Ecommerce Purchases Exercise
아마존 구매 내역에 대한 Fake 데이터 입니다. 아래 굵은 글씨로 기술된 테스크들을 완수하자.
뒷부분으로 갈 수록 점점 어려워진다.
모든 데이터는 인위적으로 만들어진 가짜이므로 상식적으로 맞지 않을 수 있다는 점 감안하자.
또한 모든 답안은 한 줄로 작성될 수 있다는 점도 기억하자.
import numpy as np
import pandas as pd
1. csv 파일을 읽어들여 df 데이터프레임생성
# 결과값 없음
정답
df = pd.read_csv("경로")
2. 데이터프레임의 첫 5 샘플 확인
정답
df.head()
3. 몇개의 row와 column을 가진 데이터인가?
(10000, 14)
정답
df.shape
3. 데이터 프레임의 대략적인 정보도 확인해봅니다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Address 10000 non-null object
1 Lot 10000 non-null object
2 AM or PM 10000 non-null object
3 Browser Info 10000 non-null object
4 Company 10000 non-null object
5 Credit Card 10000 non-null int64
6 CC Exp Date 10000 non-null object
7 CC Security Code 10000 non-null int64
8 CC Provider 10000 non-null object
9 Email 10000 non-null object
10 Job 10000 non-null object
11 IP Address 10000 non-null object
12 Language 10000 non-null object
13 Purchase Price 10000 non-null float64
dtypes: float64(1), int64(2), object(11)
memory usage: 1.1+ MB
정답
df.info()
4. Purchase Price 컬럼의 평균은 몇인가?
50.34730200000025
정답
df["Purchase Price"].mean()
5. Purchase prices 컬럼의 최대값과 최소값은 무엇인가?
99.989999999999995
정답
df["Purchase Price"].max()
0.0
정답
df["Purchase Price"].min()
6. 사용자 중 영어를 사용하는 사람의 수는 몇인가? Hint- len()
1098
정답
# 본인 정답
eng = df[df["Language"] == "en"]
len(eng)
# 선생님 해설
len(df[df['Language'] == 'en'])
7. 직업이 "Lawyer" 인 사람은 몇명인가?
30
정답
# 본인
lawyer = df[df["Job"] == "Lawyer"]
len(lawyer)
# 선생님
(df['Job'] == 'Lawyer').sum()
8. 오전과 오후에 얼마나 많은 사람들이 주문을 하나? Hint:value_counts()
PM 5068
AM 4932
Name: AM or PM, dtype: int64
정답
df["AM or PM"].value_counts()
9. 가장 많은 직업을 순서대로 5가지 나열해봅시다
Interior and spatial designer 31
Lawyer 30
Social researcher 28
Purchasing manager 27
Designer, jewellery 27
Name: Job, dtype: int64
정답
df['Job'].value_counts().head()
8. 카드 번호 4926535242672853 인 고객의 email은?
1234 bondellen@williams-garza.com
Name: Email, dtype: object
정답
df.loc[df["Credit Card"] == 4926535242672853,"Email" ]
9. (어려움)American Express를 사용해서 95달러 이상 주문한 거래내역 확인
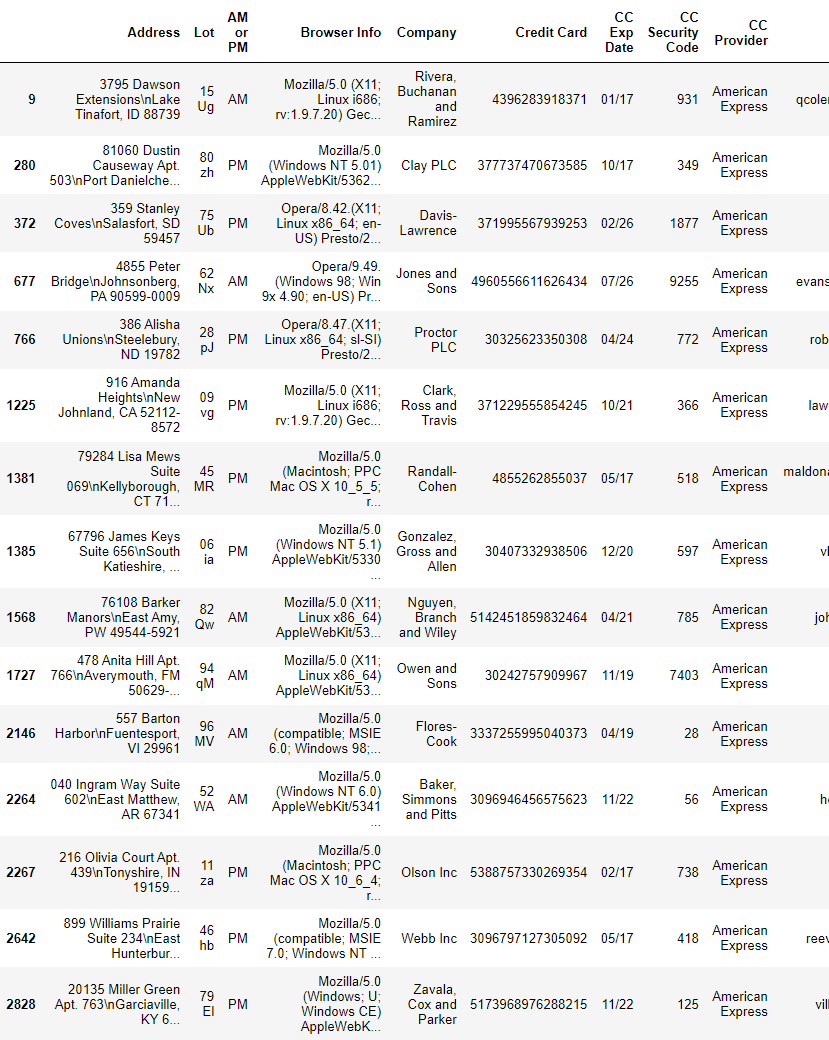
# 표 더 이어지지만 분량 관계상 여기까지 올림
정답
# 본인
df[(df["CC Provider"] == "American Express") & (df["Purchase Price"] >= 95)]
# 선생님
df.loc[(df['CC Provider'] == 'American Express') & (df['Purchase Price'] >= 95)]
10. 구매자의 사용언어에 따라 총 구매금액을 구하시오
Language
el 58618.44
de 58043.93
ru 57665.84
pt 57258.98
en 56111.11
it 54301.09
fr 54275.96
es 54056.84
zh 53140.83
Name: Purchase Price, dtype: float64
정답
df.groupby('Language').sum()['Purchase Price'].sort_values(ascending=False)
11. 오전과 오후에 주문한 총 구매금액을 구하시오
AM or PM
AM 247519.87
PM 255953.15
Name: Purchase Price, dtype: float64
정답
df.groupby('AM or PM').sum()['Purchase Price']
12. 평균 구매금액이 큰 상위 10개 직업을 출력하시오
Job
Trade mark attorney 73.802727
Translator 70.777647
Investment analyst 69.090000
Accountant, chartered management 69.082667
Designer, industrial/product 68.714667
Clinical cytogeneticist 67.996364
Psychologist, prison and probation services 67.767222
Special effects artist 66.752857
Politician's assistant 66.106923
Advertising account planner 66.034286
Name: Purchase Price, dtype: float64
정답
df.groupby("Job").mean()["Purchase Price"].sort_values(ascending=False).head(10)
13. 카드사별 오전과 오후 구매금액 평균을 구하시오
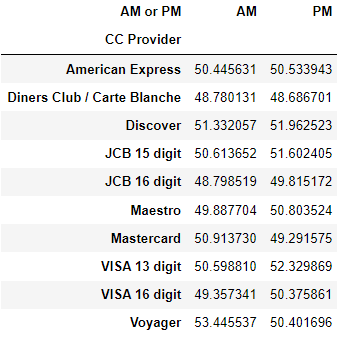
정답
pd.pivot_table(data=df, columns="AM or PM",index="CC Provider",values ="Purchase Price")
14. 아파트 거주 고객의 직업별 총 구매내역
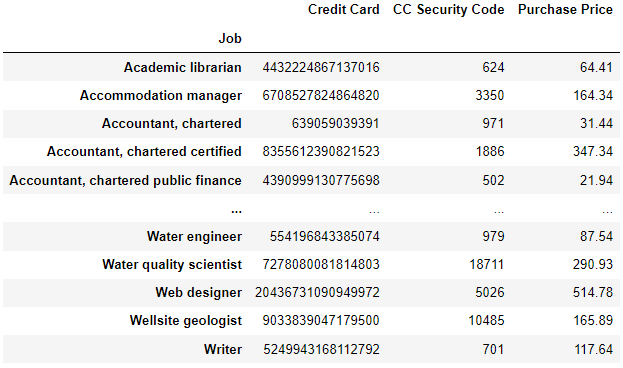
정답
Apt = df[df["Address"].str.contains("Apt")]
pd.pivot_table(data=Apt, values=["CC Security Code","Credit Card","Purchase Price"],index="Job",aggfunc="sum")'Python > Data Analysis Library' 카테고리의 다른 글
| 03. Package visualization (0) | 2022.07.28 |
|---|---|
| 02. Package pandas finance (0) | 2022.07.27 |
| 01. Package_Numpy (0) | 2022.07.25 |
| Part03 Chapter.02 데이터 분석 라이브러리 09. seaborn plots (실습) (0) | 2022.07.24 |
| Part03 Chapter.02 데이터 분석 라이브러리 08 pyplot 기초 (실습) (0) | 2022.07.24 |



