 5.0, 2.0, 8.0, 0.0,
0.0, 0.0, 0.0, 96.4, 25.0, 0.0, 0.0, 196130.0, 17756.0, 7100.0,
31992.0, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,
'N', nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,
nan, nan, 'Cash', 'N', nan, nan, nan, nan, nan, nan], dtype=object)
# .values 로 볼떄 배열로 값이 묶여있다, 따라서 브로드캐스팅으로 연산 가능할 것이다.
# 넘파이 어레이로 묶여 있으니까, 계산이 빠르겠구나
# 백터 형태로 나타나는 형태를 시리즈라고 부른다.
# 따라서 팬시 인덱싱 가능하다.
df.iloc[0].values == " 36 months"
>>> array([False, False, False, False, False, True, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False])
# 10번 인덱스 부터 20번 인덱스 샘플 접근
# start, end+1, step
df.iloc[10:21:2]

# 컬럼 단위 샘플 접근
df["grade"]
>>> 0 B
1 B
2 C
3 B
4 C
..
19995 B
19996 C
19997 C
19998 D
19999 D
Name: grade, Length: 20000, dtype: object
# 딕셔너리의 벨류 값 구할떄 사용하는 것과 매우 비슷하다. 데이터 접근시 딕셔너리 형태로 적응함
# df[텍스트형태의 컬럼명]
# 인덱싱이나 슬라이싱으로 데이터에 접근을 할 때 큰 단위를 선택하고 그 결과에서 인덱싱 혹은 슬라이싱을 하면
# 조금 더 편하게, 쉽게 데이터 접근이 가능하다.
# 여러 컬럼 동시 접근
df[["installment","grade","sub_grade"]]

# 컬럼을 리스트 형태로 만들어서 접근하여야 한다.
# 여기에 바로 컬럼 단위 샘플 접근 가능!
# df.loc[인덱스, 컬럼명]
# row와 columns을 동시에 슬라이싱 하는 속성
df.loc[10:20,["emp_title","emp_length"]]

# 스칼라값 하나에 접근
df.loc[0,"loan_amnt"]
>>> 15000
# loc가 조금 느리다. -> 데이터 포인트 스칼라 값에 접근할떄는 at이라는 함수가 훨씬 빠름
# df.loc[0,"loan_amnt"] = 40000 처럼 값을 새로 지정 가능
# df의 컬럼명을 순환하면서 컬럼단위로 접근하고 각 컬럼의 고유값을 출력해주는 코드
# 중복값 제거하고 데이터를 확인할 수 있다.
for col_nm in df.columns:
print(col_nm, df[col_nm].unique())
loan_amnt [10000 5000 14000 ... 31600 32825 37025]
funded_amnt [10000 5000 14000 ... 31600 32825 37025]
funded_amnt_inv [10000. 5000. 14000. ... 31600. 32825. 37025.]
term [' 36 months' ' 60 months']
int_rate [ 9.44 13.59 10.91 14.08 9.93 16.02 17.09 11.99 12.62 19.03 21.45 18.06
20. 6.08 10.42 15.05 6.72 7.97 5.32 7.35 23.88 29.69 30.17 28.72
22.91 25.82 26.3 24.85 30.79 30.65 6. 30.75 30.99 30.84 7.21 30.94
7.07 30.89]
installment [ 320.05 169.9 457.75 ... 1035.45 235.63 334.59]
grade ['B' 'C' 'D' 'A' 'E' 'F' 'G']
sub_grade ['B1' 'C2' 'B4' 'C3' 'B2' 'C5' 'D1' 'B5' 'C1' 'D3' 'D5' 'D2' 'D4' 'A2'
'B3' 'C4' 'A3' 'A5' 'A1' 'A4' 'E2' 'F2' 'F3' 'F1' 'E1' 'E4' 'E5' 'E3'
'G1' 'F4' 'F5' 'G5' 'G2' 'G4' 'G3']
emp_title ['mechanic' 'truck driver' 'confidential secretary' ...
'sr computer analyst' 'bus operator ' 'preauthorization specialist']
emp_length ['6 years' '10+ years' '2 years' '< 1 year' '1 year' '5 years' '4 years'
'3 years' '7 years' '8 years' '9 years']
home ['MORTGAGE' 'OWN' 'RENT']
annual_inc [ 80000. 168000. 39000. ... 34694.5 78374. 117200. ]
verification_status ['Not Verified' 'Source Verified' 'Verified']
issue_d ['Dec-2017' 'Nov-2017']
loan_status ['Current' 'In Grace Period' 'Fully Paid' 'Late (31-120 days)'
'Charged Off' 'Late (16-30 days)']
pymnt_plan ['n' 'y']
purpose ['credit_card' 'other' 'debt_consolidation' 'moving' 'home_improvement'
'major_purchase' 'car' 'medical' 'house' 'small_business' 'vacation'
'renewable_energy']
title ['Credit card refinancing' 'Other' 'Debt consolidation'
'Moving and relocation' 'Home improvement' 'Major purchase'
'Car financing' 'Medical expenses' 'Home buying' 'Business' 'Vacation'
'Green loan']
zip_code ['762xx' '788xx' '125xx' '672xx' '920xx' '750xx' '936xx' '765xx' '292xx'
'027xx' '010xx' '439xx' '635xx' '945xx' '585xx' '331xx' '394xx' '197xx'
'799xx' '770xx' '630xx' '301xx' '274xx' '791xx' '461xx' '912xx' '935xx'
'973xx' '458xx' '220xx' '333xx' '206xx' '631xx' '967xx' '080xx' '307xx'
'104xx' '801xx' '971xx' '166xx' '950xx' '970xx' '989xx' '550xx' '344xx'
'913xx' '226xx' '891xx' '705xx' '890xx' '146xx' '372xx' '914xx' '337xx'
'933xx' '853xx' '445xx' '462xx' '802xx' '164xx' '840xx' '365xx' '144xx'
'548xx' '956xx' '062xx' '341xx' '421xx' '940xx' '330xx' '120xx' '974xx'
'690xx' '560xx' '620xx' '577xx' '809xx' '483xx' '400xx' '014xx' '727xx'
'658xx' '660xx' '225xx' '113xx' '356xx' '347xx' '597xx' '773xx' '925xx'
'930xx' '370xx' '450xx' '327xx' '474xx' '142xx' '864xx' '277xx' '023xx'
'730xx' '806xx' '922xx' '300xx' '088xx' '995xx' '078xx' '224xx' '760xx'
'169xx' '968xx' '114xx' '383xx' '605xx' '766xx' '322xx' '731xx' '275xx'
'260xx' '117xx' '280xx' '020xx' '328xx' '953xx' '129xx' '423xx' '212xx'
'190xx' '320xx' '594xx' '403xx' '431xx' '312xx' '618xx' '452xx' '305xx'
'180xx' '959xx' '373xx' '381xx' '152xx' '871xx' '178xx' '302xx' '410xx'
'207xx' '480xx' '103xx' '751xx' '606xx' '350xx' '112xx' '906xx' '600xx'
'851xx' '276xx' '781xx' '706xx' '130xx' '647xx' '223xx' '287xx' '958xx'
'983xx' '290xx' '664xx' '495xx' '487xx' '278xx' '070xx' '535xx' '198xx'
'740xx' '786xx' '668xx' '800xx' '588xx' '325xx' '237xx' '441xx' '546xx'
'674xx' '296xx' '264xx' '460xx' '028xx' '442xx' '531xx' '335xx' '850xx'
'997xx' '928xx' '608xx' '939xx' '234xx' '065xx' '282xx' '601xx' '107xx'
'064xx' '211xx' '952xx' '761xx' '032xx' '395xx' '085xx' '173xx' '640xx'
'774xx' '100xx' '711xx' '947xx' '852xx' '087xx' '183xx' '972xx' '622xx'
'671xx' '232xx' '286xx' '655xx' '613xx' '017xx' '754xx' '943xx' '490xx'
'273xx' '329xx' '787xx' '214xx' '707xx' '151xx' '547xx' '446xx' '980xx'
'193xx' '917xx' '902xx' '303xx' '833xx' '941xx' '775xx' '757xx' '604xx'
'111xx' '030xx' '076xx' '110xx' '844xx' '021xx' '294xx' '298xx' '923xx'
'954xx' '549xx' '986xx' '492xx' '926xx' '310xx' '279xx' '553xx' '210xx'
'463xx' '175xx' '559xx' '073xx' '905xx' '703xx' '633xx' '040xx' '097xx'
'145xx' '736xx' '156xx' '907xx' '919xx' '721xx' '993xx' '584xx' '625xx'
'285xx' '484xx' '313xx' '215xx' '251xx' '067xx' '713xx' '948xx' '937xx'
'194xx' '673xx' '557xx' '921xx' '033xx' '752xx' '336xx' '283xx' '563xx'
'981xx' '532xx' '481xx' '262xx' '105xx' '018xx' '163xx' '680xx' '860xx'
'469xx' '931xx' '044xx' '900xx' '402xx' '946xx' '609xx' '379xx' '200xx'
'339xx' '334xx' '984xx' '060xx' '652xx' '195xx' '209xx' '831xx' '272xx'
'790xx' '397xx' '229xx' '909xx' '782xx' '034xx' '797xx' '066xx' '611xx'
'293xx' '486xx' '378xx' '323xx' '106xx' '128xx' '366xx' '148xx' '326xx'
'115xx' '346xx' '390xx' '191xx' '082xx' '321xx' '836xx' '432xx' '662xx'
'072xx' '805xx' '882xx' '657xx' '957xx' '238xx' '700xx' '342xx' '116xx'
'101xx' '247xx' '443xx' '063xx' '371xx' '170xx' '430xx' '894xx' '464xx'
'189xx' '804xx' '479xx' '951xx' '077xx' '482xx' '857xx' '451xx' '554xx'
'944xx' '456xx' '393xx' '737xx' '841xx' '324xx' '257xx' '898xx' '982xx'
'122xx' '468xx' '749xx' '254xx' '199xx' '109xx' '530xx' '793xx' '042xx'
'777xx' '641xx' '352xx' '453xx' '934xx' '846xx' '360xx' '675xx' '161xx'
'470xx' '985xx' '712xx' '685xx' '723xx' '544xx' '029xx' '244xx' '127xx'
'719xx' '924xx' '895xx' '859xx' '780xx' '134xx' '949xx' '404xx' '960xx'
'810xx' '038xx' '551xx' '996xx' '121xx' '656xx' '903xx' '602xx' '798xx'
'473xx' '543xx' '154xx' '016xx' '380xx' '386xx' '217xx' '614xx' '221xx'
'256xx' '309xx' '465xx' '581xx' '314xx' '815xx' '827xx' '231xx' '355xx'
'910xx' '387xx' '297xx' '785xx' '704xx' '648xx' '162xx' '681xx' '955xx'
'271xx' '208xx' '123xx' '636xx' '011xx' '368xx' '222xx' '281xx' '433xx'
'411xx' '216xx' '086xx' '391xx' '181xx' '069xx' '816xx' '591xx' '572xx'
'374xx' '304xx' '015xx' '645xx' '666xx' '932xx' '150xx' '201xx' '140xx'
'440xx' '068xx' '241xx' '592xx' '778xx' '138xx' '316xx' '603xx' '617xx'
'172xx' '541xx' '126xx' '720xx' '083xx' '252xx' '904xx' '596xx' '701xx'
'319xx' '494xx' '075xx' '035xx' '911xx' '437xx' '847xx' '012xx' '457xx'
'537xx' '351xx' '726xx' '444xx' '877xx' '153xx' '728xx' '024xx' '767xx'
'385xx' '586xx' '627xx' '171xx' '284xx' '496xx' '756xx' '534xx' '218xx'
'184xx' '186xx' '268xx' '196xx' '255xx' '908xx' '471xx' '634xx' '263xx'
'875xx' '288xx' '295xx' '863xx' '253xx' '050xx' '714xx' '396xx' '571xx'
'102xx' '607xx' '270xx' '228xx' '628xx' '803xx' '243xx' '811xx' '794xx'
'119xx' '610xx' '071xx' '054xx' '874xx' '689xx' '743xx' '358xx' '245xx'
'716xx' '990xx' '539xx' '768xx' '493xx' '741xx' '784xx' '405xx' '219xx'
'084xx' '623xx' '991xx' '037xx' '598xx' '665xx' '182xx' '061xx' '776xx'
'616xx' '139xx' '582xx' '661xx' '881xx' '454xx' '187xx' '759xx' '629xx'
'796xx' '338xx' '155xx' '832xx' '489xx' '448xx' '436xx' '306xx' '729xx'
'745xx' '389xx' '644xx' '873xx' '265xx' '074xx' '927xx' '249xx' '820xx'
'026xx' '722xx' '472xx' '755xx' '177xx' '724xx' '315xx' '425xx' '564xx'
'916xx' '349xx' '435xx' '179xx' '039xx' '915xx' '031xx' '612xx' '565xx'
'233xx' '573xx' '136xx' '354xx' '359xx' '843xx' '975xx' '159xx' '025xx'
'856xx' '763xx' '236xx' '992xx' '174xx' '626xx' '764xx' '051xx' '988xx'
'406xx' '361xx' '308xx' '837xx' '897xx' '599xx' '561xx' '108xx' '994xx'
'834xx' '049xx' '317xx' '168xx' '590xx' '769xx' '478xx' '738xx' '838xx'
'488xx' '176xx' '019xx' '048xx' '686xx' '587xx' '118xx' '744xx' '230xx'
'135xx' '497xx' '638xx' '808xx' '678xx' '132xx' '961xx' '977xx' '079xx'
'753xx' '779xx' '377xx' '558xx' '137xx' '147xx' '434xx' '670xx' '424xx'
'398xx' '235xx' '637xx' '046xx' '466xx' '812xx' '058xx' '814xx' '363xx'
'240xx' '883xx' '388xx' '467xx' '420xx' '289xx' '158xx' '485xx' '165xx'
'477xx' '047xx' '708xx' '417xx' '013xx' '157xx' '880xx' '669xx' '261xx'
'542xx' '227xx' '362xx' '242xx' '540xx' '188xx' '653xx' '870xx' '382xx'
'376xx' '491xx' '619xx' '684xx' '688xx' '498xx' '409xx' '036xx' '318xx'
'651xx' '667xx' '748xx' '575xx' '879xx' '081xx' '758xx' '384xx' '149xx'
'089xx' '422xx' '267xx' '291xx' '259xx' '718xx' '427xx' '855xx' '052xx'
'650xx' '415xx' '475xx' '646xx' '124xx' '133xx' '364xx' '056xx' '567xx'
'141xx' '045xx' '570xx' '677xx' '266xx' '248xx' '160xx' '499xx' '918xx'
'447xx' '057xx' '528xx' '053xx' '807xx' '476xx' '735xx' '538xx' '357xx'
'828xx' '683xx' '624xx' '734xx' '795xx' '783xx' '299xx' '414xx' '022xx'
'250xx' '824xx' '258xx' '098xx' '639xx' '449xx' '789xx' '131xx' '829xx'
'392xx' '710xx' '043xx' '401xx' '813xx' '998xx' '999xx' '615xx' '693xx'
'407xx' '976xx' '717xx' '239xx' '679xx' '438xx' '687xx' '978xx' '367xx'
'826xx' '835xx' '725xx' '143xx' '416xx' '455xx' '246xx' '865xx' '691xx'
'574xx' '746xx' '884xx' '167xx' '369xx' '332xx' '822xx' '556xx' '593xx'
'676xx' '566xx' '595xx' '583xx' '580xx' '041xx' '545xx' '830xx' '823xx'
'091xx' '562xx' '418xx' '747xx' '654xx' '412xx' '979xx' '525xx' '739xx'
'426xx' '772xx' '185xx' '825xx' '962xx' '845xx']
addr_state ['TX' 'NY' 'KS' 'CA' 'SC' 'MA' 'OH' 'MO' 'ND' 'FL' 'MS' 'DE' 'GA' 'NC'
'IN' 'OR' 'VA' 'MD' 'HI' 'NJ' 'CO' 'PA' 'WA' 'MN' 'NV' 'LA' 'TN' 'AZ'
'UT' 'AL' 'WI' 'CT' 'KY' 'NE' 'IL' 'SD' 'MI' 'AR' 'MT' 'OK' 'AK' 'WV'
'NM' 'RI' 'NH' 'ID' 'ME' 'WY' 'VT' 'DC']
dti [14.82 11.62 22.88 ... 35.03 47.73 43.84]
# 고윳값 갯수 출력
for col_nm in df.columns:
print(col_nm, df[col_nm].nunique())
loan_amnt 1205
funded_amnt 1205
funded_amnt_inv 1260
term 2
int_rate 38
installment 5550
grade 7
sub_grade 35
emp_title 14787
emp_length 11
home 3
annual_inc 3249
verification_status 3
issue_d 2
loan_status 6
pymnt_plan 2
purpose 12
title 12
zip_code 861
addr_state 50
dti 4686
2.6 팬시인덱싱
bool 형태의 array를 조건을 전달하여 다차원 배열을 인덱싱하는 방법.
조건식을 사용하여 분석에 필요한 데이터샘플을 추출하기 용이합니다.
# 신용등급이 A인 샘플의 emp_title 확인
df.loc[df["grade"] == 'A',"emp_title"].value_counts()
Manager 90
Teacher 72
Owner 68
Registered Nurse 40
Driver 36
..
Senior VP 1
Systems Development Engineer 1
Transfusion Services Supervisor 1
Sr Creative Fragrance Manager 1
Vice President/General Manager 1
Name: emp_title, Length: 2628, dtype: int64
# 대출금액평균
# 20000개 샘플 기준으로 대출금액의 평균이다.
df["loan_amnt"].mean()
>>> 15382.56875
# 조건식 샘플링 emp_title 이 ceo인 샘플들?
df[df["emp_title"] == "ceo"]
# ceo인 사람들의 annual income을 구해보자
df.loc[df["emp_title"] == "ceo", "annual_inc"].mean()
>>> 265000.0
# 그럼 ceo 아닌 사람의 annual income은?
df.loc[df["emp_title"] != "ceo", "annual_inc"].mean()
>>> 78410.60469146915
# 신용등급 A와 B인 샘플접근
# 조건식을 여러개 써야 한다면 조건마다 ()로 감싸주시는 것이 좋다.
# 조건식에 \ & 처럼 기호를 써야한다.
(df["grade"] == 'A') | (df["grade"] == 'B')
df.loc[(df["grade"] == 'A') | (df["grade"] == 'B')]
# df loan_amnt 컬럼값이 10000이상인 채권샘플의 grade 갯수세기
df.loc[df["loan_amnt"] >= 10000, "grade"].value_counts()
B 4201
C 3782
A 2799
D 2169
E 583
F 135
G 32
Name: grade, dtype: int64
# df grade C 와 D 인 채권샘플 annual_inc 최대값인 인덱스 빼오기 (idxmax)
# 최대값 인덱스 빼와서 샘플까지 출력
# take( ) 은 언급된 축과 인덱스를 따라 배열에서 요소를 반환하는 데 사용되는 함수이다.
df.take([df.loc[(df["grade"] == 'C') | (df["grade"] == 'D')]["annual_inc"].idxmax()])


# 연봉이 6500000달러 가 나온다! -> 뭔가 이상하다. 데이터가 정확한 건지 판단해야함
# 컬럼 내 문자열 내에 우리가 찾고싶은 문자열이 포함되어 있는지를 기준으로 샘플링
# 이커머스 에서 많이 쓰임 브랜드, 상품명 등등
df.loc[df["purpose"].str.contains("debt")]

# purpose에 debt가 있는 값만 추출하였음을 확인가능!
3. 데이터프레임 병합
실제 분석업무를 진행하다보면 데이터가 여기저기 분산되어 있을 경우가 더 많다.
조각난 데이터를 분석에 필요한 데이터셋으로 만들기 위해 데이터프레임 병합을 많이 사용한다.
한개 이상의 데이터프레임을 병합 할 때 주로 사용하는 함수 2가지를 알아보자.
3.1 데이터 병합에 사용가능한 key(병합할 기준이 되는 행 or 열)값이 있는경우
pd.merge(베이스데이터프레임, 병합할데이터프레임)
사용 가능 한 파라메터
- how : 'left', 'right', 'inner', 'outer'
- left_on : key값이 다를 경우 베이스데이터프레임의 key 설정
- right_on : key값이 다를 경우 병합데이터프레임의 key 설정
3.2 단순 데이터 연결
pd.concat([베이스데이터프레임, 병합할데이터프레임], axis=0 or 1)
사용 가능 한 파라메터
- axis : 축 방향 설정
3.3 merge 예시
merge_df1 = pd.DataFrame({
'이름': ['원영', '사쿠라', '유리', '예나', '유진', '나코', '은비', '혜원', '히토미', '채원', '민주', '째욘'],
'국어': [100, 70, 70, 70, 60, 90, 90, 70, 70, 80, 100, 100],
'영어': [100, 90, 80, 50, 70, 100, 70, 90, 100, 100, 80, 100]
}, columns=['이름', '국어', '영어'])
merge_df2 = pd.DataFrame({
'일어': [80, 100, 100, 90, 70, 50, 100],
'수학': [90, 70, 100, 80, 70, 80, 90],
'이름': ['원영', '사쿠라', '나코', '히토미', '예나', '은비', '째욘'],
}, columns=['일어', '수학', '이름'])
merge_df1

merge_df2
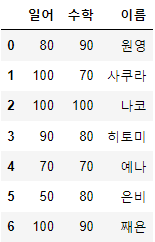
# 병합 테스트
merged_df = pd.merge(merge_df1, merge_df2)
merged_df

# pd.merge(merge_df1 (베이스데이터프레임), merge_df2 (병합할데이터프레임), 'left', 'right', 'inner', 'outer' )
# how = 'left', 'right', 'inner', 'outer'
# 'inner' 양쪽에 데이터 모두 있을 경우 (디폴트 값이다.)
# 'outer' 모든 데이터 합치기, 없는 값은 결측치, 한쪽에만 데이터가 있어도 병합
# 'left' 왼쪽에 있는 merge_df1 기준으로 합친다. 즉, 전달하는 데이터 프레임 기준으로
# 'right' 오른쪽에 있는 merge_df2 기준으로 합친다.
# 여기서 예시 중에서 merge_df2의 '이름'을 'name'이라고 바꿔보자
merge_df1 = pd.DataFrame({
'이름': ['원영', '사쿠라', '유리', '예나', '유진', '나코', '은비', '혜원', '히토미', '채원', '민주', '째욘'],
'국어': [100, 70, 70, 70, 60, 90, 90, 70, 70, 80, 100, 100],
'영어': [100, 90, 80, 50, 70, 100, 70, 90, 100, 100, 80, 100]
}, columns=['이름', '국어', '영어'])
merge_df2 = pd.DataFrame({
'일어': [80, 100, 100, 90, 70, 50, 100],
'수학': [90, 70, 100, 80, 70, 80, 90],
'name': ['원영', '사쿠라', '나코', '히토미', '예나', '은비', '째욘'],
}, columns=['일어', '수학', 'name'])
# merge_df1 와 merge_df2가 공통된 콜럼이 없다. 그럼 pd.merge()를 그냥 사용하면,
No common columns to perform merge on 이라고 에러가 난다.
그러므로 left_on='이름' ,right_on='name' 이렇게 공통 컬럼을 설정 해야한다.
즉, 공통된 콜롬이 없으면, 두개의 콜롬을 선정해야 한다.
merged_df = pd.merge(merge_df1, merge_df2, left_on='이름',right_on='name',how="outer")
merged_df

3.4 concat 예시
현재 df에 저장되어있는 데이터에 추가로 2만개의 데이터를 이어붙여보자.
df1이라는 변수에 이어붙일 데이터를 불러들여 병합을 진행해보자.
# df1 변수에 loan2.csv 파일을 읽어들입니다.
df1 = pd.read_csv("C:/Users/JIN SEONG EUN/Desktop/빅데이터 분석가 과정/SeSAC/data/loan2.csv")
# 데이터프레임 확인
df1.head()

# df 와 df1 shape 확인
df.shape, df1.shape((20000, 145), (20000, 145))
# 컬럼 갯수 동일
# 데이터프레임 행단위 병합
# axis = 1, 열방향
concat_df = pd.concat([df,df1])
concat_df

# 병합 데이터프레임 shape 확인
concat_df.shape
>>> (40000, 145)
# 병합 데이터프레임 index 확인
concat_df.indexInt64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8,
9,
...
19990, 19991, 19992, 19993, 19994, 19995, 19996, 19997, 19998,
19999],
dtype='int64', length=40000)
# 4만개 인데 19999값을 가짐 --> 인덱스가 섞임!
# concat 할때 인덱스가 섞였다!
4. 인덱스 편집
방금 전 concat으로 병합한 데이터프레임의 이상한 점을 찾았나?
데이터 자체는 잘 붙였지만 인덱스가 꼬여있었다.
인덱스 편집은 데이터분석을 위해 필요한 인덱스를 설정하기 위해 필요하다.
# 인덱스리셋
concat_df.reset_index(drop=True, inplace= True)
# 기존에 인덱스가 컬럼으로 들어오게 됨
# drop = True 파라매터 사용으로 인덱스 버릴 수 있다.
# inplace= True 파라매터 원본값을 새로 저장한다. 작업결과를 원본 결과에 적용
concat_df

# 인덱스 깔끔해진 것 을 확인 할 수 있다!
# 기존 컬럼값을 취해 index로 사용하려면?
concat_df.set_index("id")
# set_index() 함수를통해서 기존 컬럼 값을 인덱스로 사용

5. 컬럼편집
인덱스편집과 마찬가지로 데이터프레임의 컬럼을 변경해야 할 경우도 있다.
데이터프레임은 컬럼단위 샘플링 및 인덱싱, 이름변경이 가능하다.
5.1 컬럼선택
# df 컬럼명 접근
concat_df.columnsIndex(['id', 'member_id', 'loan_amnt', 'funded_amnt', 'funded_amnt_inv',
'term', 'int_rate', 'installment', 'grade', 'sub_grade',
...
'hardship_payoff_balance_amount', 'hardship_last_payment_amount',
'disbursement_method', 'debt_settlement_flag',
'debt_settlement_flag_date', 'settlement_status', 'settlement_date',
'settlement_amount', 'settlement_percentage', 'settlement_term'],
dtype='object', length=145)
# columns 속성도 인덱싱 및 슬라이싱이 가능합니다.
concat_df.columns[0:7]Index(['id', 'member_id', 'loan_amnt', 'funded_amnt', 'funded_amnt_inv',
'term', 'int_rate'],
dtype='object')
# 개인정보에 관한 부분에 관심이 많다.
# 데이터셋 중 필요한 부분만을 컬럼단위로 추려보자!
concat_df

# 145 colums 이다.
# df의 개인정보에 관한 컬럼만을 색인으로 df를 슬라이싱하고 person_df 변수에 할당
total_df = concat_df[concat_df.columns[0:25]] # 원하는 컬럼까지 보여줌
total_df

# 25 columns로 바뀐 것을 확인 할 수 있다!
5.2 컬럼삭제
현재 데이터셋에는 개인식별정보가 지워져서 데이터가 존재하지 않는다.
불필요한 데이터 column을 지우자!
# 지울 column의 데이터값이 모두 NaN인지 확인
total_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 40000 entries, 0 to 39999
Data columns (total 25 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 0 non-null float64
1 member_id 0 non-null float64
2 loan_amnt 40000 non-null int64
3 funded_amnt 40000 non-null int64
4 funded_amnt_inv 40000 non-null float64
5 term 40000 non-null object
6 int_rate 40000 non-null float64
7 installment 40000 non-null float64
8 grade 40000 non-null object
9 sub_grade 40000 non-null object
10 emp_title 36620 non-null object
11 emp_length 36665 non-null object
12 home_ownership 40000 non-null object
13 annual_inc 40000 non-null float64
14 verification_status 40000 non-null object
15 issue_d 40000 non-null object
16 loan_status 40000 non-null object
17 pymnt_plan 40000 non-null object
18 url 0 non-null float64
19 desc 0 non-null float64
20 purpose 40000 non-null object
21 title 40000 non-null object
22 zip_code 40000 non-null object
23 addr_state 40000 non-null object
24 dti 39921 non-null float64
dtypes: float64(9), int64(2), object(14)
memory usage: 7.6+ MB
# id, member_id, url, desc 를 삭제해야함을 알 수 있다.
# 지울 column의 데이터값이 모두 NaN인지 확인하는 다른 방법
# isna() / all()을 사용
total_df["desc"].isna().all()
>>> True
# all() 데이터가 모두 nun여야 True
# 삭제할 컬럼 모두 데이터가 없는 것을 확인했다.
# 컬럼 삭제 (drop, del, pop)
total_df.drop("id", axis=1, inplace=True) # axis =1 열방향
total_df.drop("member_id", axis=1, inplace=True) # axis =1 열방향
total_df.pop("url") # pop 은 아예 데이터프레임에서 아예 삭제한다.
total_df.pop("desc")
total_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 40000 entries, 0 to 39999
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 loan_amnt 40000 non-null int64
1 funded_amnt 40000 non-null int64
2 funded_amnt_inv 40000 non-null float64
3 term 40000 non-null object
4 int_rate 40000 non-null float64
5 installment 40000 non-null float64
6 grade 40000 non-null object
7 sub_grade 40000 non-null object
8 emp_title 36620 non-null object
9 emp_length 36665 non-null object
10 home_ownership 40000 non-null object
11 annual_inc 40000 non-null float64
12 verification_status 40000 non-null object
13 issue_d 40000 non-null object
14 loan_status 40000 non-null object
15 pymnt_plan 40000 non-null object
16 purpose 40000 non-null object
17 title 40000 non-null object
18 zip_code 40000 non-null object
19 addr_state 40000 non-null object
20 dti 39921 non-null float64
dtypes: float64(5), int64(2), object(14)
memory usage: 6.4+ MB
5.3 컬럼명 변경
경우에 따라서는 데이터셋 제작 중 컬럼명을 변경해야 할 경우도 있다.
국내 수집 데이터 사용 시 컬럼이 한글일 경우 영어로 변경을 많이 한다.
# 한글도 가능합니다만 권장하지는 않는다.
# 날짜 인덱스의 경우 axis =1 을 제외하고 작업 가능하다.
# home_ownership을 간략하게 home으로 변경
total_df.rename({"home_ownership":"home"}, axis=1, inplace= True)

# home 으로 콜롬이 변경됨을 확인 할 수 있다.
6. 데이터 샘플링 및 분석
데이터병합, 인덱스편집, 컬럼선택만으로도 불필요한 정보를 삭제하고 새롭게 데이터셋을 만들 수 있는것을 확인했다.
위에 학습한 내용도 데이터 샘플링에 속한 내용이지만,
지금부터는 데이터셋의 데이터를 살펴보면서 의미있는 데이터를 추려보도록 하자.
데이터프레임의 기본적인 인덱싱, 슬라이싱, 조건부 샘플링을 조합하면 데이터의 샘플을 확인 하는 과정만으로도 데이터분석이 가능해진다.
# 분석에 필요한 데이터프레임을 만들었으니 원본값으로 사용하자.
# 기존 df에 total_df 값을 덮어 씌웁니다.
df = total_df
# 분석에 필요한 데이터셋을 생성했다면 파일로도 저장 하자.
df.to_csv("./data/total_df.csv", index = False)
# index = Fasle 쓰잘대기 없는거 제거
6.1 채권자의 개인정보에 관심이 많다. 고객의 직업을 살펴보자.
# emp_title 접근
df["emp_title"]0 mechanic
1 NaN
2 Truck driver
3 Confidential Secretary
4 General Manager
...
39995 Nursing Assistant
39996 Machinist
39997 NaN
39998 Pharmacy technician
39999 Registered Nurse
Name: emp_title, Length: 40000, dtype: object
# 값을 카운트 하는 함수 value_counts() 을 이용하자.
df["emp_title"].value_counts().head(20)Teacher 707
Manager 691
Owner 664
Driver 345
Registered Nurse 290
Sales 283
Supervisor 277
RN 259
owner 215
Project Manager 181
Director 180
General Manager 167
President 163
Office Manager 146
Engineer 126
Nurse 122
manager 118
Sales Manager 117
Administrative Assistant 111
Truck Driver 106
Name: emp_title, dtype: int64
# 대소문자 구분이 안되어 있다.
# 데이터 분석시에 노이즈 발생한다.
# 처리가 필요하다.
6.2 데이터프레임 형변환
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 40000 entries, 0 to 39999
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 loan_amnt 40000 non-null int64
1 funded_amnt 40000 non-null int64
2 funded_amnt_inv 40000 non-null float64
3 term 40000 non-null object
4 int_rate 40000 non-null float64
5 installment 40000 non-null float64
6 grade 40000 non-null object
7 sub_grade 40000 non-null object
8 emp_title 36620 non-null object
9 emp_length 36665 non-null object
10 home 40000 non-null object
11 annual_inc 40000 non-null float64
12 verification_status 40000 non-null object
13 issue_d 40000 non-null object
14 loan_status 40000 non-null object
15 pymnt_plan 40000 non-null object
16 purpose 40000 non-null object
17 title 40000 non-null object
18 zip_code 40000 non-null object
19 addr_state 40000 non-null object
20 dti 39921 non-null float64
dtypes: float64(5), int64(2), object(14)
memory usage: 6.4+ MB
# emp_title에 문제가 있다.
# Owner, owner 같은 직업이지만 대소문자 구분에 따라 다른 값으로 취급되는 문제가 있다.
# 대소문자 구분을 없애기 위해 모두 소문자로 데이터값을 변경하자.
# 소문자 변환 전 혹시모를 int, float 데이터가 있을지 모를 상황에 대비해서 모두 문자열로 변경해주자.
# 형변환 함수 astype(데이터타입)을 이용하자.
df["emp_title"] = df["emp_title"].astype(str)
# 반복문을 사용한 데이터 변경도 가능
# 하지만 파이썬의 강점을 살리지 못한 코드
# 문자열 함수 : upper(), lower(), capitalize() 대문자, 소문자, 첫 알파벳만 대문자
for index, item in enumerate(df["emp_title"]):
df.at[index, "emp_title"] = item.lower()df["emp_title"]0 mechanic
1 nan
2 truck driver
3 confidential secretary
4 general manager
...
39995 nursing assistant
39996 machinist
39997 nan
39998 pharmacy technician
39999 registered nurse
Name: emp_title, Length: 40000, dtype: object
6.3 배운사람들의 코드, 고오급 python 스킬
numpy를 학습하면서 브로드캐스팅에 관하여 잠깐 언급했다.
그렇다면 그 파워풀하다던 브로드캐스팅은 어떻게 사용해야할까?
기타 언어에서는 지원하지 않는 기능이니만큼 파이썬의 특징을 가장 잘 살리는 코드
apply 함수를 사용하여 인자로 받는 모든 데이터에 함수를 적용
6.3.1 apply 함수로 컬럼에 적용시키는 코드 구조
df['컬럼명'] = df['컬럼명'].apply(lambda x: func(x) if 조건문)
df['컬럼명'] = df['컬럼명'].apply(func_nm)
# 대문자 만드는 함수를 만들자.
def make_upper(x):
return x.upper()make_upper("apple")
>>> 'APPLE'
# apply() 함수사용 반복이 가능한 데이터구조의 모든 인자에 적용
# lambda 각 인자에 적용할 함수 혹은 apply 로 함수를 브로드캐스팅 시키듯이 계산할 수 있음.
# lambda 는 한번 쓰고 버리는 형태로 만들 수 있음
df["emp_title"] = df["emp_title"].apply(make_upper)
df["emp_title"].value_counts().head(20)
>>>
NAN 3380
OWNER 921
MANAGER 845
TEACHER 812
DRIVER 433
REGISTERED NURSE 374
SALES 364
SUPERVISOR 352
RN 291
TRUCK DRIVER 254
GENERAL MANAGER 221
PROJECT MANAGER 204
OFFICE MANAGER 203
DIRECTOR 190
PRESIDENT 190
SALES MANAGER 148
NURSE 146
ENGINEER 145
OPERATIONS MANAGER 127
SERVER 126
Name: emp_title, dtype: int64
df["emp_title"] = df["emp_title"].apply(lambda x: x.lower())
df["emp_title"].value_counts().head(20)
>>>
nan 3380
owner 921
manager 845
teacher 812
driver 433
registered nurse 374
sales 364
supervisor 352
rn 291
truck driver 254
general manager 221
project manager 204
office manager 203
director 190
president 190
sales manager 148
nurse 146
engineer 145
operations manager 127
server 126
Name: emp_title, dtype: int64
# 번외 owner인 사람들 샘플링
df[df["emp_title"] == "owner"]
# 샘플링 된 데이터프레임의 단일 컬럼 접근
df[df["emp_title"] == "owner"]["annual_inc"]
>>> 58 55000.0
176 6000.0
327 72000.0
354 42000.0
362 70000.0
...
39612 72440.0
39692 52000.0
39724 20000.0
39815 55000.0
39954 75000.0
Name: annual_inc, Length: 921, dtype: float64
# 컬럼 평균값 계산
df[df["emp_title"] == "owner"]["annual_inc"].mean()
df.loc[df["emp_title"] == "owner","annual_inc"].mean()
>>>
88974.81923995657
# 코드 하나 변경으로 간단한 분석 가능
# owner가 아닌 사람들의 평균
df[df["emp_title"] != "owner"]["annual_inc"].mean()
df.loc[df["emp_title"] != "owner","annual_inc"].mean()
>>>
77901.53394534143
7. 데이터 재구조화
데이터 분석을 위해서는 데이터셋 내에 빈 값이 있는 경우 분석에 방해가 될 수 있는 여지가 많다.
모든 결측치를 없애야 하는 것은 아니지만 되도록이면 결측치를 채우는 방법,
혹은 없애는 방법등으로 결측치를 처리한다.
몇가지 예시를 살펴보면서 결측치 처리에 대해 알아보자.
# info() 함수는 결측치에 대한 정보도 보여줍니다.
# 컬럼별 isnull() 함수를 사용해도 무방합니다.
df.info()
>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 40000 entries, 0 to 39999
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 loan_amnt 40000 non-null int64
1 funded_amnt 40000 non-null int64
2 funded_amnt_inv 40000 non-null float64
3 term 40000 non-null object
4 int_rate 40000 non-null float64
5 installment 40000 non-null float64
6 grade 40000 non-null object
7 sub_grade 40000 non-null object
8 emp_title 40000 non-null object
9 emp_length 36665 non-null object
10 home 40000 non-null object
11 annual_inc 40000 non-null float64
12 verification_status 40000 non-null object
13 issue_d 40000 non-null object
14 loan_status 40000 non-null object
15 pymnt_plan 40000 non-null object
16 purpose 40000 non-null object
17 title 40000 non-null object
18 zip_code 40000 non-null object
19 addr_state 40000 non-null object
20 dti 39921 non-null float64
dtypes: float64(5), int64(2), object(14)
memory usage: 6.4+ MB
# 확인결과 emp_title, emp_length, dti에 결측치가 존재한다.
# emp_title은 non값을 전부 문자열 처리했기 때문에 결측치가 없는 것처럼 보인 것이다.
# 해당 컬럼의 결측치 샘플들을 살펴보고 결측치를 처리해보자.
# 컬럼별 결측치 확인을 위한 isnull()함수
# 리턴값이 bool 형태로 반환되어 조건부 샘플링이 가능하다.
df["dti"].isna()
>>>
0 False
1 False
2 False
3 False
4 False
...
39995 False
39996 False
39997 False
39998 False
39999 False
Name: dti, Length: 40000, dtype: bool
df["dti"].isna().sum()
>>> 79
(df["dti"].isna().sum() / len(df)) * 100
>>> 0.1975
# 직업과 근속연수에 관한 부분은 데이터를 통한 유추나 계산값을 통해 채워넣을 수 있는 항목은 아니다.
# 다만 dti의 경우 실수로 채워져 있는 부분이니 수업을 위해 평균값 혹은 근사치를 계산하여 채워보도록 하자.
# 즉, 갯수가 얼마 안되고, 평균값에 영향을 안준다. 따라서 평균값으로 nun값을 대체 한다.
8.1 결측치 채우기
# dti 컬럼의 NaN값 index 확인
# fillna() 함수로 NaN 값을 dti 컬럼의 평균으로 채우기
# fillna() 함수의 다양한 채우기 방법 파라메터 확인해보기
df["dti"].fillna(df["dti"].mean(), inplace= True)
# fillna() 함수의 다양한 채우기 방법 파라메터 확인해보기
df['dti'].fillna(method='bfill', inplace=True).fillna(method='ffill', inplace=True)
df.info()
>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 40000 entries, 0 to 39999
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 loan_amnt 40000 non-null int64
1 funded_amnt 40000 non-null int64
2 funded_amnt_inv 40000 non-null float64
3 term 40000 non-null object
4 int_rate 40000 non-null float64
5 installment 40000 non-null float64
6 grade 40000 non-null object
7 sub_grade 40000 non-null object
8 emp_title 40000 non-null object
9 emp_length 36665 non-null object
10 home 40000 non-null object
11 annual_inc 40000 non-null float64
12 verification_status 40000 non-null object
13 issue_d 40000 non-null object
14 loan_status 40000 non-null object
15 pymnt_plan 40000 non-null object
16 purpose 40000 non-null object
17 title 40000 non-null object
18 zip_code 40000 non-null object
19 addr_state 40000 non-null object
20 dti 40000 non-null float64
dtypes: float64(5), int64(2), object(14)
memory usage: 6.4+ MB
# dti의 non 값이 없어짐을 확인 할 수 있다.
8.2 결측치 제거
# emp_title 결측치가 있는 샘플 확인
df.loc[df['emp_length'].isna()]
# view값으로 dropna 결과값 확인
df.dropna(inplace=True)
# 결측치 제거
df.info()
>>> <class 'pandas.core.frame.DataFrame'>
Int64Index: 36665 entries, 0 to 39999
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 loan_amnt 36665 non-null int64
1 funded_amnt 36665 non-null int64
2 funded_amnt_inv 36665 non-null float64
3 term 36665 non-null object
4 int_rate 36665 non-null float64
5 installment 36665 non-null float64
6 grade 36665 non-null object
7 sub_grade 36665 non-null object
8 emp_title 36665 non-null object
9 emp_length 36665 non-null object
10 home 36665 non-null object
11 annual_inc 36665 non-null float64
12 verification_status 36665 non-null object
13 issue_d 36665 non-null object
14 loan_status 36665 non-null object
15 pymnt_plan 36665 non-null object
16 purpose 36665 non-null object
17 title 36665 non-null object
18 zip_code 36665 non-null object
19 addr_state 36665 non-null object
20 dti 36665 non-null float64
dtypes: float64(5), int64(2), object(14)
memory usage: 6.2+ MB
# 결측치가 모두 제거된 것을 볼 수 있다.
'Python > Data Analysis Library' 카테고리의 다른 글
| 03. Package visualization (0) | 2022.07.28 |
|---|---|
| Pandas_ex (연습문제) (0) | 2022.07.27 |
| 01. Package_Numpy (0) | 2022.07.25 |
| Part03 Chapter.02 데이터 분석 라이브러리 09. seaborn plots (실습) (0) | 2022.07.24 |
| Part03 Chapter.02 데이터 분석 라이브러리 08 pyplot 기초 (실습) (0) | 2022.07.24 |



